이번 챕터에서는 Apche Spark 사용자들이 자주 묻는 질문들을 17 가지 정도 정리해봤습니다. Spark 를 처음 사용하시거나 데이터 엔지니어링 세계로 새롭게 들어오신 분들에게 도움이 되지 않을까 싶습니다.다루는 주제는 Scala 를 어떻게 학습하면 좋을까 부터 AWS EMR 관련된 이야기들 혹은 Spark 사용하면서 발생하는 OOM 이슈와 리소스 할당등 다양한 주제에 대해 이야기 해봅니다.

Practical 시리즈는 AWS 환경 위에서 데이터 인프라를 구축하는데 참고할만한 내용들을 담고 있습니다. 아래의 내용들을 주로 다룹니다.
- Practical Spark
- Practical Kafka
- Practical Kubernetes
- Practical AWS
이 블로그에 작성된 내용은 위 시리즈 중 Gitbook 으로 작성된 Practical Spark 를 옮긴 것입니다. 원본 Gitbook 와 실습에 사용하는 코드는 아래의 링크에서 보실 수 있습니다.
- (Spark Batch) https://1ambda.gitbook.io/practical-data-pipeline/02-processing/2.2-batch
- (Spark Stream) https://1ambda.gitbook.io/practical-data-pipeline/02-processing/2.4-stream
- (Code) https://github.com/1ambda/practical-data-pipeline-code
Spark Interview Questions
- 0. Spark, Flink 등을 이용한 Streaming Application 은 왜 고비용인가요?
- 1. Scala Spark 를 사용하고 있습니다. Scala 학습을 위해서 어떤 책이나 문서를 참고할 수 있을까요?
- 2. Spark Executor 와 Node 간의 관계가 잘 이해가 되지 않습니다.
- 3. Driver 와 Executor 가 실행되는 순서가 궁금합니다. 만약 Yarn 이 아니라 Kubernetes 에서 실행되도 동일한가요?
- 4. Client 모드와 Cluster 모드가 잘 이해가 되지 않습니다. 구체적으로 어떤 차이가 있는걸까요? Local 모드일 경우에는 Executor 는 별도 프로세스일까요?
- 5. Spark 의 Executor 와 Partition 의 관계가 잘 이해가 되지 않습니다. 또한 Spark 에서 Executor 의 숫자와 Partition 숫자는 어떻게 정할 수 있을까요?
- 6. EMR 에서 Master 노드는 무슨일을 하는건지 궁금합니다. Spark Driver 가 EMR Core 에서 실행되고 Spark Executor 가 Task 에서 실행되면 EMR Master 는 필요 없는게 아닐지요?
- 7. RDB 를 사용하는것과 Spark 를 사용하는것은 어떤 차이점이 있나요? 일반적으로 Spark 작업은 어떻게 튜닝하나요?
- 8. Spark Client 모드에서 Driver 리소스 옵션이 적용되지 않는것 같습니다.
- 9. DataFrame 이 Immutable 하다는게 무슨 뜻인가요?
- 10. Spark JDBC Write 를 이용할 때 DB Lock 이 걸리지 않을까요?
- 11. Spark Streaming 등으로 HDFS / S3 에 File 을 계속 Append 하고 있을 때 다른 Spark 에서 그것을 읽으면 어떻게 됩니까?
- 12. MySQL 이나 Hive Partition 과 Spark Partition 이 혼동됩니다. Spark Partition 을 변경하면 내가 읽는 물리적 파티션도 변경되나요? (원본 HDFS / S3 내의 Parquet, CSV 파일등의 숫자가 조절됩니까?)
- 13. Spark Executor 를 위해 spark.executor.memory = 50g (50 GiB) 를 할당하면 정확히 50 GiB 만 할당되는걸까요? 50 GiB 를 사용 가능한 노드에서 Spark Executor 를 할당할 수 없다고 오류가 나옵니다.
- 14. DataFrame 을 그냥 사용하는것과 DataFrame.createOrReplaceTempView 로 View 로 만들어 사용하는 것의 성능 차이가 있을까요?
- 15. Event 테이블은 사이즈가 커 캐싱이 어렵고, Meta 테이블은 사이즈가 작아 캐싱을 할 수 있다 하더라도 효과가 있는지 의문입니다. 언제 캐싱을 하는게 맞을까요?
- 16. Spark 에서 Off-heap, On-heap OOM 이 발생합니다. 어떤 옵션을 조절해야 할까요?
Question 0:
Spark, Flink 등을 이용한 Streaming Application 은 왜 고비용인가요?
(개인의 주관이 포함되어 있는 답변입니다.)
데이터 관련 일을 하다보면 다음과 같은 질문들을 가끔 받습니다.
실시간으로 집계 / 분석 가능하도록 해주세요.
그런데, 과연 얼마나 많은 서비스가 실시간 처리가 필요할까요?
- 비용과 관련되어 있거나, 실시간 타게팅이나 추천 등 많은 데이터 서비스에서 필요한 경우도 있습니다만
- 실시간 서비스가 필요치 않은 경우가 더 많습니다. 초단위가 아니라 분단위거나, 1시간 지연이어도 문제 없는 경우가 대부분입니다.
정말로 필요하다면 Streaming Processing 을 위한 Infra / Application / 그 이후의 비즈니스 및 서비스 운영등을 수행해야겠습니다만 그 비용이 얼마나 클지를 생각해봅시다.

Stream Processing 은 실시간 데이터를 처리할 수 있지만 매우 물리 / 노동 비용 관점에서 고비용입니다. 다음 측면을 고려해 봅시다.
- 지속적으로 Streaming Appilcation 이 떠있어야 합니다. 특성상 Streaming Application 은 트래픽이 튀는 상황에서도 ‘안전성’ 을 보장해야 하므로 일정량 이상의 여분 리소스가 필요합니다. (경우에 따라 Auto Scaling 을 사용할 수도 있습니다.)
- 지속적으로 Streaming Application 이 떠 있다는 말은 새벽에 문제가 생길 경우에도 담당자가 대응을 해야한다는 의미입니다. 자동 복구 등의 프로세스를 갖출 수 있겠지만, 예외적인 경우에는 사람의 간섭이 필요한 복구가 존재할 수 있습니다. (정책적 결정이 필요한 경우 등) Streaming Application 의 숫자가 늘어날수록 노동 인력에게 가해지는 부하가 늘어납니다.
- Streaming Application 을 위한 기반 데이터 인프라가 필요합니다. Kafka / Zookeeper 등이 필요하고 Spark / Flink Streaming 을 위해 Cluster Manager 가 필요합니다.
- 단일 Streaming Application 을 위해 복구용 Topic 과 Batch Application, Dead Letter 큐를 S3 에 내리기 위한 보존용 Application 등 여러 Application 필요할 수 있습니다.
따라서 Streaming Application 은 일반적으로 ‘실시간 데이터’ 를 사용해 효과가 혹은 혜택이 있는 경우에만 사용하는게 바람직합니다.
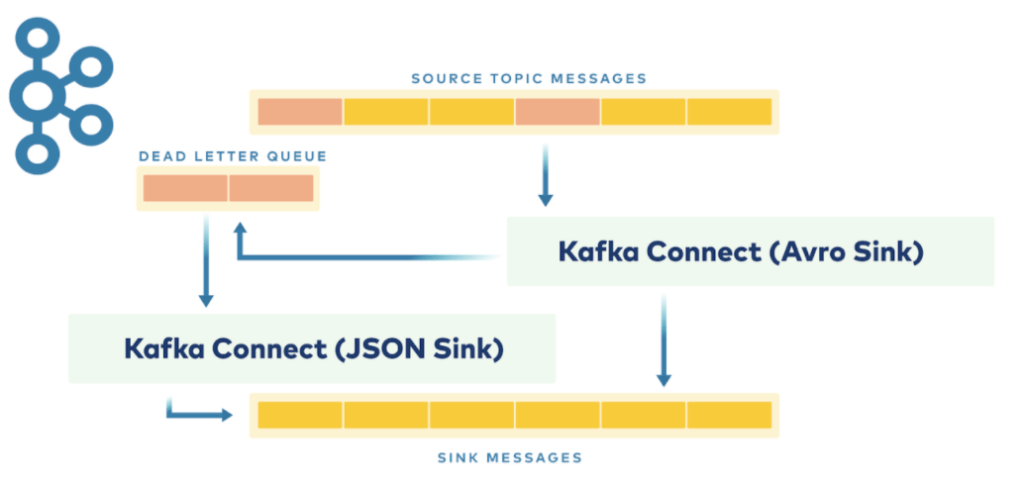
위 그림은 Kafka 등 Message Queue 사용시 Dead Letter Queue 를 이용하는 패턴을 보여줍니다.
- (A) Kafka Topic 의 Message 를 읽어 가공한 후 다른 Storage 로 적재합니다 (S3, Dynamo, Kafka 등)
- (B) Processing 과정에서 실패한 Kafka Topic 내 Message 는 추후 다시 처리하기 위해 Dead Letter Queue (DLQ, 또 다른 Kafka Topic) 으로 보냅니다.
- (C) DLQ Kafka Topic 내 Message 는 Retention 에 의해 삭제될 수 있기 때문에, DLQ 에 쌓인 메세지는 S3 에 적재합니다.
시간이 지나 S3 에 쌓인 데이터를 (Batch Source) 읽어 문제를 해결한 후 (A) 에서 보내려고 했던 Storage 에 다시 보낼 수 있습니다. 이 때 두 가지 옵션이 있을 수 있습니다.
- S3 데이터를 Spark Batch Application 에서 읽어 최종 Storage 인 (A) 로 직접 적재합니다.
- 만약 (A) 에서 사용되는 Spark Streaming 에서 메모리에 State 등을 활용한다면, S3 데이터를 읽어 (A) Kafka Topic 으로 데이터를 흘려 보내고 Spark Streaming 이 이 메세지를 다시 처리하게끔 할 수 있습니다.
즉, (2) 번 옵션은 Spark Batch Application 이 S3 데이터를 읽어 원본 Kafka Topic 으로 다시 보내고, 이것을 기존의 Spark Steraming Application 이 처리합니다.단, 원본 Kafka Topic 이 다른 Consumer 들에 의해 공유되는 경우 (Inventory 등) 별도 작업 복구를 위한 Kafka Topic 을 만들고 Spark Streaming Application 이 이것을 사용할 수 있습니다.
Question 1:
Scala Spark 를 사용하고 있습니다. Scala 학습을 위해서 어떤 책이나 문서를 참고할 수 있을까요?
(개인의 주관이 포함되어 있는 답변입니다.)
Scala 학습을 위해 아래의 컨텐츠를 추천 또는 비추천 합니다.
- (추천, 책)Programming in Scala 4/e 창시자가 직접 집필한 스칼라 언어의 바이블
- 두꺼워서 처음부터 읽을 필요는 없고 모르는 부분이 나올때 조금씩 찾아보면서 시간을 들여 익혀가면 됩니다.
- (추천, 강의) Coursera: Functional Programming Principles in Scala
- Scala 언어의 기본 문법과 이를 바탕으로 한 응용에 대해 설명합니다 (과하지 않음)
- (추천, 강의) Coursera: Functional Program Design in Scala
- Scala 언어의 기본 문법과 이를 바탕으로 한 응용에 대해 설명합니다 (과하지 않음)
- (추천, 강의) Coursera: Parallel Programming
- Scala 언어의 기본 문법과 이를 바탕으로 한 병렬처리 대해 설명합니다 (과하지 않음)
- (추천, 강의) Coursera: Programming Reactive Systems
- Scala 언어의 기본 문법과 이를 바탕으로 Reactive System 대해 설명합니다 (과하지 않음)
- (비추천, 책)스칼라로 배우는 함수형 프로그래밍
- Scala 의 실제 용도보다는 이론적인 토대에 다루며, 실무에서 쓰이지 않는 내용에 대해 너무 과하게 집중
유료로 비용을 내고 학습하시기 보다는 온라인에 있는 Coursera 등 무료 클래스를 수강하시는 것을 추천합니다. 시간이 지나도 배울만한 충분히 가치 있는 내용을 담고 있습니다.
함수형 프로그래밍 관련해서 조금 코멘트를 덧붙이자면,
함수형 프로그래밍을 배우는 것은 나쁘지 않습니다. 저는 한명의 엔지니어가 언어를 배우면서 언어가 지원하는 컨셉을 익히며 사고를 넓혀가는 과정이라고 이해하고 있습니다. Golang 이라면 Goroutine 이나 Duck Typing 같은 것들이 있겠지요.
다른 언어에 있는 ‘컨셉’ 을 이해하면, 새로운 언어를 배우거나 현재 사용하고 있는 언어에서 ‘비슷한 컨셉’ 이 없을지 고민할 수 있게 되고 비슷한 기능을 지원하는 ‘라이브러리’ 를 찾거나 직접 만들어 사용할 수 있는 ‘응용’ 을 할 수 있습니다.
사피어-워프 가설은 한 사람이 세상을 이해하는 방법과 행동이 그 사람이 쓰는 언어의 문법적 체계와 관련이 있다는, 언어학적인 가설이다.
https://ko.wikipedia.org/wiki/%EC%82%AC%ED%94%BC%EC%96%B4-%EC%9B%8C%ED%94%84_%EA%B0%80%EC%84%A4
저도 과거에 Lisp 을 학습 했었고, Emacs 를 커스터마이징 해서 사용했으며 이 블로그에도 Functioncal Programming 관련된 주제나 Haskell 등의 언어 관련해서 블로깅 된 내용들이 있습니다.
다만, 우리의 시간은 한정되어 있고 데이터 엔지니어링 업무의 특성상 다뤄야 할 기술들이 많습니다. AWS 에서 내는 새로운 서비스와 최근 버전의 패치 노트를 따라가고, 데이터 인프라에서 사용하는 각종 스토리지와 도구들을 이해하기에도 우리의 시간은 모자랍니다.
함수형 프로그래밍은 알면 좋으나, 데이터 엔지니어의 업무에 많이 활용되는 기술은 아닙니다. 너무 멀리 나가면, 작성한 사람만 이해할 수 있는 코드가 되기도 하지요.
예를 들어, 팀에서 Spark 로 실시간 User Profile 을 만들어 사용하고 있는데, 담당자가 모두 휴가 갔을때 급하게 수정할 일이 생겨서 코드를 열어봤더니 Free Monad 가 있다면 어떨까요? 복잡한 Currying 이 있을수도 있고, Scalaz 라이브러리를 과하게 썼을수도 있습니다.
| trait Monad[F[_]] { | |
| def point[A](a: A): F[A] | |
| def bind[A, B](fa: F[A])(f: A => F[B]): F[B] | |
| def map[A, B](fa: F[A])(f: A => B): F[B] = | |
| bind(fa)(a => point(f(a)) | |
| def join[A](ffa: F[F[A]): F[A] = | |
| bind(ffa)(fa => fa) | |
| } | |
| sealed trait Free[F[_], A] { | |
| def point[F[_]](a: A): Free[F, A] = Point(a) | |
| def flatMap[B](f: A => Free[F, B])(implicit functor: Functor[F]): Free[F, B] = | |
| this match { | |
| case Point(a) => f(a) | |
| case Join(ffa) => Join(ffa.map(fa => fa.flatMap(f))) | |
| } | |
| def map[B](f: A => B)(implicit functor: Functor[F]): Free[F, B] = | |
| flatMap(a => Point(f(a))) | |
| } | |
| case class Point[F[_], A](a: A) extends Free[F, A] | |
| case class Join[F[_], A](ff: F[Free[F, A]]) extends Free[F, A] |
함수형 프로그래밍의 개념 또는 라이브러리를 팀 전체가 공유하고 최저 학습 수준을 맞춘다면 문제가 없습니다. 다만 특정 개념이나 언어의 일부를 팀 전체로 확산 시키기에는 데이터 팀에서 하는 일이 너무나 많습니다.
여러분이 도입하는 모든 기술은 문화를 만듭니다. 반드시 주의해야 합니다.
Question 2:
Spark Executor 와 Node 간의 관계가 잘 이해가 되지 않습니다.
Spark Executor 가 무엇인지 이해가 잘 되지 않습니다. EC2 인가요? EMR Yarn 이 아니라 Kubernetes 를 사용한다면 어떻게 되는건가요? 라는 질문도 자주 들어옵니다.
Node 는 AWS EC2 와 같은 머신입니다.
- 하나의 EC2 머신 내에서는 여러개의 Process 가 실행될 수 있습니다.
- Spark Executor 는 JVM Process 입니다.
- 따라서 하나의 EC2 = Node 내에는 여러개의 Spark Exectutor 가 실행될 수 있습니다
- 다만 여러개의 Executor 실행시 EC2 = Node 의 Resource (CPU, Memory, Disk, Network) 를 나눠 쓸 수 있습니다.
- 일반적으로 CPU, Memory 는 쉽게 증설이 가능하지만 Disk IO 나 Network Bandwidth 는 비용대비 효과를 보기도 어렵거나 증설이 쉽지 않습니다. EC2 에서는 Disk IO 는 사이즈나 타입마다 다르며, 증설은 시간이 걸리고, Network Bandwidth 는 머신 타입을 바꾸지 않으면 높이기 어렵습니다.
- Cloud 환경에서는 머신을 생성하는 노동 비용이 거의 없다시피 하므로, 큰 머신을 너무 잘게 잘라 쓰는것보다 머신 숫자를 늘리는게 나을 경우가 많습니다.
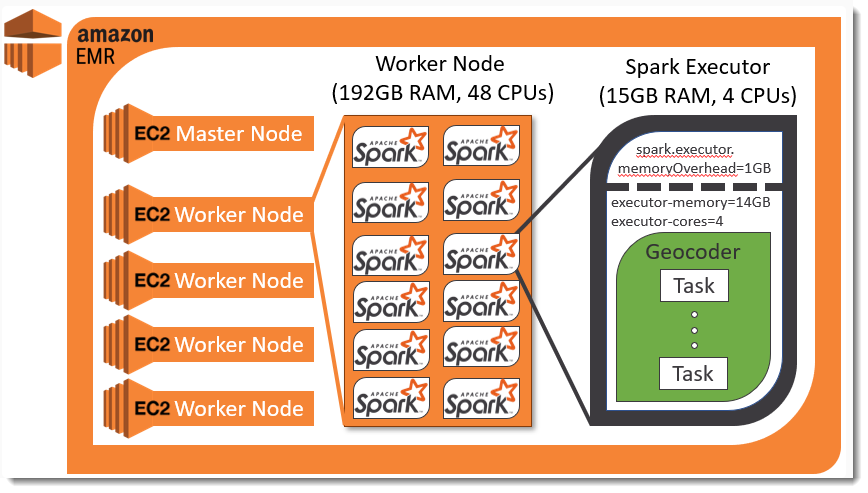
Spark Executor 관점에서 Node 의 리소스를 조금 더 생각해봅시다. Spark Application 1개를 실행한다고 가정해 보면
- 1 개의 Driver 가 필요합니다.
- 1 개 이상의 Executor 가 필요합니다.
- Driver, Executor 모두 JVM Process 입니다.
- 1 개의 Node (EC2) 에서 리소스가 충분하다면, 여러개의 Executor 를 실행할 수 있습니다.
- 예를 들어 m5.2xlarge (8 vCPU, 32 GiB) Node 에서
- spark.executor.instances = 4
- spark.executor.cores = 2
- spark.executor.memory = 8 GiB 일 경우
- m5.2xlarge 1 대의 Node 내에서 4 개의 Executor 를 실행하는 것이 ‘이론적’ 으론 가능합니다.
- 그러나 시스템을 위한 리소스를 일부 남겨놓아야 하기 때문에 Executor 가 노드의 100% 리소스를 사용하진 않습니다 (EMR 의 경우 75% Memory 만 사용 가능)
참고로 Kubernetes 를 쓸 경우, Node (EC2) 내의 1개의 Pod 이 Driver 가 됩니다.
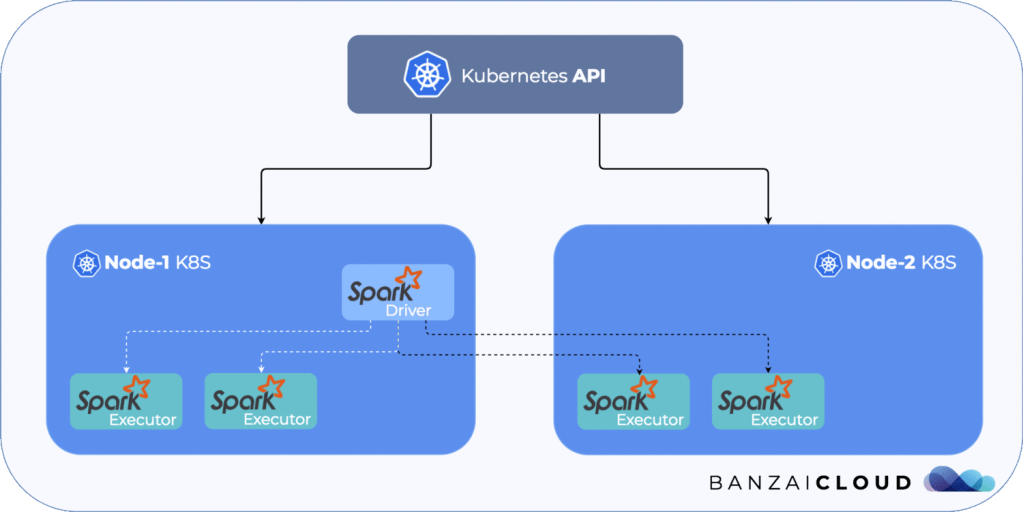
Question 3:
Driver 와 Executor 가 실행되는 순서가 궁금합니다. 만약 Yarn 이 아니라 Kubernetes 에서 실행되도 동일한가요?
사용자는 Batch (1회 실행 후 종료) 또는 Streaming (지속적으로 떠있으면서 데이터를 처리) 작업을 위해 Spark Application 을 실행합니다. (Jar, Python File 등) Spark Appilcation 내에는 1개의 Driver 와 1개 이상의 Executor 가 존재할 수 있습니다.
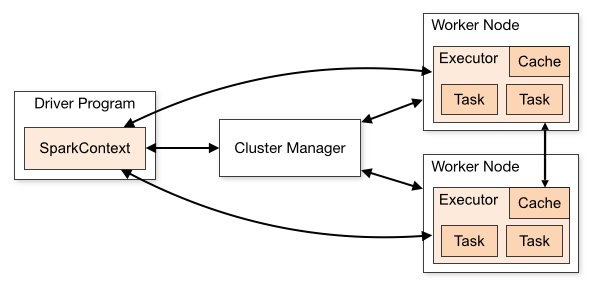
Spark Cluster 모드 사용시 Spark Appilcation 은 아래의 과정을 거쳐 Driver / Executor 가 생성 및 실행됩니다.
- Spark Driver 가 실행되면 main() 이 실행되며 Spark Context 를 만들고
- Spark Driver 내의 Spark Context 는 Cluster Manager 와 통신해 (Yarn, Kubernetes 등) Executor 를 할당 받습니다
- Spark Driver 는 Executor 에게 사용자가 작성한 코드 실행을 위해 Spark Context 내의 Jar, Python File 들을 전송합니다.
- Spark Driver 내의 Spark Context 는 사용자의 코드를 바탕으로 실행 계획을 만들어 최종적으로는 Task 를 Executor 에게 전달합니다.
- 이 과정은 Cluster Manager 가 Yarn / Kubernetes 상관 없이 동일합니다.
Spark Driver 와 Executor 가 초기화 된 후 사용자가 요청한 Task 가 실행됩니다. 이 때 Driver 는 Executor 로 부터 데이터를 직접 받거나 (collect) Driver 로 부터 Executor 로 실행될 코드 등을 전송할 수 있습니다.
또한 Executor 간에는 데이터 이동이 (Shuffle) 발생할 수 있으므로 같은 네트워크 영역에 위치하는 편이 좋습니다. 따라서 EMR 을 만들경우 단일 AZ 내에서만 사용할 수 있습니다. (AZ-a 만 사용하는 등)
Question 4:
Client 모드와 Cluster 모드가 잘 이해가 되지 않습니다. 구체적으로 어떤 차이가 있는걸까요? Local 모드일 경우에는 Executor 는 별도 프로세스일까요?
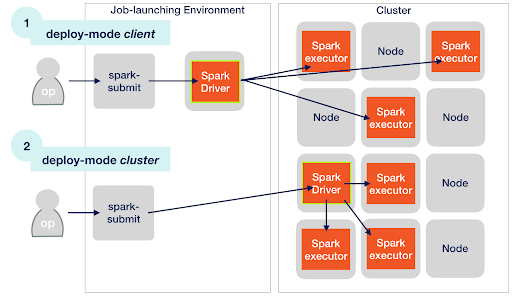
환경을 3가지로 나누면 이해가 쉽습니다.
- Spark Application 을 ‘Submit’ (실행 요청) 하는 환경
- Spark Driver 가 돌아가는 환경
- Spark Executor 가 돌아가는 환경
| Application Launch 환경 | Driver 실행 환경 | Executor 실행 환경 | 설명 | |
| Local Mode | Submit 하는 머신 | Submit 하는 머신 | Submit 하는 머신 | Driver = Executor 모두 같은 JVM 내에 존재 Executor 는 Thread 로 존재하며 최대 1개 |
| Client Mode | Submit 하는 머신 | Submit 하는 머신 (Driver 가 Submit 하는 머신의 리소스를 소모) | Cluster | Cluster 는 Yarn / Kubernetes 등 |
| Cluster Mode | Submit 하는 머신 (컴퓨팅 없이 단순 요청 및 작업 종료까지 대기만 함, spark.yarn.submit.waitappcompletion 옵션으로 조절 가능) | Cluster | Cluster | Cluster 는 Yarn / Kubernetes 등 |
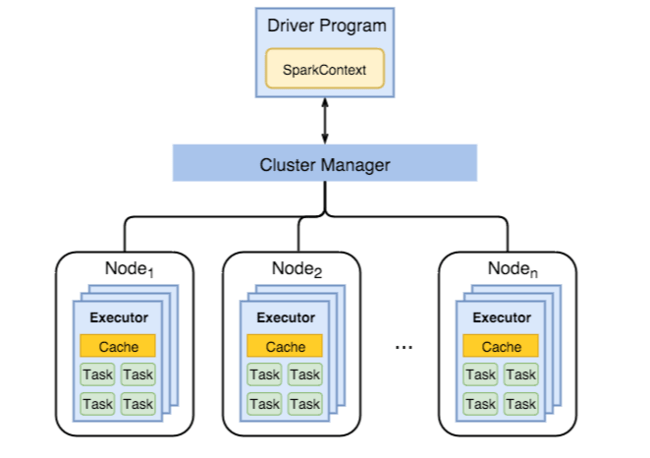
Local 를 그림으로 살펴보면 아래와 같습니다. 아래 그림에서 T 는 스레드가 아니라 Task 입니다. Local 모드는 JVM 이고 Executor 는 단일 스레드이므로, 분산처리가 불가능한 Python 알고리즘등을 Local 모드로 큰 리소스를 받아 PySpark 에서 사용할수도 있습니다.
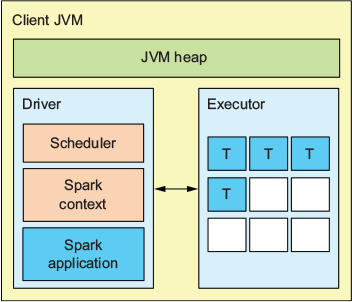
Question 5:
Spark 의 Executor 와 Partition 의 관계가 잘 이해가 되지 않습니다. 또한 Spark 에서 Executor 의 숫자와 Partition 숫자는 어떻게 정할 수 있을까요?
Executor 를 JVM 으로 Partition 을 Thread 갯수로 생각하면 혼동이 생길 수 있습니다. 일부는 맞을수도 있지만 Partition 을 논리적인 병렬처리 단위로 생각하면 조금 더 단순하게 구분할 수 있습니다.
- Partition 은 ‘논리적인’ 개념입니다. 데이터를 몇개로 / 어떤 컬럼 기준으로 나누어 컴퓨팅을 처리할지를 결정합니다.
- 이 과정에서 Partition 숫자, Partition 컬럼, Group By 함수 호출, Join 연산 등에 의해 최종적으로 어떠한 파티션에 어떤 데이터가 있을지 결정이 됩니다.
- repartition(), spark.sql.shuffle.partition 등 설정
- Spark Driver 는 사용자가 만든 DataFrame 코드를 최적화 하면서 Task 를 만들어 냅니다.
- Executor 는 ‘물리적인’ 컴퓨팅을 수행합니다. Spark Driver 로 부터 ‘Task’ 를 전달 받아 실행합니다.
- Executor JVM Process 내에는 Thread 가 여러개 존재할 수 있습니다.
- Task 는 하나의 Thread 에서 실행됩니다 (ThreadRunner)

Partition 을 논리적인 개념으로 Task 를 실제 구현된 Partition 으로 생각하면, 다음과 같이 생각할 수 있습니다.
- Partition 숫자와 Task 숫자는 동일하지 않을 수 있습니다. 만약 repartition(5) 후에 filter(), where() 등으로 특정 파티션이 있는 데이터 전체가 제외된다면 Task 숫자는 그 보다 더 작을 수 있기 때문입니다.
- 그러나 ‘사용자’ 는 실제적으로 실행되는 ‘Task’ 의 숫자를 실행해보기 전 까지는 알 수 없습니다.
Executor 에 할당될 리소스를 정하기 위해서는
- 사용하는 데이터 사이즈를 생각해보고
- 어느 시간 안에 작업이 끝나야 하는지를 정하고
- 클러스터 전체에서 리소스를 해당 시간대에 얼마나 사용할 수 있는지 확인한 뒤에
- 정해진 리소스 안에서 Skew 등을 고려해 파티션 및 Executor 숫자를 정하면 됩니다.
- Executor 가 많다면 네트워크 비용이 많아질 수 있고, Yarn Container / Pod 등이 너무 많아지면 IP 를 소모하거나, 클러스터 전체에 네트워크 부하가 발생할 수 있습니다.
- Executor 가 적다면 Shuffle 등 데이터 이동은 없으나 너무 큰 메모리로 GC 등이 발생하기 쉽습니다. 또한 특정 Executor 에 과도한 작업량의 Task 가 할당되면 균등하지 않게 처리되어 전체 작업시간의 지연이 발생할 수 있습니다.
- Partition 이 적다면 병렬 처리가 어렵고, 개별 Partition 내 데이터 사이즈가 너무 커 메모리가 초과해 OOM 이 발생할 수 있고
- Partition 이 많다면 (사용할 수 있는 CPU 에 비해) Task 가 너무 많아져 스케쥴링 및 Context Switching 에 과도한 Overhead 가 발생할 수 있습니다.요지는, ‘Executor’ 의 숫자는 물리 인프라 / 시스템 관점에서 접근하고, ‘Partition’ 숫자는 데이터 처리 관점에서 바라보는 것이 합당합니다.
더 일반적인 룰은 다음과 같습니다.
- 사내에서 신규로 만들어지는 Spark Application 이 사용하는 데이터 사이즈는 기존에 사용하던 데이터에 비례하기 마련입니다. 예를 들어 주문 데이터가 500GB 인데, 갑자기 45TB 데이터 처리를 할 일은 많이 생기지 않습니다.)
- 또한 비용을 고려하면, 전체 인프라 리소스는 일정 한도가 정해져 있으므로 신규로 만들어지는 Spark Application 이 사용할 수 있는 CPU / Memory 도 전체 인프라 리소스 대비 아주 적은 부분입니다.
- 예를 들어, 기존에 200개 정도 Spark Application 이 실행되고 있고
- 클러스터 전체 리소스가 200 vCPU, 4 TiB 메모리를 이용하고 있었다면
- 갑자기 새로운 Spark Application 에 100 vCPU, 2TiB 만큼 할당하는 것은 합리적이지 않습니다. 그 내용이 무엇이든 경제성을 고려하면 효과가 있다고 말하기도 어렵구요.
- 데이터를 5% (1/20) 정도로 줄여 테스트를 시간을 확인해보고 점진적으로 늘려갈 것을 권장합니다.
Question 6:
EMR 에서 Master 노드는 무슨일을 하는건지 궁금합니다. Spark Driver 가 EMR Core 에서 실행되고 Spark Executor 가 Task 에서 실행되면 EMR Master 는 필요 없는게 아닐지요?

EMR 을 Hadoop Yarn 의 Subset 이라 생각하면 이해가 쉽습니다.
- Hadoop 에서 Yarn 은 리소스를 관리하고 할당하는 역할을 합니다.
- Yarn 은 Container 단위로 리소스를 할당하며 1개의 Yarn Container 가 1 개의 Spark Driver 또는 1 개의 Spark Executor 가 될 수 있습니다.
- Yarn 은 Spark Driver 와 같은 Application 내에서 중요한 컴포넌트를 Application Master 라고 부릅니다.
- 참고로 Yarn 은 범용 Resource Manager 로 설계되어, Flink 가 Yarn 실행될 경우 Flink 의 Job Manager 가 Application Master 가 됩니다.
- Yarn 은 노드의 리소스를 트래킹하고 컨테이너를 할당하기 위해 클러스터 전체에서 1개의 Resource Manager 와
- 노드 마다 1 개씩, 클러스터 전체에서 N 개의 Node Manager 를 실행합니다.

- EMR 은 Yarn 을 구현하며, 추가적으로 Master / Core / Task 라는 컨셉을 도입했습니다.
- Master 노드에서는 Yarn Resource Manager 와 같은 클러스터 전체에서 1개만 존재하는 “중요한” 프로세스가 실행됩니다. (Hive Metastore Service, Spark History Server 등)
- 따라서 Master 에서 다른 무거운 작업을 돌리면, Yarn Resource Manager 가 제 역할을 못해 리소스 할당이 안될 수 있습니다.
- Core 노드는 HDFS (Storage) 를 관리하고 (= Data Node 의 역할)
- EMR 5 의 경우는 Yarn Container 중 Application Master (= Spark Driver) 를 실행합니다
- EMR 6 의 경우에는 기본설정 중 label = CORE 설정이 없어, Spark Driver 또는 Executor 모두 실행 가능합니다.
Question 7:
RDB 를 사용하는것과 Spark 를 사용하는것은 어떤 차이점이 있나요? RDB 와 다르게 Spark 의 explain() 결과는 충분하지 않은 것 같습니다. 일반적으로 Spark 작업은 어떻게 튜닝하나요?
RDB 에서 실행되는 쿼리와 Spark 작업은 다음의 차이점이 있습니다.
- 서비스로 나가는 RDB 쿼리는 많아야 수개 테이블을 조인하지만, Spark Job 은 수십개의 테이블을 Join 할 수 있습니다.
- 서비스로 나가는 RDB 쿼리는 수십-수백 millis 내로 결과를 내야하지만, Spark Job 은 작업에 따라 짧게는 5분, 머신러닝 집계는 수십 시간까지 걸릴 수 있습니다.
- 서비스로 나가는 RDB 쿼리는 단일머신에서 수행되고 RDB 의 메모리는 많아봐야 ‘인스턴스 전체’ 에서 최대 수백기가지만, Spark 작업은 ‘하나의 Job’ 이 수백기가 / 수테라의 메모리를 사용할 수 있습니다.
- 서비스로 나가는 RDB 쿼리는 단일머신에서 수행되므로, 중간 집계를 위한 네트워크 이동이 없습니다. 반면 Spark 작업은 분산처리가 기본이며, Shuffle 로 인한 네트워크 데이터 이동은 물론 메모리 부족으로 인한 Disk Spill 이 발생할 수 있습니다.
- RDB 는 일반적으로 단일머신에서 고성능을 내기 위한 언어로 만들어졌지만, Spark 는 JVM 위에서 동작합니다.
- RDB 는 ‘쿼리’ 단위로 튜닝이 일반적으로 쿼리 실행 시간이 중요한 요소가 되며, 테이블의 DDL (인덱스) 등을 DBA 와 같이 논의할 수 있습니다. 반면 Spark 는 하나의 작업에 걸리는 소요 시간이 긴 만큼 ‘작업’ 단위로 튜닝이 될 수 있습니다. 작업 내에서의 일부 Spark SQL 의 국소적인 최적화는 큰 의미가 없을수도 있습니다.
- 서비스 백엔드 엔지니어는 QueryDSL / JPQL 등으로 감싸진 ‘쿼리’ 를 수백개 작성하고, 운영할 수 있겠지만 데이터 엔지니어는 개별 Table 에 데이터를 적재하는 ‘Spark Job’ 을 한명의 엔지니어가 수백-수천개 관리할 수 있습니다.
따라서 다음의 관점으로 튜닝이 진행됩니다.
리소스 측면에서 실행하는 컴퓨팅 종류에 따라 Driver 및 Executor 의 CPU / Memory 설정과 인스턴스 타입, 그리고 Network / Disk 등 리소스가 충분한지 확인합니다.
- Disk Spill / Shuffle Write 등이 메모리에 비해 과다할 경우 혹은 GC 가 너무 잦게 발생할 경우 메모리를 늘립니다.
- 머신러닝 등 컴퓨팅이 많이 필요한 Spark Job 은 CPU 를 늘릴 수 있습니다. 일반적으로는 작업마다 다른 EC2 인스턴스 타입을 사용하게끔 데이터 인프라가 설계됩니다. (머신러닝은 c5.8xlarge, 일반 집계는 r5.4xlarge 등)
- 네트워크 대역폭이 모자랄 경우 c5n, r5n 등 네트워크 전용 인스턴스 타입을 고려할 수 있습니다. 다만 AWS 특정 Region / Zone 에서는 지원되지 않을 수 있습니다.
- Disk 가 모자랄 경우 Spill 이 더이상 불가능해 Executor 가 종료될 수 있으므로 Shuffle Write / Memory 부족으로 인한 Spill 등 Disk 사용량을 모니터링 해 부족하면 Executor 숫자를 늘려 사이즈를 분산하거나, 더 큰 사이즈의 Disk (AWS EBS) 를 사용할 수 있습니다. 필요에 따라 높은 성능의 IO 를 가진 EBS 클래스를 선택할 수 있습니다.
- RDB 는 리소스를 변경하려면 (Spec Up) Downtime 이 필요하지만, Spark 는 Node 를 쉽게 버튼 눌러 추가하면 됩니다. 따라서 리소스를 추가하는데 부담을 갖지 말고, 내 시간을 아끼는 것에 더 집중하는 편이 낫습니다.
또한 분산처리를 적절히 활용하는것도 RDB 를 사용해 집계를 하는것과 큰 차이점입니다.
- 예를 들어 collect() 대신 foreachPartition 등을 활용할 수 있습니다.
- 가공하는 데이터를 최대한 줄입니다. Predicate Pushdown / Column Pruning / Partition Pruning 등을 지원하는 파일 포맷 혹은 저장소를 사용합니다.
- Spark SQL 에서 대부분의 컴퓨팅 (데이터 처리) 병목은 Window Function, Join, Group By, Distinct 등에서 발생합니다.
- 데이터 사이즈를 고려해 적절한 Join 전략을 취할 수 있습니다. (Broadcast Hash Join 등)
- Group By 등에 사용하는 컬럼 기준으로 집계 직전 repartition() 등을 미리 수행할 수 있습니다.
- 데이터 자체를 집계를 위해 미리 Bucketing 된 형태로 저장할 수 있습니다.
- 정확한 집계가 필요 없다면, 메모리 대신 CPU 를 태우는 확률적 집계 함수 (approx_distinct) 등을 이용할 수 있습니다.
Question 8:
Spark Client 모드에서 Driver 리소스 옵션이 적용되지 않는것 같습니다.
Cluster 모드는 특성상 Driver 를 Cluster Manager 가 띄워주므로 SparkConf 에서 지정한 Driver 를 위한 설정들이 적용됩니다. 그러나 Client (혹은 Local) 일 경우 Driver JVM 이 떠있기 때문에, 이미 뜬 Driver JVM 의 리소스를 지정할 순 없습니다.
| # Client Mode: Driver JVM 이 이미 떠있는 상태에서 Driver JVM 메모리를 지정할 순 없음 | |
| spark = SparkSession.builder \ | |
| ... | |
| .config("spark.driver.memory", "9g") | |
| .getOrCreate() |
또한 spark.driver.cores 옵션의 경우 Cluster 에서만 적용되므로 Local / Client 와 같이 즉시 Driver JVM 을 실행하는 경우에는 SPARK_OPTS 환경 변수를 통해 Driver, Memory 옵션을 줄 수 있습니다.
| # 사용자 별 제공되는 Jupyter 컨테이너에 Jupyter Hub 리소스 타입별로 환경변수를 미리 세팅 | |
| SPARK_OPTS=--master=local[6] --driver-memory=20g |
Spark 문서 내에는 위 옵션들이 다음과 같이 표시되어 있습니다.
| spark.driver.cores | Number of cores to use for the driver process, only in cluster mode. |
| spark.driver.memory | In client mode, this config must not be set through the SparkConf directly in your application, because the driver JVM has already started at that point. Instead, please set this through the -driver-memory command line option or in your default properties file. |
만약 사내 사용자를 위해 Kubernetes 위에서 Jupyter Container 를 제공한다면 다음과 같이 설정해줄 수 있습니다.
- Spark Shell 이나 Spark Local / Client 모드 사용시 리소스를 잡아줄 수 있도록
SPARK_OPTS환경변수를 세팅하고 - 평소에는 Spot 을 사용하다가, 할당이 안되면 On-demand 를 쓸 수 있게 두 가지 옵션을 모두 제공합니다. (아래 코드에서는
ON_DEMAND만 표현)
| - display_name: "ML Type 1 [ON_DEMAND]" | |
| description: "Type 1 [ON_DEMAND] - Basic (CPU 2-6, Memory 20 GiB)" | |
| kubespawner_override: | |
| image: ... | |
| node_selector: | |
| ... | |
| eks.amazonaws.com/capacityType: ON_DEMAND | |
| cpu_limit: 6 | |
| cpu_guarantee: 2 | |
| mem_limit: '20G' | |
| mem_guarantee: '20G' | |
| environment: | |
| SPARK_OPTS: "--master=local[6] --driver-memory=20g --driver-java-options=-Dlog4j.logLevel=info" |
Question 9:
DataFrame 이 Immutable 하다는게 무슨 뜻인가요?
Spark SQL 또는 Spark DataFrame (Dataset) 사용시 사용자가 만든 코드는 Optimizer 에 의해 최적화 되고 결국 RDD 로 변경됩니다.
| df = spark.read.csv(...) | |
| dfSelected = df.selectExpr("...") | |
| df.rdd.id | |
| dfSelected.rdd.id |
결국 RDD 는 실행되는 코드로서. df.rdd.id 와 dfSelected.rdd.id 의 ID 가 다르다는 것은 실행될 내용이 다를 수 있다는 의미입니다. 둘은 같은 데이터를 이용해서 다른 작업을 수행할 수 있습니다.
Spark 에서 DataFrame 이 Immutable (불변) 하다는 이야기는, 하나의 DataFrame 에 Transformation 을 적용해도 이전 DataFrame 이 영향을 받지 않고 새로운 DataFrame 이 생성된다는 의미입니다.
만약 dfFiltered = df.where(..) 을 이용해 필터링을 수행했을때, 결과물인 dfFiltered 가 아니라 이전에 만든 df 가 필터링 된다면 사용자는 df 를 재활용할 수 있을까요?
dfFitlered.select(...).show() 를 통해 ‘확인만 하려고’ 했는데, select() 가 dfFiltered 에 적용되여 다른 컬럼이 삭제되면 dfFiltered DataFrame 을 재활용 할 수 없습니다.
Question 10:
Spark JDBC Write 를 이용할 때 DB Lock 이 걸리지 않을까요?
병렬 적재가 안되도록 Table 설계를 하거나, Record Lock 에 걸릴 기준으로 병렬 적재를 수행하면 Insert Lock 이 걸릴 수 있습니다. 예를 들어
- Auto Increment 를 사용하면 성능이 저하될 수 있고
- 동일한 Primary 키를 여러 Connection 에서 적재하는 경우 Record (= Row) Lock 이 걸릴 수 있습니다.
- https://www.letmecompile.com/mysql-innodb-lock-deadlock/ (MySQL InnoDB Lock)
- https://kukuta.tistory.com/215 (Insert Lock)
아래는 DDL 과 코드 샘플입니다. Insert lock 이 걸리지 않는 기준으로 컬럼 Repartitioning 을 먼저 수행해 데이터를 파티션별로 모아 (= Connection 별로) Write 하면 Lock 을 피할 수 있습니다.
| CREATE TABLE ... | |
| ( | |
| ... | |
| PRIMARY KEY (property_id, part) | |
| ) |
| # repartition 이 컬럼 기준 없이 되었으므로 | |
| # 동일한 property_id (e.g., 2101) 가 여러 Partition = Connection 에 나누어 Insert | |
| df\ | |
| .repartition(10)\ | |
| .write\ | |
| .mode("append")\ | |
| .format("jdbc")\ | |
| .option("numPartitions", "10") | |
| # property_id 기준으로 Partition 이 나뉘고 | |
| # 서로 다른 Partition = Connection 들은 동일한 property_id 값을 가지지 않습니다. | |
| df\ | |
| .repartition(10, "property_id")\ | |
| .write\ | |
| .mode("append")\ | |
| .format("jdbc")\ | |
| .option("numPartitions", "10") |
Insert 이외에도 RDS 에 데이터 적재시에는 고려해야 할 요소가 조금 더 있습니다.
A) 잘못 적재 했을 경우엔 어떻게 해야할까요?
DELETE 를 해야하는데, 전체를 할 수는 없고 금일 잘못 실행된 데이터만 삭제해야 한다면 데이터 업데이트 날짜를 표시하는 updated_at 같은 컬럼이 필요할까요? 또한 배치를 Immutable 하게 만드려면 항상 해당 날짜 데이터를 DELETE 후 APPEND 하면 어떨지도 고민해 봅시다.
B) 사용자가 데이터를 사용하는 와중에 삭제되는 것을 보지 않길 원할 때
Spark JDBC Data Source 를 이용하면 Append 혹은 Truncate Overwrite (테이블은 유지하고 데이터 전체 삭제 후 Append) 만 가능합니다.
따라서 Upsert 와 같은 내용을 구현하려면 foreachPartition 등을 이용해 직접 UPSERT (ON DUPLICATE KEY UPDATE, MERGE INTO) 를 이용할 수 있습니다.
대부분 기업의 Production 환경에서는 DB Table DDL 작성이나 Query 시에 DBA 검수를 받게 되어있으므로 잘 모르는 부분은 팀 내 숙련자의 가이드를 받고 DBA 의 검수를 통해 진행하는 편이 좋습니다.
Question 11:
Spark Streaming 등으로 HDFS / S3 에 File 을 계속 Append 하고 있을 때 다른 Spark 나 Presto 와 같은 Query Engine 등에서 변경된 파일을 읽으면 어떻게 됩니까?
Spark 가 S3 등 Storage 에 데이터를 적재할 경우 아래와 같은 과정을 거칩니다.
- Hive Metastore 를 이용하는 경우 File Listing 시점에는 있던 파일이 읽는 시점에 없으면 오류가 발생합니다. (리스팅 시점에 없던게 추가되어 있는 경우는 상관 없음)
- Hive Metastore 등을 사용하지 않고 직접 읽는 경우는, 읽는 시점에 존재하는 것을 읽습니다. 파일이 읽는 중에 S3 에서 사라지면 오류가 발생할 수 있습니다. (S3 등 Storage 가 주는 응답에 따라 상이) Hive Metastore 와 같이 Metastore 를 사용하지 않고 읽는 경우는 거의 없으며, ‘파일’ 자체를 그대로 읽는 문제가 발생할 수 있기 때문에 별도 실시간 데이터를 적재하고 있는 스토리지에서 데이터를 읽는 경우가 일반적입니다. (Kafka, Druid, ES 등) 참고로 Apache Iceberg 등을 이용하면 Versioning 된 형태로 파일을 읽을 수 있습니다.
- Spark 를 이용해 File 을 대상 경로에 쓰기 전에 Spark 의 FileOutputCommiter 가 임시 디렉토리에 (_temporary) 데이터를 지속적으로 Write 합니다. 작업이 완료되면 Rename 하기 때문에 (경로 이동) 중간 결과를 다른 시스템에서 읽을수는 없습니다.
- 다만 S3 의 경우에는 Rename 방식이 매우 느리므로 Hadoop 3.1 이상을 이용해 빌드된 Spark 데이터를 미리 올려놓고, 최후에만 POST 커맨드를 날리는 방식으로 데이터를 안전한 상태에서만 보여줍니다.
만약 File 변경이나 삭제에도 불구하고 데이터를 사용하는 시점에 오류가 없게 하거나 (Versioning), Re-wriet/ Upsert 등을 지원하려면 아래의 Table Format 이나 Storage Format 을 사용할 수 있습니다.
- Apache Iceberg 는 Table Format 으로서 Table Spec 에 대한 내용을 File 로 저장합니다. 따라서 Versioning 에 대한 내용들이 메타 파일에 별도로 저장되어 있어 변경시에도 Reader 는 문제없이 읽을 수 있으며, 과거 버전으로 돌아가는 것도 가능합니다.
- (Parquet File Format 과 다른 레이어, Parquet 는 데이터가 어떤 컬럼을 가지고 있는지 혹은 데이터에 대한 통계값 들을 저장)
- Apache Hudi 는 Storage Format 으로서 Transaction, Upsert, Incremental Processing 등을 지원합니다.
Question 12:
MySQL 이나 Hive Partition 과 Spark Partition 이 혼동됩니다. Spark Partition 을 변경하면 내가 읽는 물리적 파티션도 변경되나요? (원본 HDFS / S3 내의 Parquet, CSV 파일등의 숫자가 조절됩니까?)
MySQL, Hive 와 Spark 의 차이점을 이해하면 쉽습니다. MySQL, Hive 는 데이터 저장소로서 (혹은 메타 데이터) 이들 스토리지에서의 Partition 은 데이터를 물리적으로 어떻게 나눠야 할지 (그래서 어떻게 나누어 검색해야 할지) 를 정의합니다.
반대로 Spark 는 Processing 을 수행하는 컴퓨팅 엔진입니다. 따라서 Spark 에서의 Partition 은 데이터를 얼마나 나누어 처리할지를 정의합니다.
- MySQL / Hive 은 ‘스토리지’ 입니다. 즉 MySQL / Hive Partition 은 파일을 어떻게 “나누어 저장할지” 구조를 지정합니다. (디렉토리 경로, 인덱스 등)
- Spark 는 가공을 위한 ‘컴퓨팅 엔진’ 입니다. Partition 은 데이터를 어떻게 “나누어 처리할지” 를 결정합니다.
- 초기 결정된 Partition 만큼 병렬로 데이터를 읽고
- 중간 중간
repartition()/coalesce()등으로 조절되거나,spark.sql.shuffle.partition값에 의해 (Join, GroupBy) 컴퓨팅 시점에 병렬성이 조절됩니다. - 마지막으로 데이터 저장 직전 (save) 에 지정된 Partition 숫자 만큼 파일을 N 개 만들거나 저장소 커넥션을 사용합니다 (JDBC 등)
- 따라서 Spark 에서 repartition() 으로 파티션 숫자를 변경해도, Spark 가 읽을, 원본으로 존재하는 CSV 파일 숫자와 사이즈에 영향을 주지 않습니다. 만약 영향을 준다면 파일이 변경되므로 (..) 무시무시한 일이 발생합니다.
Question 13:
Spark Executor 를 위해 spark.executor.memory = 50g (50 GiB) 를 할당하면 정확히 50 GiB 만 할당되는걸까요? 50 GiB 를 사용 가능한 노드에서 Spark Executor 를 할당할 수 없다고 오류가 나옵니다.
Spark 에서 spark.executor.memory = 50g (Heap) 을 요청하면 Yarn 또는 Kubernetes 사용시에
- spark.executor.memoryOverhead (default = 0.1) 로 인해 10% 만큼 추가되어 55 GiB 가 필요합니다.
- 따라서 Yarn, Kubernetes 등에서 정확히 50 GiB 만 사용 가능하다면 할당이 되지 않습니다.
아래 그림을 통해 살펴볼 수 있습니다.
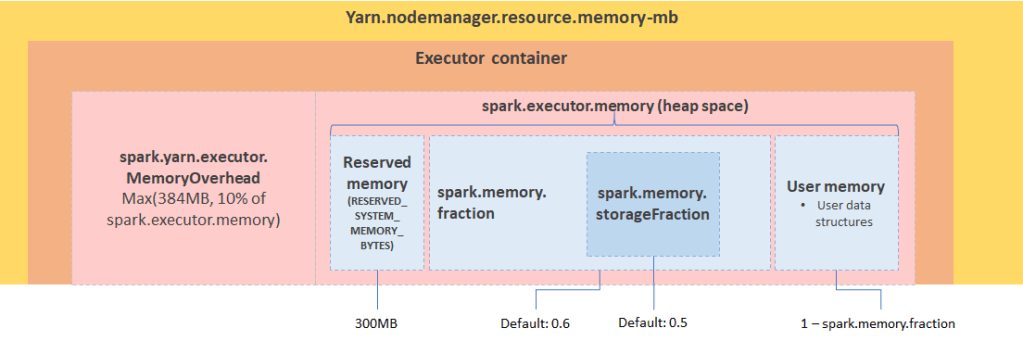
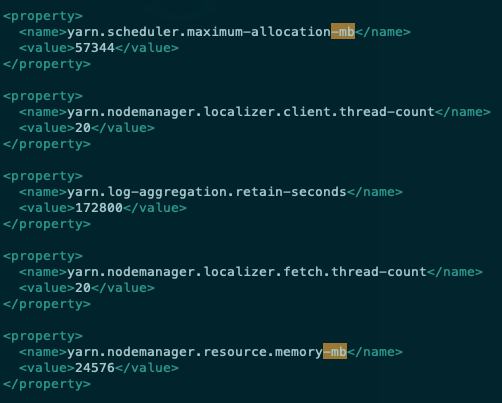
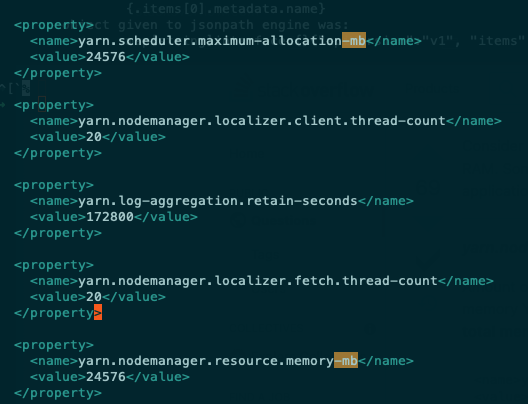
EMR Yarn 사용시 메모리 옵션이 자동으로 조절됩니다. (/etc/hadoop/conf/yarn-site.xml)
yarn.nodemanager.resource.memory-mb: EC2 머신 내 Yarn Container 들을 위한 최대 리소스 할당량
- EC 머신의 75% 사용 가능합니다.
- m5.2xlarge 32 GiB 기준 24576 (24 GiB)
yarn.scheduler.maximum-allocation-mb: 단일 Yarn Container 를 위한 최대 리소스 할당량
- 클러스터 생성 시점의 최대 Node 사이즈를 고려해 클러스터 전체 기준값이 정해집니다.
- Task 에 r5.2xlarge 64GiB, m5.4xlarge 64GiB 를 사용한다면 57344 (56 GiB, 87.5%)
아래 그림들은 EC2 머신 타입별로 Yarn 에서 할당 가능한 메모리가 실제 EC2 스펙보다 낮음을 보여줍니다.
Question 14:
DataFrame 을 그냥 사용하는것과 DataFrame.createOrReplaceTempView 로 View 로 만들어 사용하는 것의 성능 차이가 있을까요?
createOrReplaceTempView 함수를 이용하면 DataFrame 을 View 로 등록해 Spark SQL 을 사용할 수 있습니다. 예를 들어
| df = spark.read.(...) | |
| df.createOrReplaceTempView("PROPERTY_META") | |
| spark.sql("SELECT * FROM PROPERTY_META ..") |
대부분의 Production 환경에서는 데이터가 테이블로 존재하기 때문에 초기 데이터를 로딩한 DataFrame 을 View 로 등록할 일이 많지는 않습니다 (SPARK SQL 로 바로 로딩할 수 있으므로)
다만 중간 결과 DataFrame 을 등록해 사용자가 느끼기에 편리한 SQL 을 이용하거나 등의 경우 사용할 수 있습니다. DataFrame 을 사용하는 것과 성능상 차이가 없습니다. 🙂
Question 15:
Event 테이블은 사이즈가 커 캐싱이 어렵고, Meta 테이블은 사이즈가 작아 캐싱을 할 수 있다 하더라도 효과가 있는지 의문입니다. 언제 캐싱을 하는게 맞을까요?
Event 테이블은 DB 내 주문 Table 데이터나, Client 로그 내 상품 클릭 및 노출 등을 말합니다. 반면 Meta 테이블은 상품에 대한 정보를 가지고 있는 테이블을 말합니다. 예를 들어 면발 애호가를 위한 우동 커머스를 만든다고 하면
- (META) 우동 상품 정보: 우동 ID, 우동 면발 타입, 우동 제조사 등
- (EVENT) 우동 주문 정보: 사용자 ID, 주문 금액, 우동 ID 등
- (EVENT) 우동 앱 사용자 정보: 사용자 ID, 우동 ID, 노출 시점, 노출 시점시 광고 정보 등
작은 테이블은 로딩 직후에 (read) 캐싱할수도 있겠으나 실제로는 데이터가 크기에 cache() 함수는 다음 경우에 많이 사용합니다.
- 데이터를 Filter, Select 등을 통해 사이즈를 줄인 후
- 데이터를 Join 해서 원하는 모양으로 합친 후
- 데이터를 Group By 등으로 필요한 부분만 집계 후
따라서 cache() 를 호출하는 영역이 데이터 로딩 직후에만 있거나 코드의 상단부에만 존재하진 않습니다.
또한 Meta 테이블이 작다는 표현은, Event 테이블보다 “상대적” 으로 작다는 의미입니다. 회사의 데이터 규모에 따라 상품 메타 테이블도 클 수 있습니다
- (Redis 21억개 상품, 쿠팡) https://charsyam.wordpress.com/2019/08/26/입-개발-redis-버그-dataset-사이즈가-200gb가-넘어가면-죽는다구요/?fbclid=IwAR0GWR0fH7AlA9LLvuBwRAe6OB1cG_LGum55EJe68Y59oTAEkCO7jyVnxzo
cache() 에 대한 일반적인 가이드는 다음과 같습니다. (IBM: Spark Performance Optimization)
- 자주 호출되는 DataFrame 은 캐싱합니다. 조인의 기준축인 상품 메타 테이블일 수도 있고 이벤트 테이블을 Filter, Select, Group By 등으로 줄인 DataFrame 일 수도 있습니다.
- 요지는 ‘자주 접근되는’, ‘전체 메모리 관점에서 캐싱하기에 충분한’ DataFrame 을 캐싱합니다.
- 반대로 한번만 사용되는 DataFrame 은 캐싱할 필요가 없습니다.
Spark SQL 을 이용할 때 CACHE 구문을 이용하면 즉시 캐싱되지만, DataFrame 의 cache() 는 사용자가 Action 을 호출할 때 수행됩니다. 따라서 간혹 아래와 같은 질문을 주시는 분들이 있습니다.
- 참고) LAZY CACHE 구문을 이용하면 DataFrame 의
cache()와 동일한 효과를 낼 수 있습니다.
“Action 을 호출해야만 캐싱이 실행된다면, count() 와 같은 Action 을 주기적으로 호출해야 하나요? 언제 Action 이 수행되는지 궁금합니다.”
대부분의 경우 사용자는 최종적으로 Write 와 같은 Action 을 결국엔 호출하기 때문에 직접 count() 를 호출할 필요가 없습니다. 인터넷에서 찾을 수 있는 예제에서 사용하는 count() 는 캐싱을 보여주기 위한 하나의 Action 예시입니다.
| dfInitial = spark.read(...) | |
| dfFiltered = dfInitial.select(...).where(..).cache() # 캐시 호출 | |
| dfJoined = (...) | |
| # action 호출 | |
| # Transformation 이 실행되며 dfFiltered 를 계산후 | |
| # dfFiltered 를 여러대 나눠진 Executor 에서 메모리에 캐싱 | |
| dfJoined.write(...) |
Question 16:
Spark 에서 Off-heap, On-heap OOM 이 발생합니다. 어떤 옵션을 조절해야 할까요?
| ExecutorLostFailure (executor 7 exited caused by one of the running tasks) Reason: | |
| Container killed by YARN for exceeding memory limits. 33.2 GB of 33 GB physical memory used. | |
| Consider boosting spark.yarn.executor.memoryOverhead or disabling yarn.nodemanager.vmem-check-enabled because of YARN-4714. |
위와 같은 오류 메세지가 발생했을 때 어떤 옵션을 조절하면 좋을지 고민해 봅시다.
현재 Spark 에서 사용하고 있는 설정은 다음과 같습니다. (Spark Version 은 2.4.8 을 사용하고 있습니다.)
| spark.executor.instances = 10 | |
| spark.executor.cores = 10 | |
| spark.executor.memory = 30g (GiB) | |
| spark.memory.memoryOverhead = 0.1 | |
| spark.memory.fraction = 0.8 | |
| spark.memory.storageFraction = 0.5 | |
| spark.memory.offHeap.enabled = false |
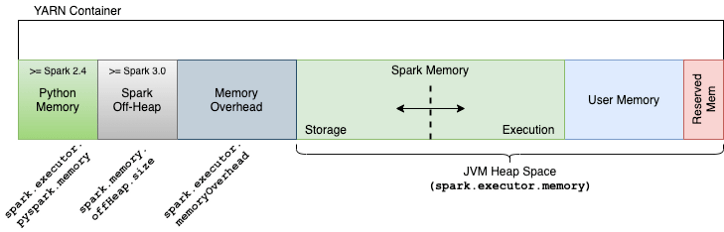
위 그림은 Spark 버전별 Memory 영역을 보여줍니다. 현재 2.4.8 버전을 사용하고 있으므로 그림에서 spark.memory.offheap.size 는 별도로 존재하지 않습니다. (또한 Off-heap enabled = false)
추가적으로 spark.executor.pyspark.memory 를 따로 잡아줬다면 Off-heap 사용량에 영향이 있을수도 있겠지만 현재는 Scala Spark 이며 spark.executor.pyspark.memory 는 따로 잡아주지 않았습니다.
다음은 메모리 옵션을 수정하기 전 생각해볼 만한 몇 가지 가설입니다.
- Join, Aggregation 등에서 Memory 가 터졌다면 Heap OOM 메세지가 발생했을 것이다.
- 그리고 Heap 을 사용하는 컴퓨팅에서는 Memory 가 넘친다면 Disk Spill 을 이용해 속도는 느리겠지만 집계할 수 있다.
- 따라서 Heap OOM 이었다면 Spill 이 불가능한 부분을 포함하는 연산이거나 (
Unique Distinct,Shuffle Hash Join 등) 그 정도가 과해 터졌을 수 있다 (e.g, Window Function 등) - Write 하는 과정에서 터졌다면, 특정 Execurtor 내 파티션에 데이터가 몰린걸까? (Skew) 그렇다면 어떻게 해결할 수 있을까? 데이터 내에는 사용자 ID 및 사용자가 발생시킨 이벤트 타입과 시간 값이 있다.
- 데이터를 Write 하는 3rd Party (Parquet 등) 의 경우에는 Off-heap 을 쓰는 경우가 종종 있고, 이로 인해 오류가 날 수 있다.
Off-heap 에서 오류가 났으므로 전체 메모리 사이즈는 동일하게 유지하고 On-heap 을 줄여 Off-heap 을 늘려보기로 했습니다.
- spark.executor.memory = 25g (GiB)
- spark.memory.memoryOverhead = 8g (GiB)
- 전체 = 33 GiB 로 기존과 동일
수정후에는 이제 Off-heap 이 아니라 Heap OOM 이 발생합니다.
| RECEIVED SIGNAL TERM | |
| 21/11/26 23:19:51 ERROR util.SparkUncaughtExceptionHandler: Uncaught exception in thread Thread[read-ahead,5,main] | |
| java.lang.OutOfMemoryError: Java heap space | |
| at net.jpountz.lz4.LZ4BlockInputStream.refill(LZ4BlockInputStream.java:243) | |
| at net.jpountz.lz4.LZ4BlockInputStream.read(LZ4BlockInputStream.java:157) | |
| at org.apache.spark.io.ReadAheadInputStream$1.run(ReadAheadInputStream.java:168) | |
| at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) | |
| at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) | |
| at java.lang.Thread.run(Thread.java:745) |
Heap OOM 은 다음 부분들을 고려해 수정할 수 있습니다.
- spark.executor.memory 를 줄이면, 메모리 영역중 Execution 메모리 (Group by, Window 등 Aggregation 을 위한) 가 줄어듭니다. 어떤 영향이 있을까요?
- 만약 메모리는 넉넉한데 Group By, Window Function 등에서 Skew 가 발생한다면 어떤 옵션을 수정하는 것이 좋을까요?
- 1)
spark.sql.shuffle.partitions숫자를 늘려 Skew 확률을 낮춘다. - 2) Group By, Window Function 전 해당 집계에서 사용하는 Key 를 기준으로 repartition(X, “key”) 를 진행한다.
- 1)

이런 개꿀 정보를 감사합니다
LikeLiked by 1 person
감사합니다. 새해 복 많이 받으세요. ^^
LikeLiked by 1 person
안녕하세요 답변이 달릴지는 모르겠지만 질문이 있어 댓글 남깁니다..
파티셔닝이 되지 않은 Hive 테이블을 Spark에서 읽을 때는 데이터 파일 개수 만큼 Task가 생성되는데요
똑같이 파티셔닝이 되지 않은 Iceberg 테이블을 Spark에서 읽을 때는 Task 개수가 적어집니다
repartition() 을 사용해도 늘지를 않네요..
Iceberg 테이블 사이즈에 따라 Task 가 늘기는 하는데 그래도 Hive 테이블을 읽을 때 보다는 현저하게 느려집니다.
이유가 무엇인지 혹시 아시는지요..
데이터 파일은 MinIO 에 저장하고 있습니다.
LikeLike
안녕하세요. 선생님. 제가 먹고사느라 바빠서 댓글을 지금보고 답변을 달게 되었습니다. 죄송합니다.
Spark 에서 Hive Table (Parquet File 파일이라 가정) 을 읽을 때 파티션의 갯수는 아래 문서에 기재된
spark.sql.files옵션들에 의해 좌우됩니다.– https://spark.apache.org/docs/latest/sql-performance-tuning.html#other-configuration-options
그 중에서 spark.sql.files.maxPartitionBytes 에 의해 파티션의 숫자가 정해지고 이 파티션이 런타임에 Task 에 할당되므로 일반적으로 1 Task 는 한 시점에 128 MB 의 데이터를 읽어 처리한다고 말할 수 있습니다. (Parquet 파일은 많은 경우 128 MB+ 이상이며 256 MB, 512 MB 등의 사이즈를 가지기 때문)
Iceberg 의 경우에는 조금 다릅니다. Spark 는 파일을 읽는 것이 아니라 테이블을 읽기 때문에 Iceberg 의 옵션인
read.split.target-size에 의해 좌우됩니다. 그리고 이 값은 Parquet 의 Row Group 보다 작을 수 없습니다. (단일 Parquet 파일에서 최소 Row Group 단위로 읽기 때문)– https://iceberg.apache.org/docs/latest/configuration/
따라서 제가 선생님께서 설정하진 옵션은 정확히 알지 못하겠으나 Parquet 파일만큼 Task 가 생긴다고 말씀하신걸 봐서 개별 Parquet 파일은 128 MB 사이즈를 가지고 있는 것 같습니다. Iceberg 의 경우에는 더 Task 가 작다고 말씀하신걸 보니 테이블 수준에서 Pruning 이 일어나 실제 읽어야 할 데이터의 사이즈를 줄여서 더 적게 읽는게 아닌가 싶습니다. (“느리다” 고 말씀하신 부분이 전체 처리 시간이 아니라 Task 숫자가 줄어서 느려보인다고 말씀하신것으로 이해)
위 옵션들을 살펴보시고 추가적인 정보를 더 주신다면 답변을 드릴 수 있을 것 같습니다. 좋은 주말 보내세요!
LikeLike
안녕하세요 좋은 글 정말 감사드립니다.
이해가 되지 않는 부분이 있어서 질문 드릴 수 있을까 하여 코멘트 남깁니다
첫 번째로 Question 2 최하단의 ‘Kubernetes 를 쓸 경우, Node 내의 1 개의 Pod이 Executor 가 됩니다’ 이 부분에서 문맥상 Driver 가 되어야 하지 않나 하여 여쭈어봅니다
두 번째로 16번 항목 내에 Spill 이 불가능한 연산으로 Unique Distinct, Shuffle Hash Join 를 언급해 주셨는데, 관련 내용을 아무리 찾아도 찾을 수가 없어서 혹시 부연설명이나 참고자료를 여쭤볼수 있을까요?
블로그 내 많은 글들 정독하고 정말 많이 감탄합니다.
좋은 하루 되세요
LikeLike
안녕하세요. matdulgi 님.
(1) 이해하신 내용이 맞습니다! Driver 1개가 올바른 문장인데, 급하게 작성하다 보니 놓친 것 같습니다. 수정할 수 있도록 하겠습니다. ^^
(2) 이해하신 것 처럼 Shuffle Hash Join 에서도 Shuffle Spill 이 일어나는 것은 당연한데, 제가 Heap OOM 이 날 수 있는 케이스에 대해 설명하면서 문장을 잘못 적은 것이 맞습니다.
Shuffle Hash Join 과정에서 Build-side 가 메모리에 위치해야 하므로, 이 부분은 다른 조인과 달리 Spill 이 될 수 없어 Heap OOM 이 날 수 있는데, 이 부분을 Shuffle Hash Join 전체에서 Spill 이 발생하지 않는다고 오해할 수 있도록 적은 것 같습니다. (참고 자료를 문의 주셔서 https://issues.apache.org/jira/browse/SPARK-32634 링크도 같이 전달 드립니다.)
`Unique Distinct` 는 제가 적을 당시에 어떤 생각을 하면서 적었을 것 같은데 (..) 저도 조금 더 찾아보고 답변을 달 수 있도록 하겠습니다.
좋은 밤 되세요!
LikeLike