Practical 시리즈는 AWS 환경 위에서 데이터 인프라를 구축하는데 참고할만한 내용들을 담고 있습니다. 이 글은 그 중 Practical Spark 의 한 챕터입니다.이번 챕터에서는 Spark 의 Version 별 변천사에 대해 알아봅니다. 버전이 올라가면서 개선된, 그리고 신규로 추가된 기능들에 대해 알아봅니다. 마지막 섹션에서는 Spark 의 성능을 좌우하는 Shuffle 을 외부 서비스를 이용해 수행하는 External Shuffle Service 에 대해서도 논의합니다.

Practical 시리즈는 AWS 환경 위에서 데이터 인프라를 구축하는데 참고할만한 내용들을 담고 있습니다. 아래의 내용들을 주로 다룹니다.
- Practical Spark
- Practical Kafka
- Practical Kubernetes
- Practical AWS
이 블로그에 작성된 내용은 위 시리즈 중 Gitbook 으로 작성된 Practical Spark 를 옮긴 것입니다. 원본 Gitbook 와 실습에 사용하는 코드는 아래의 링크에서 보실 수 있습니다.
- (Spark Batch) https://1ambda.gitbook.io/practical-data-pipeline/02-processing/2.2-batch
- (Spark Stream) https://1ambda.gitbook.io/practical-data-pipeline/02-processing/2.4-stream
- (Code) https://github.com/1ambda/practical-data-pipeline-code
Spark Versions
이 챕터에서는 Spark 버전별 변경 사항에 대해서 다룹니다. 기본적인 내용은 아래의 두 문서에서 확인할 수 있습니다.
Spark 0.6.0 (2012. 10)
Java API 가 추가되었습니다. Spark Standalone Cluster 모드를 사용할 수 있게 되었고, Yarn Cluster 위에서 동작하는 기능이 실험 (Experimental) 기능으로 지원되었습니다.
- 당시 시점에서는 Mesos 클러스터 위에서 사용하는 패턴이 주류였습니다.
persist() 함수가 추가되었고 이로인해 캐싱을 메모리 넘어 Disk 에 저장할 수 있게 되었습니다.
Spark 0.7.0 (2013.02)
- Python API 가 추가되었습니다.
- Alpha 단계의 스트리밍 기능이 지원되기 시작했습니다. (Technical Report)
Spark 0.8.0 (2013. 09)
- Spark UI 가 지금과 같은 형식으로 제공되기 시작했습니다.
- Machine Learning Library 인 MLlib 이 Spark 프로젝트의 구성요소로 개발되기 시작했습니다.
- Hadoop Yarn Support 가 Experimental 이 아니라 공식적으로 지원되기 시작했습니다.
Spark 0.9.0 (2014. 02)
- Spark Streaming 부분에 많은 개선이 있었습니다.
- GraphX 가 그래프 연산을 위한 Spark 의 컴포넌트로 개발되기 시작했습니다.
Spark 1.0.0 (2014. 05)
- Spark SQL 이 추가되었습니다.
- ML / Streaming / GraphX 등 라이브러리 부분에서 많은 개선이 있었습니다.
Spark 1.1.0 (2014. 12)
- 캐싱된 Partition 이 너무 클 경우 Disk 에 Spill 하는 기능이 추가되었습니다. 이전까지 Spark 는 특정 파티션이 너무 클 경우 전체를 읽다가 (Skew) OOM 이 발생하곤 했습니다. (SPARK-1777)
- 정렬 (Sort) 기반의 Shuffle 이 추가되었습니다.
A simple idea is to periodically check the size of the buffer as we are unrolling and see if we are over the memory limit. If we are we could prepend the existing buffer to the iterator and write that entire thing out to disk.
Spark 1.2.0 (1014. 12)
- 대규모의 셔플을 처리할 수 있는 Sort 기반의 Shuffle 전략이 기본으로 채택되었습니다. (SPARK-3280)
- 런타임에 동적으로 Executor 수를 조절할 수 있는 Dynamic Allocation 기능이 추가되었습니다. (SPARK-3174)
- Spark SQL 에서는 Dynamic Partition Insert 가 추가되었습니다 (SPARK-3007)
- Spark Streaming 에서 Python API 가 추가되었고 Driver 의 데이터 손실을 Write Ahead Log 를 통해 방지할 수 있게 되었습니다. (SPARK-3129)

Spark 1.3.0 (2015. 03)
- DataFrame API 가 Spark 1.3 에 추가되었습니다.
- 하나의 Table 을 위한 Parquet 파일이 스키마가 변경될 수 있도록 Parquet 를 위한 Schema Evoluation 기능이 지원되었습니다. (e.g., 하나의 컬럼에 대해 이전에는 nullable = false, 이후에는 nullable = true 등)
Spark 1.4.0 (2015. 6)
- Spark 에서 R 을 사용할 수 있게 되었습니다.
- Python 3 을 지원하기 시작했습니다.
- DataFrame 및 Spark SQL 에서는 ORC 파일 (Columnar) 지원이 되었고, Wnidow Function 을 포함해 각종 유용한 함수들이 추가되었습니다.
Spark 1.5.0 (2015. 09)
- Spark Core 에서는 Memory + Local Disk 를 섞어서 Checkpoint 를 만들 수 있는 옵션이 추가되었습니다. 이 방법은 HDFS 등 복제 저장소에 Checkpoint 를 만드는 것보다 덜 안정적이지만 속도는 빠릅니다. (SPARK-1855)
- RDD 의 persist() 는 RDD Lineage 를 보존하지만 checkpoint 는 RDD 의 Lineage 를 보존하지 않고 현재까지의 결과를 HDFS 등에 저장합니다. 더 자세한 내용은 What is the difference between spark checkpoint and persist to a disk 과 RDD Checkpointing 에서 살펴볼 수 있습니다.
- Spark RDD 의 Checkpoint 와 Spark Streaming 의 Checkpoint 는 다른 기능입니다.
- Spark DataFarme / SQL 부분에서는 Shuffle Join 시에 Hash Join (Memory) 대신 Sort-merge (External, Disk 사용) 을 활용함으로써 데이터 사이즈가 메모리가 아니라 디스크 (일반적으로 더 큼) 에 의해 제약되도록 하였습니다.
- Hive 의존성이 1.2 로 업그레이드 되었고 Metastore 에 대한 Partition Pruning Pushdown 기능이 추가되었습니다. (spark.sql.hive.metastorePartitionPruning)
- Parquet 파일 포맷의 Predicate Pushdown 이 기본으로 활성화 되기 시작했습니다.
Spark 1.6.0 (2016. 01)
- Dataset API 가 추가되었습니다. RDD 의 함수형 API 와 Spark SQL 엔진의 최적화를 둘 다 사용할 수 있는 API 로서 도입되었습니다.
- Unified Memory Management (SPARK-10000) 로 사용자들은 Execution Memory / Storage Memory 를 좀 더 유연하게 쓸 수 있게 되었습니다.
Spark 2.0.0 (2016. 07)
- DataFrame 과 Dataset API 가 통합되었습니다. Spark 2.0 부터
DataFrame은Dataset[Row]타입이며, Dataset 은 DataFrame 의 API 를 이용할 수 있습니다. - 신규로 추가된 SparkSession 클래스를 활용해 기존의 SQLContext, HiveContext 를 대체할 수 있게 되었습니다. 이제 SparkSession 으로 사용하는 API 에 상관 없이 단일화된 설정 방식을 가져갈 수 있습니다.
- CSV 데이터 소스가 Built-in 으로 지원되기 시작했습니다. (이전에는 외부의 spark-csv 모듈을 사용했었습니다)
- 캐싱 및 런타임 집계에서 Off-heap 을 사용하는 Memory 관리 기능이 지원되기 시작했습니다.
- Streaming 부분에서는 Structured Streaming 이 추가되었고 이제 사용자는 DataFrame / Dataset API 를 이용해 Spark SQL 과 Catalyst Optimizer 이점을 누리면서 Streaming Application 을 작성할 수 있게 되었습니다.
- Spark SQL 을 위한 Code Generation 옵션이 기본으로 활성화 되었습니다.(
spark.sql.codegen.wholeStage) Spark 는 Whole-stage Codegen 기법을 통해 사용자의 실행 요청 (다수의 Stage) 를 하나의 최적화된 Function 으로 만들어 Virtual Function Call 을 줄이고, CPU Register 이용율을 높이는 등 실행 속도 개선을 이루었습니다.
This question led us to fundamentally rethink the way we build Spark’s physical execution layer. When you look into a modern data engine (e.g. Spark or other MPP databases), majority of the CPU cycles are spent in useless work, such as making virtual function calls or reading/writing intermediate data to CPU cache or memory. Optimizing performance by reducing the amount of CPU cycles wasted in these useless work has been a long time focus of modern compilers.
Spark 2.0 ships with the second generation Tungsten engine. This engine builds upon ideas from modern compilers and MPP databases and applies them to data processing. The main idea is to emit optimized bytecode at runtime that collapses the entire query into a single function, eliminating virtual function calls and leveraging CPU registers for intermediate data. We call this technique “whole-stage code generation.”
Spark 2.1.0 (2016. 12)
- Spark SQL 부분에 from_json, to_json 함수가 추가되었습니다.
- Structured Streaming 에서 Kafka 0.10 과 Event Time 을 지원하기 시작했습니다.
Spark 2.2.0 (2017. 07)
- Spark SQL 에서
LATERAL VIEW OUTER구문과explode()함수를 지원하기 시작했습니다. - 특정 Executor 의 반복적인 실패가 전체 Job 에 대한 실패로 번지는 것을 막기 위해 Task Scheduling 에 Blacklist 컨셉이 도입되었습니다 (SPARK-8425)
- 현재는
spark.excludeOnFailure옵션을 통해 조절 가능합니다.
- 현재는
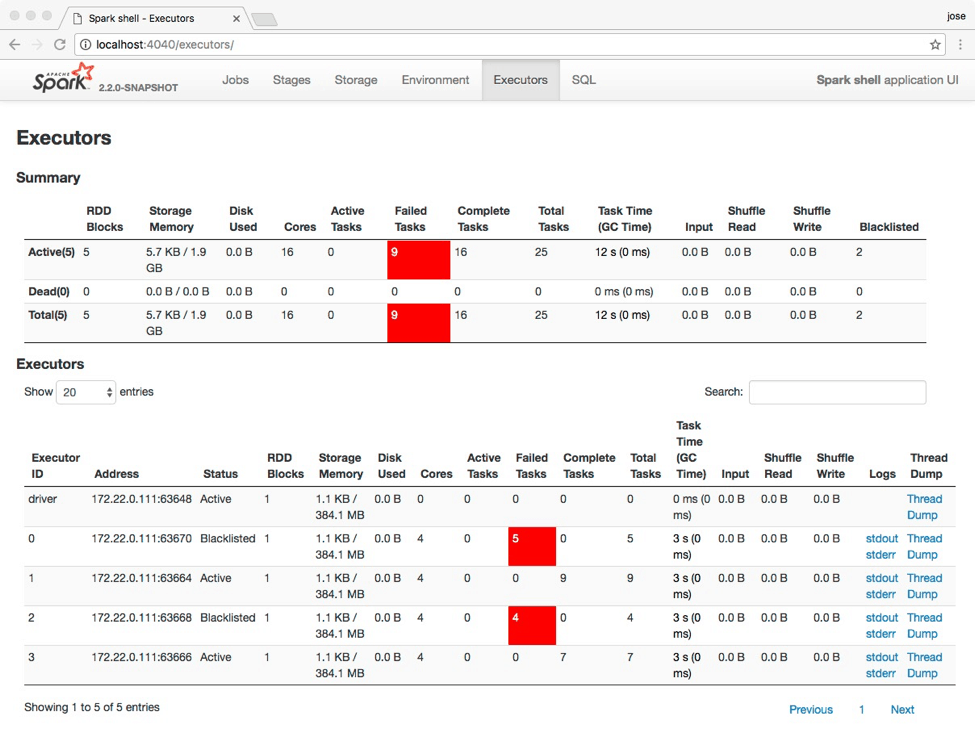
After encountering the failure repeatedly, the driver decides that this executor and/or this node is unreliable. The driver removes the executor or node from the pool of available compute resources, and retries the task somewhere else. It likely succeeds and the user’s job continues transparently.
Spark 2.3.0 (2018. 02)
- Spark on Kubernetes 기능이 실험적으로 추가되었습니다.
- Spark History Server 가 V2 로 개선되었습니다.
- Structured Streaming 부분에서 Continuous Processing 모드가 추가되었습니다. 이제 Micro Batch 보다 더 촘촘한 처리 속도를 위해 이 모드를 사용할 수 있습니다. 이외에도 Stream-Stream Join 기능이 추가되었고 Streaming API V2 가 도입되었습니다.
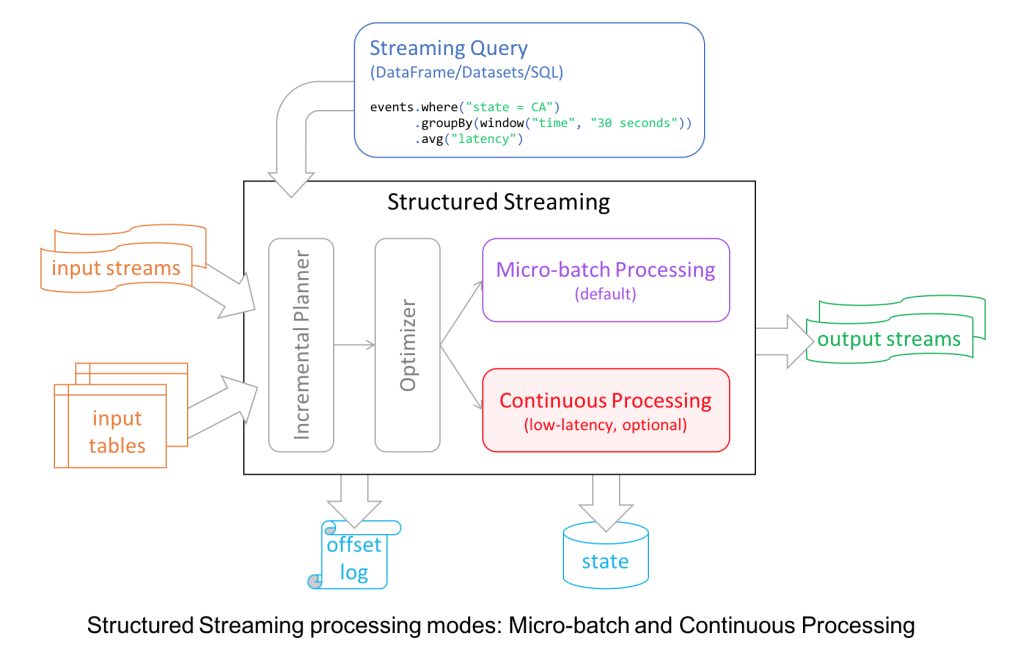
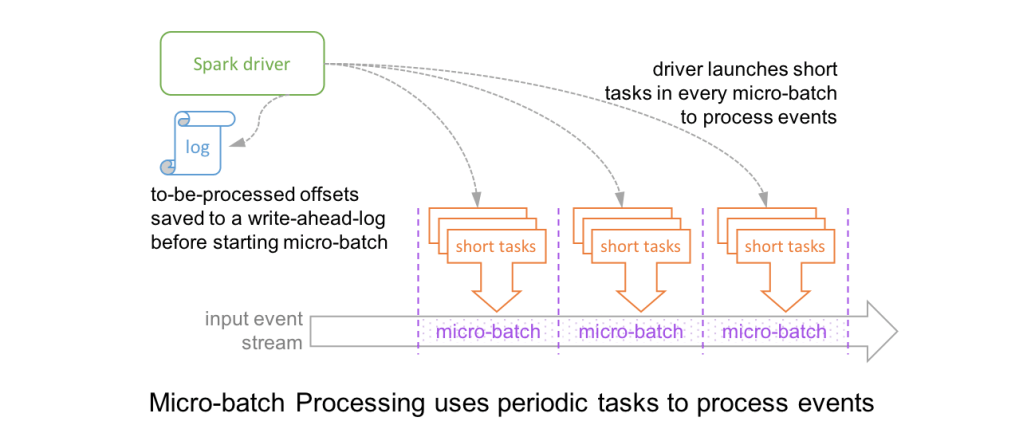


Spark 2.4.0 (2018. 11)
- Avro 데이터 소스가 Built-int 으로 지원되기 시작했습니다.
- Coalesce, Repartition 힌트가 SQL 에서 사용 가능해졌습니다.
- Hive Metastore 2.3 이 지원되기 시작헀고, 이 버전은 현재 EMR 5 를 포함해 많은 환경에서 기본 버전입니다.
- Kubernetes Cluster Manager 에서 PySpark, R 바인딩이 지원되고 Client 모드와 볼륨 마운팅을 사용할 수 있게 되었습니다.
- Bucket Pruning 기능이 추가되었습니다. Spark 에서는 bucketBy, sortBy 등의 함수를 통해 데이터를 미리 분할 정렬된 형태로 저장해 다음 시점에 읽어 사용할 때 Shuffle 을 최소화 할 수 있습니다.
- JDBC Connector 에서 Date / Timestamp 를 Partition 컬럼으로 사용이 가능해졌습니다. 이외에도 Parquet, ORC, JSON 등 다양한 커넥터가 개선되었습니다.
- Structured Streaming 에서는 Kafka Client 버전이 0.1.0.1 에서 2.0.0 으로 업그레이드 되었습니다. 이외에도 Micro Batch 모드에서
foreachBatch함수가 추가되는 등 일부 개선이 있었습니다.
Spark 와 Hive 의 Bucket Semantic 은 다르긴 하나, 이해를 돕기 위해 Hive 의 Partition vs Bucket 사진을 첨부합니다
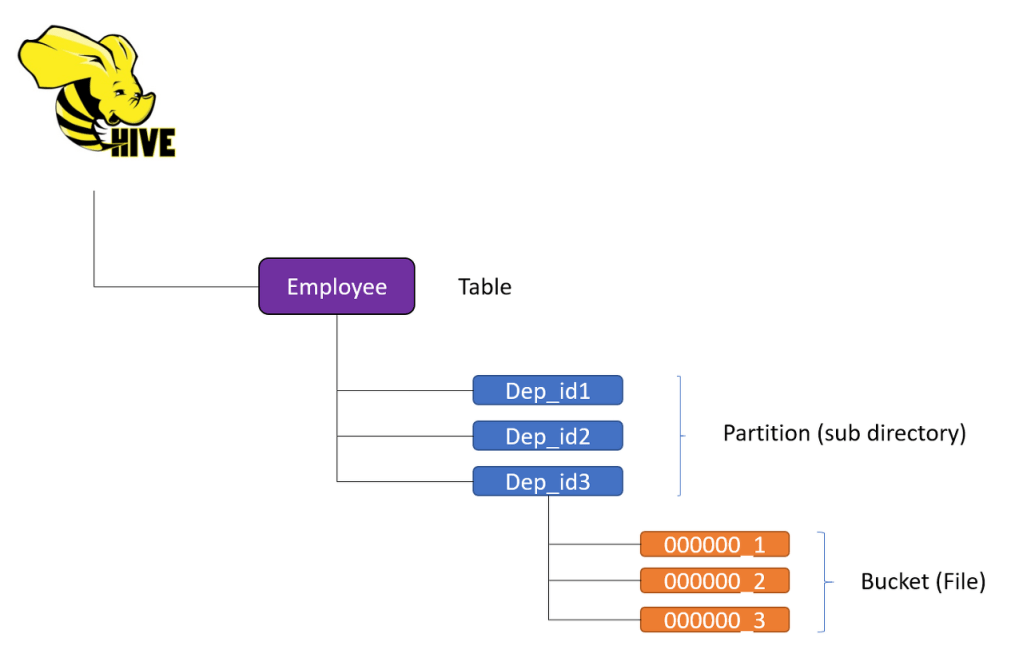
Spark 3.0.0 (2020. 01)
- Adaptive Query Execution (AQE) 이 추가되었습니다.
- ANSI SQL 호환성 부분에서 많은 개선사항이 있었습니다.
- Structured Streaming UI 가 Spark UI 에 추가되었습니다.
- Python 사용자들을 위해 Pandas UDF API 가 개선되었습니다.
- Hadoop 3 및 Hive Metastore 3.1 이 지원되고 Hive 2.3 버전을 기본 의존성 및 실행 엔진으로 사용합니다.
- Hadoop 3.1 에서는 S3A Commiter 가 추가되었고, Spark 는 S3A Commiter 를 활용하는 PathOutputCommiter 를 구현하였습니다. 이를 통해 S3 를 사용할 때 기존의 FileOutputCommitter V1, V2 대신 더 빠른 성능을 얻게 되었습니다.
Spark 3.1.0 (2021. 03)
- Spark on Kubernetes 가 GA 되었습니다.
- Node Decommisioning 기능이 Kubernetes 및 Standalone Cluster 를 대상으로 실험적으로 추가되었습니다. 이 기능을 통해 Node 가 Shutdown 되기 전에 S3 등으로 Node 내의 Shuffle, Cache 데이터 등을 옮겨 다시 계산하는 것을 피할 수 있습니다. (SPARK-20624)
- Hadoop 3.2.0 이 기본 환경으로 채택되었습니다.
Spark 3.2.0 (2021. 10)
- 기존에 https://github.com/databricks/koalas 라는 이름으로 분리되어 있던 Pandas API 가 PySpark 에 통합되었습니다.
- AQE 가 기본으로 활성화 됩니다.
- Hadoop 3.3.1 이 기본 환경으로 채택되었습니다.
- Structured Streaming 에서는 RocksDB 가 State 저장소로 추가되었고, Kafka Client 가 2.8.0 으로 업그레이드 되었습니다.
- Push-based Shuffle 기능이 추가되었습니다. (SPARK-30602)
- 구현에 대한 자세한 내용은 Linkedin 블로그 A scalable and performant shuffle architecture for Apache Spark 에서 볼 수 있습니다.
External Shuffle Service 를 이용하면 Shuffle File 을 Executor 가 아니라 Exeternal Shuffle Service 가 관리하므로 Executor 다운 등에도 문제가 없습니다.
- 단, External Shuffle Service 는 공유 자원이므로 병목이 될 수 있습니다.
- Spark on Kubernetes 는 3.2.0 기준으로 External Shuffle Service 를 Built-in 지원하지 않습니다. 별도 배포를 통해 커뮤니티 사용자가 제작한 ESS 를 사용할 수 있습니다.
- https://medium.com/@rachit1arora/apache-spark-shuffle-service-there-are-more-than-one-options-c1a8e098230e
외부의 (Reducer-side) ESS 가 Shuffle File 을 읽어갈 때는 요청이 랜덤하게 들어오므로 Local (Mapper-side) 의 ESS 에서 Random Disk IO 가 발생합니다. Push 형태로 직접 전송함으로써 이 부분을 개선하고, 아주 작고 많은 Shuffle File 을 병합함으로써 성능을 개선할 수 있습니다.



