Practical 시리즈는 AWS 환경 위에서 데이터 인프라를 구축하는데 참고할만한 내용들을 담고 있습니다. 이 글은 그 중 Practical Kafka 의 한 챕터입니다.이번 챕터에서는 Spark / Flink Streaming 시스템에서 많이 활용되는 컴포넌트인 Kafka 의 기본적인 개념에 대해 알아봅니다. AWS Kinesis 와 가벼운 비교를 통해 Kafka 가 어떤 강점이 있는지 알아보고, Kafka 의 논리적인 구성요소인 Broker, Consumer, Producer, Partition, Offset,…

Practical 시리즈는 AWS 환경 위에서 데이터 인프라를 구축하는데 참고할만한 내용들을 담고 있습니다. 아래의 내용들을 주로 다룹니다.
- Practical Spark
- Practical Kafka
- Practical Kubernetes
- Practical AWS
이 블로그에 작성된 내용은 위 시리즈 중 Gitbook 으로 작성된 Practical Kafka 를 옮긴 것입니다. 원본 Gitbook 와 실습에 사용하는 코드는 아래의 링크에서 보실 수 있습니다.
- (Spark Batch) https://1ambda.gitbook.io/practical-data-pipeline/02-processing/2.2-batch
- (Spark Stream) https://1ambda.gitbook.io/practical-data-pipeline/02-processing/2.4-stream
- (Code) https://github.com/1ambda/practical-data-pipeline-code
Kafka and Kinesis
이번 챕터에서는 Streaming 컴퓨팅의 데이터 소스로 활용되는 Kafka 에 대해 알아보겠습니다. 실시간 데이터는 주로 Kafka / Kinesis 등의 스토리지에 저장되어 있으며, Spark / Flink 에서는 Kafka 가 Built-in 데이터 소스로 지원됩니다.
Streaming 시스템의 데이터 저장소 (Queue) 로서 Kafka 이외에도 Kinesis 도 종종 활용되곤 합니다. 사용자 입장에서 AWS Kinesis 와 Kafka 는 어떻게 다를까요?
일반적으로 대량의, 비정형 데이터를 받는 용도로 Kafka 와 같은 Queue 를 많이 사용합니다.
- 그러나 최소 비용이 많이 필요할 수 있습니다. Kafka 는 3대 이상의 클러스터로 운영해야 하고 Zookeeper 클러스터도 필요하기 때문입니다. (Kafka 2.X 기준)
- 또한 Kafka 운영 및 모니터링에 노동비용이 많이 필요할 수 있습니다.
- AWS 에서는 관리형 Kafka 로 AWS MSK 를 제공해 수 있어, 업그레이드 및 스케일링으로 인한 노동 비용을 줄이고 모니터링을 편리하게 할 수 있습니다.
Client (App / Web) 이벤트만 전송하고, 비용 문제로 인해 Kafka 사용이 어렵다면 AWS Kinesis 도 좋은 대안이 될 수 있습니다.
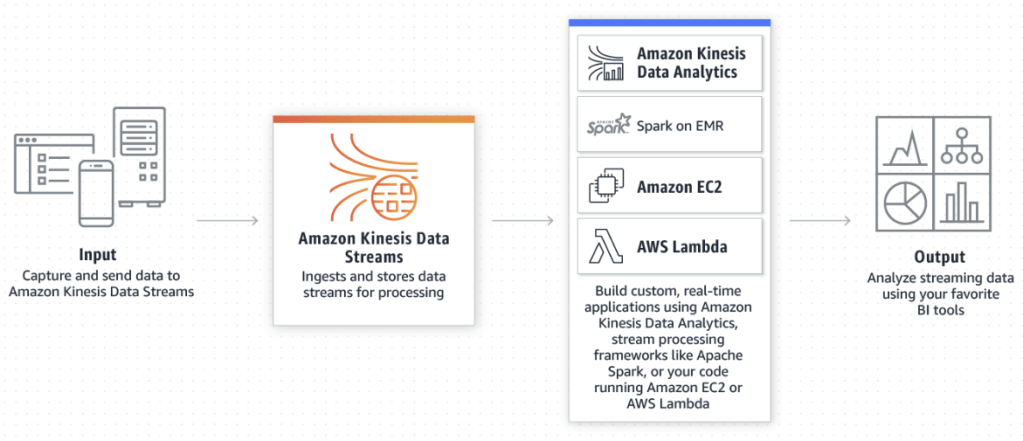
AWS Kinesis 는 비용도 매우 저렴하고, Client 에서 Kinesis 로 바로 전송할 수 있습니다. 이를 위한 SDK 도 Android / iOS / Web (Javascript) 조재합니다.
- AWS Kinesis Pricing 에서 볼 수 있듯이, 서울 리전 기준으로 초당 1MB 쓰기, 2MB 읽기에 대해 단위 (Shard) 당 월 $13.3 정도입니다.
- AWS Kinesis Client – Javascript, AWS Kinesis Client – iOS, AWS Kinesis Client – Java
다만, 아래와 같은 제한점이 존재합니다.
- AWS Kinesis Stream Limitation 에서 알 수 있듯이 샤드당, 최대 초당 1천개까지 쓰기가 가능합니다.
- 읽기의 경우에도 제한이 존재하며, Consumer 가 많이 붙는 경우에는 Write 가 적음에도 Shard 를 늘려야 합니다.
- Shard 당 읽기 제한을 Consumer 간 공유하지 않으려면 Enhanced Fan-out 을 사용할 수 있습니다. 그러나 별도 세팅이 필요하니, 노동 관점에서 비용이 듭니다.
- 오픈소스이며 수 많은 곳에서 사용되는 Kafka 와 비교해 Connector, 즉 Consumer 라이브러리의 성숙도가 낮거나 없는 경우가 있습니다.
- 예를 들어 Spark 의 경우에는 공식적으로 Kinesis 를 위한 Structured Streaming API 를 지원하지 않습니다. (https://spark.apache.org/docs/latest/streaming-kinesis-integration.html)
- DataBricks 런타임을 이용하거나, Qubole 의 Kinesis SQL 등 서드파티를 이용해야 합니다.
따라 사내 메인 이벤트 브로커로 Kafka 를 사용하고 Client 이벤트만 Kinesis 로 받아 Kafka 로 Relay 해 사용한다면
- 공식적으로 지원되는 Connector 를 활용할 수 있는 여지가 많아집니다.
- 별도 Fan-out 등 세팅할 필요가 없어지며, Broker 리소스가 충분하다면 Kinesis 비해 메세지 쓰기 / 읽기 숫자에서 Limit 이 넉넉합니다.
- Kafka Schema Registry 와 Avro 등 Kafka 생태계 내의 시스템들을 활용할 수 있습니다.
- Kinesis 사용시 AWS 다른 계정간 IAM 접근이 불편해지는 반면, 모든 데이터를 Kafka 로 모은다면 Network 기반으로 접근 제어가 가능해집니다.
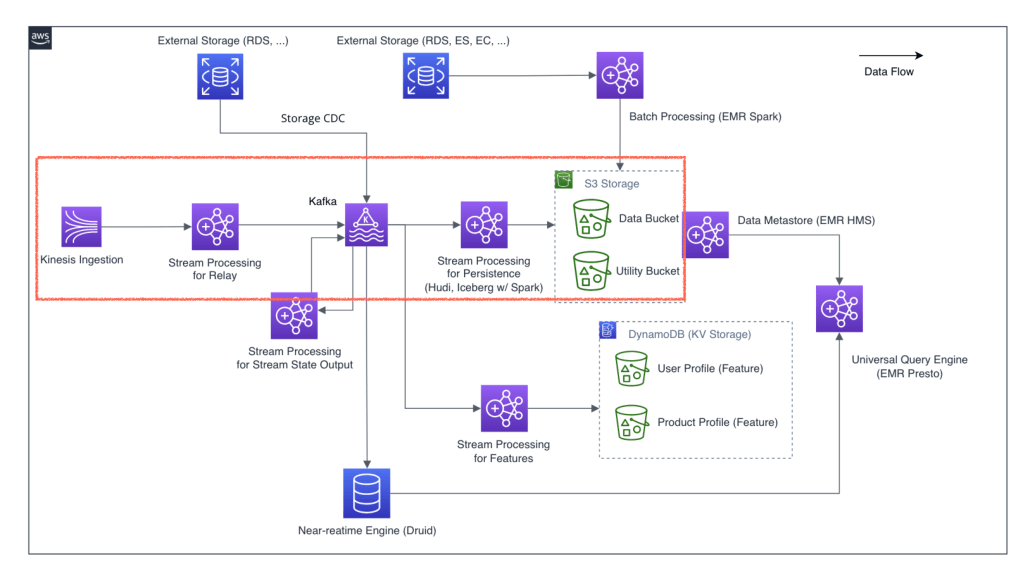
위 그림은 Client (App / Web) 이벤트 데이터는 Kinesis 로 보내고, Server 이벤트 또는 Storage CDC 등은 Kafka 로 직접 보내는것을 보여줍니다. Kinesis 이벤트는 Kafka 로 Relay 해 Spark / Flink 등 팀에서 사용하는 프레임워크로 한 곳에서 쉽게 가공하는 것을 볼 수 있습니다.
Kafka Architecture
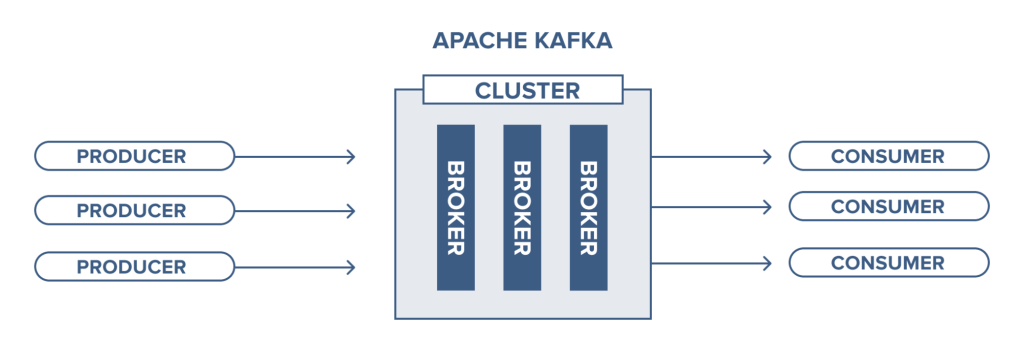
Kafka 는 Clustering 이 가능한 Message Broker 입니다.
- Clustering 이 가능하므로 Broker 를 더 붙여 확장 (Scalable) 이 가능합니다.
- Clustering 을 한다는 의미는 데이터를 여러벌로 복제하거나 (Replicated)
- 다양한 Broker 에서 나누어 읽고 쓸 수 있다는 뜻입니다. (Distributed)
- Clustering 을 위한 추가적인 컴포넌트인 Zookeeper (이하 ZK) 를 사용합니다.
참고로 Kafka 2.8+ 부터 Zookeeper 없이 테스트 모드로 실행해 볼 수 있습니다.그러나 2021년 기준으로 아직 많은 곳에서 Zookeeper 를 같이 사용합니다.
- Confluent: Apache Kafka Made Simple: A First Glimpse of a Kafka Without ZooKeeper
- KIP-500: Replace ZooKeeper with a Self-Managed Metadata Quorum
Kafka 를 통해 여러 Application 들은 메세지를 주고 받을 수 있습니다.
- 데이터를 전송하는 Application 을 Kafka Procucer
- 데이터를 받아서 처리하는 Application 을 Kafka Consumer 라 부릅니다.
- Kafka 가 제공하는 API 를 이용해 다양한 언어 / 프레임워크의 Producer / Consumer 가 존재합니다.
- Kafka Golang Library (confluent-kafka-go)
- Spark SQL Kafka Integration (github/spark/external/kafka-0-10-sql)
- Spark Streaming Kafka Integration (github/spark/external/kafka-0-10)
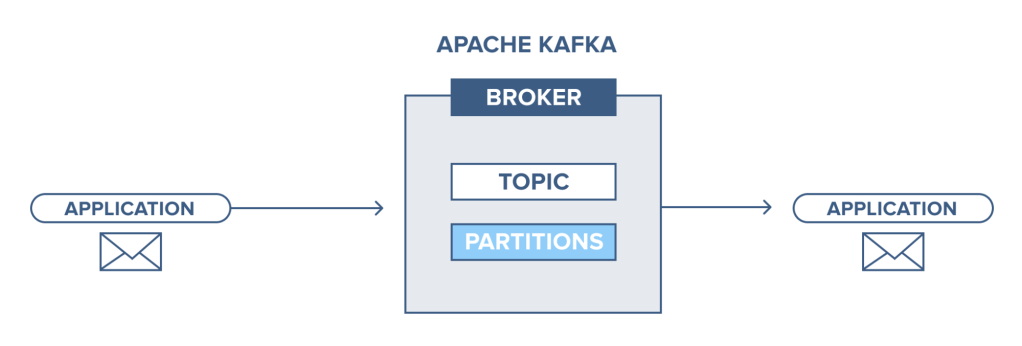
Kafka 에서 Producer 와 Consumer 는 데이터를 구분하기 위해 ‘Topic‘ 을 지정합니다. 다른 종류의 메세지는 다른 Topic 으로 보낼 수 있습니다.
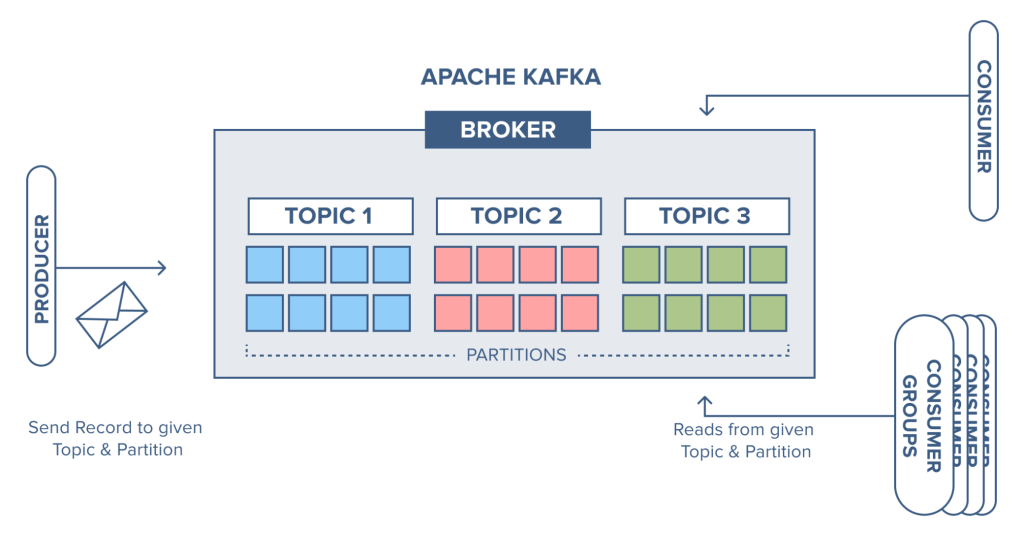
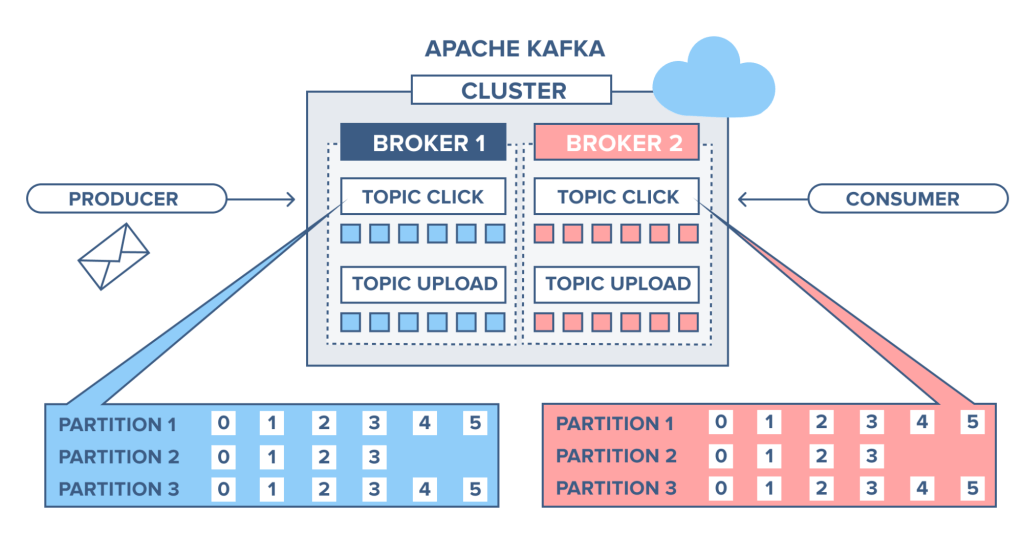
Kafka Partition
하나의 Topic 을 나누어 Partition 을 여러개 만들 수 있습니다. Spark DataFrame 의 Partition 과 유사하게, 데이터를 나누어 처리하는 단위입니다.
- Spark 에서 Partition 수를 조절해 Executor 에서 분산 처리 할 수 있고
- Spark 에서 Partition 수를 조절해 Executor 내 메모리에 캐싱할 수 있습니다.
- Kafka 에서 Topic 의 Partition 수를 조절해 Broker 내에서 나누어 저장할 수 있고
- Kafka 에서 Topic 의 Partition 수를 조절해 Producer / Consumer 에서 병렬성을 조절할 수 있습니다.
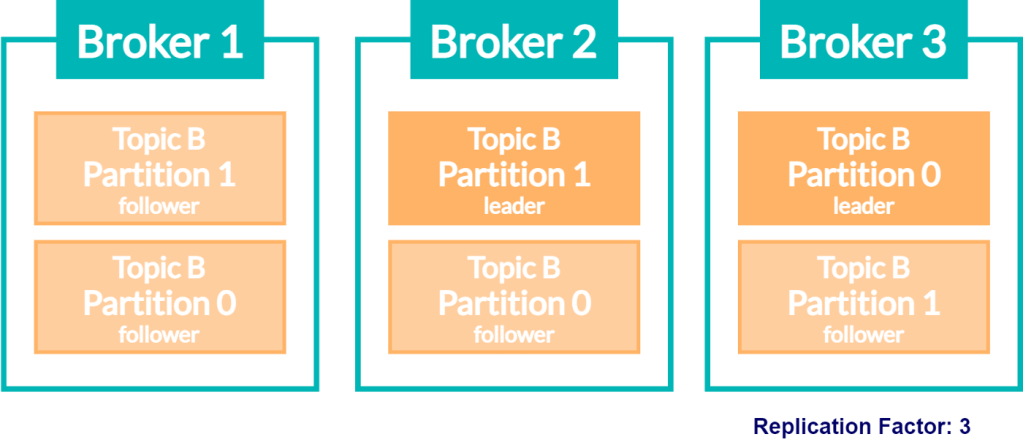
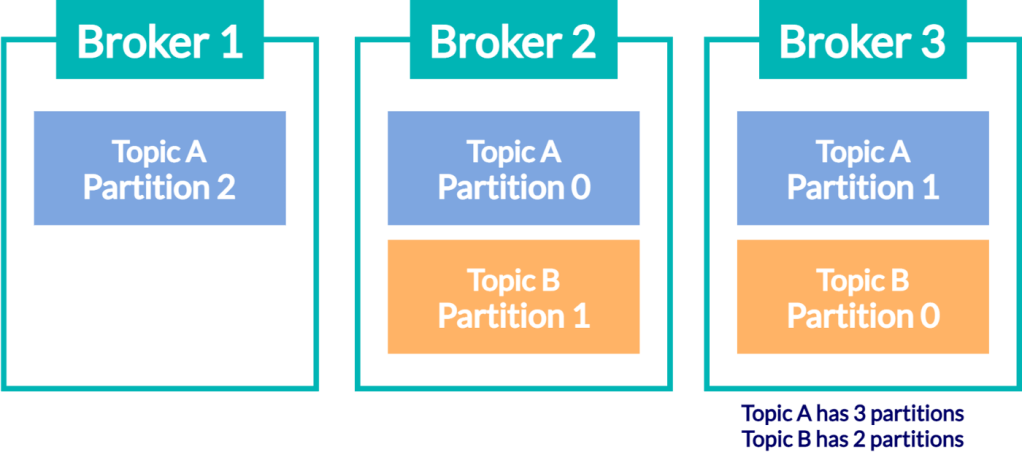
파티션을 복제 (Replication) 하는 것도 가능합니다. 이를 통해 Broker 2 가 다운되어 (Topic B – Partition 0) 와 (Topic B – Partition 1) 를 잃어버려도 다른 Broker 에 복제되어 있으므로 복구가 가능합니다.
- Leader: 복제된 동일한 여러 Partition 소유한 Broker 중 하나의 Broker 가 Leader 로 선택됩니다. Leader 는 모든 Write / Read 에 대한 요청을 처리합니다.
- Follower: Leader 의 Partition 에 Write 되는 데이터를 지속적으로 복제하며 따라갑니다. 만약 Leader 에 문제가 생겨 사용할 수 없는 상태가 되면, 여러 Follower 중 하나가 선택되어 Leader 가 됩니다. 이 과정을 Leader Election 이라 부릅니다.
분산 스토리지에서는 대부분 복제 (Replication) 라는 컨셉을 가지고 있습니다.
- HDFS 에서는
dfs.replication을 통해 복제본 숫자를 지정할 수 있습니다. - Kafka 에서는 replication.factor 라는 이름의 옵션으로 파티션이 복제됩니다. 3 일 경우 원본을 포함해 3개입니다.
- ElaticSerach 에서는 데이터의 분할 단위가 Shard 이며
number_of_replicas옵션을 통해 Shard 를 복제할 수 있습니다. 특이하게도 replica 3 일 경우 원본과 3개의 복제본을 만듭니다.
복제 (Replication) 를 통한 안전성과 처리량 관점에서 다음을 생각해 봅시다. 만약 Replication Factor (복제본 숫자) = 3 일때
- Producer 가 메세지를 Partition Leader 에게 보내고, Partition Follower 가 복제하기 전에 다음 메세지를 보낸다면 처리량은 어떨까요?
- Producer 가 메세지를 Partition Leader 에게 보낸 후 Partition Follow 가 전부 복제한 후에야 다음 메세지를 보낼 수 있다면 안전성은 어떨까요?
아래의 옵션들을 인터넷에서 찾아보며 각 설정에 따라 어떻게 동작할지 논의해 봅시다.
- (Kafka Producer)
acks= 0, 1, all - (Kafka Broker)
min.insync.replicas
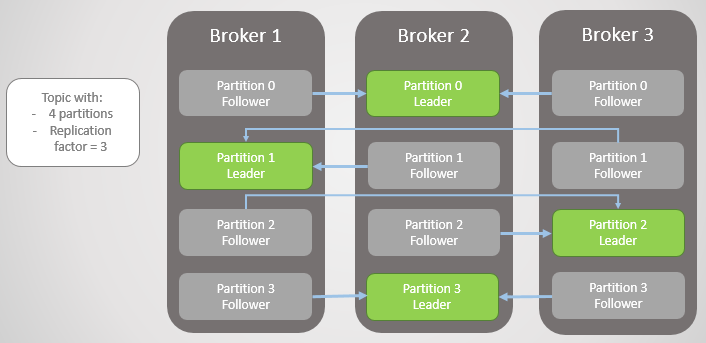
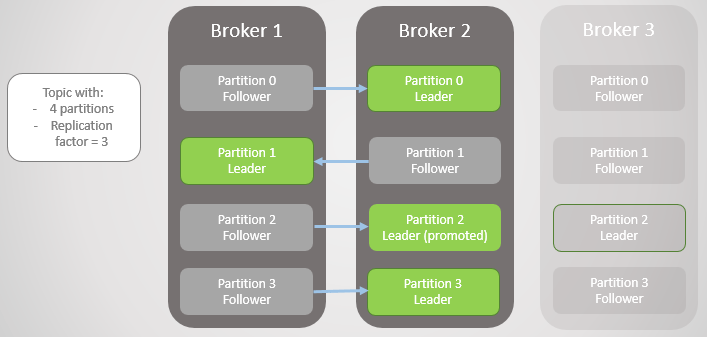
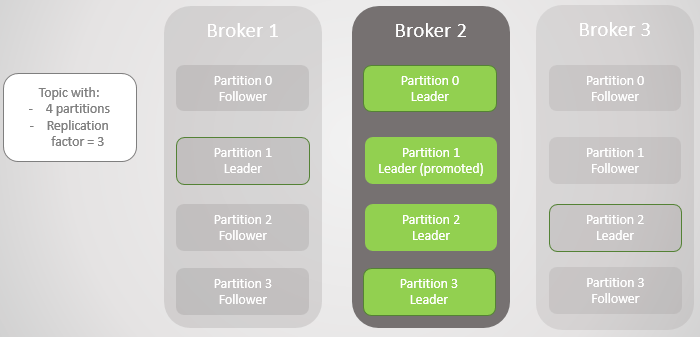
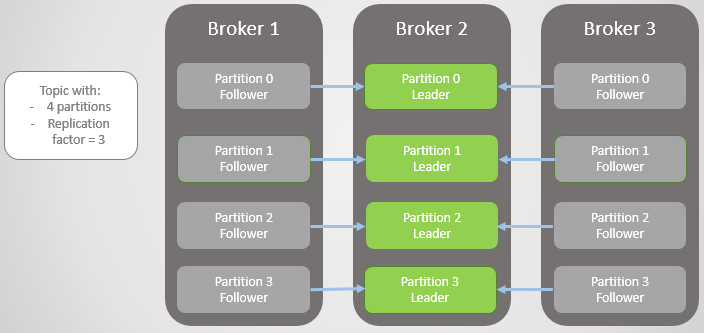
위 그림에서는 Broker 1, 3 가 이 죽을경우 각 파티션별 Leader 가 Broker 2 번이 되는 경우를 보여줍니다. 이 경우 Broker 2번이 죽으면 전체 Partition 에 문제가 생길텐데, Partitoin Leader 를 변경할 수 있는 방법이 있을까요?
- Kafka 에서 제공하는 도구인 kafka-reassign-partitions 를 살펴봅시다.
- 사내에서 UI 도구 (Kafka Manager 등) 을 이용해 파티션 할당을 수행할 수도 있습니다.
| {"version":1, | |
| "partitions": | |
| [{"topic":"mytopic1","partition":3,"replicas":[4,5],"log_dirs":["any","any"]}, | |
| {"topic":"mytopic1","partition":1,"replicas":[5,4],"log_dirs":["any","any"]}, | |
| {"topic":"mytopic2","partition":2,"replicas":[6,5],"log_dirs":["any","any"]}] | |
| } |
Broker 가 우연히 죽는 경우를 제외하고, 언제 파티션을 다시 Re-assign 할 수 있을까요?
- Partition 이 늘어나는 경우에는 파티션을 다시 재할당해야 할 수 있을까요?
- Broker 변경시 (Upgrade / 물리장비 교체 등) 에는 어떨까요?
Partition Offset
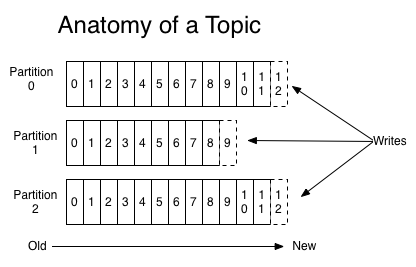
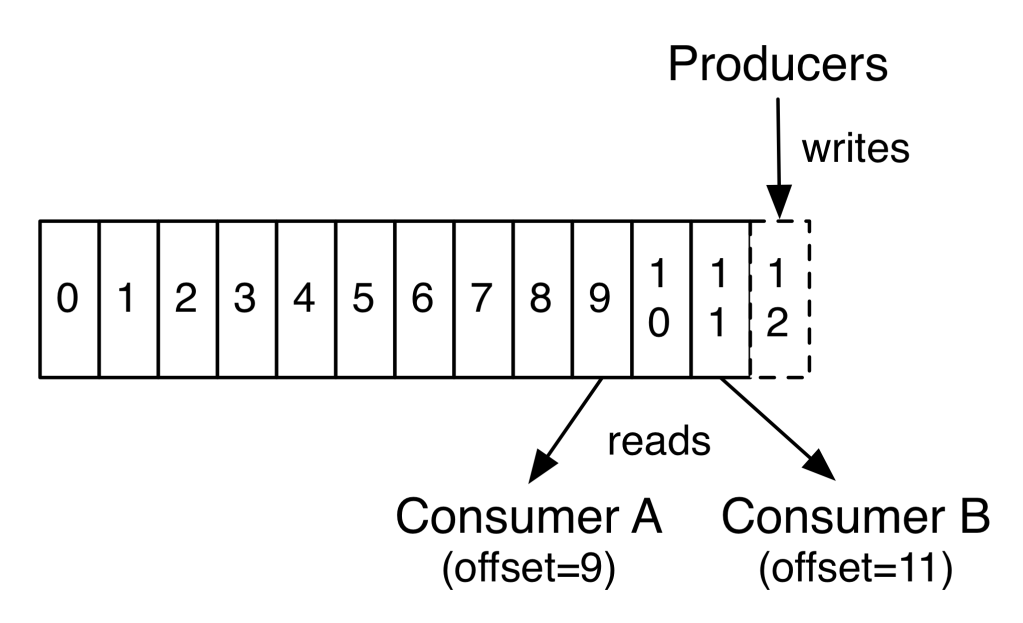
Topic 은 여러개 Partition 으로 나뉘어 여러 Broker 에서 분산으로 Write 되고 Read 될 수 있습니다.
- 이때 하나의 Partition 은 메세지가 증가할 때 마다 Offset 값을 늘려가며 메세지를 저장합니다.
- 그리고 Consumer 는 Offset 을 따라가며 메세지를 처리하고, 자신이 어디까지 처리했는지를 보관합니다.
- Offset 을 일종의 ‘메세지 번호’ 로 생각할 수 있습니다.
위 그림 ‘Partition Offset’ 에서는 하나의 Producer 에서 여러개의 Partition 을 사용할 경우를 보여줍니다.
아래 그림 ‘Partition Offset and Consumer’ 에서는 동일한 Topic 내 동일한 Partition 에 대해 서로 다른 Consumer A, B 가 붙어 동일한 메세지를 두번씩 처리하는 것을 보여줍니다. Kafka 에서는 Consumer Group 이 다를 경우 Consumer 가 메세지를 재처리할 수 있습니다.
예를 들어
- 상품 재고 숫자를 Seller Office 등에서 변경 했을때
product-inventory라는 이름의 Topic 으로 메세지를 발행하고 producer-inventory토픽을 서로 다른 두개의 서비스product-catalog(B2C 서비스 앱 내 재고를 담당),product-sourcing(구글 호텔 등 외부 서비스의 인벤토리로 데이터 전달) 가 소비할 수 있습니다.
Consumer Group
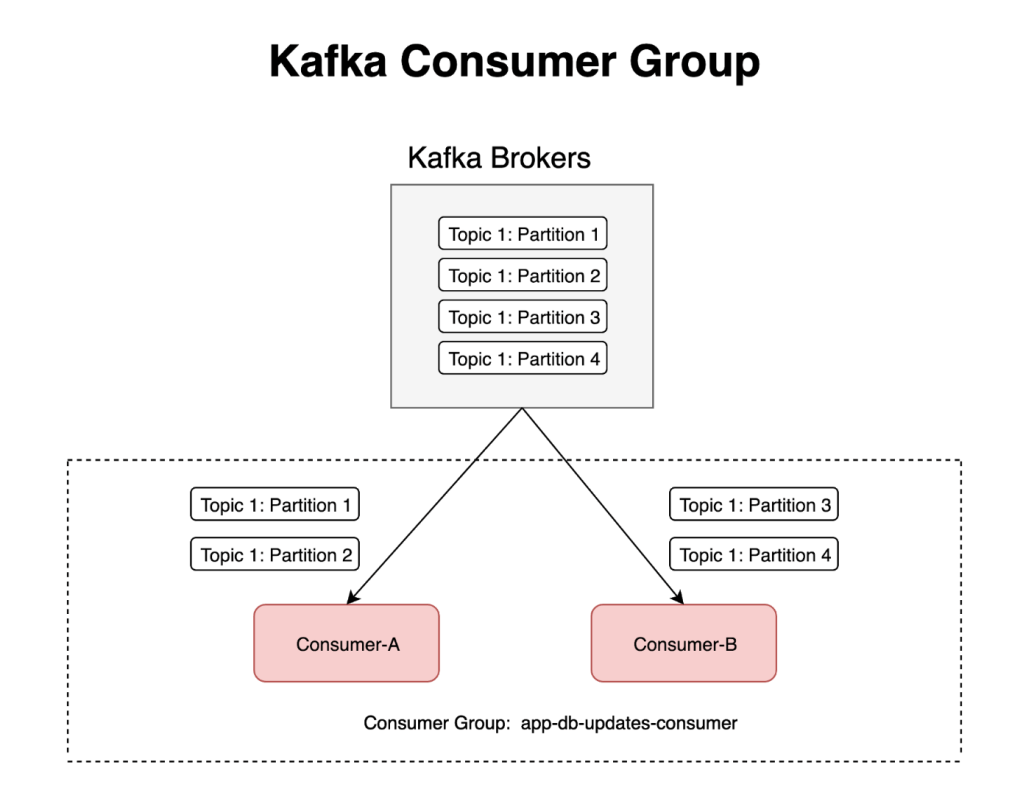
하나의 Consumer Group = app-db-updates-consumer 내에서 보면 위 그림과 같습니다.
- Consumer A, B 모두 동일한 Topic 을 처리합니다.
- Partition 숫자가 4개이므로 Consumer A, B 가 파티션을 나누어 할당 받을 수 있습니다.
- Broker 숫자는 나와있지 않으나 Broker 는 1개일수도, 여러개일 수도 있습니다. 이에 따라 Read / Write 요청이 여러 Broker 에 분산될 수 있습니다.
Java 기준으로 그림상 1개의 Consumer 는 1개의 Thread 라고 보아도 좋습니다. Partition Read 1 Thread, Processing N Thread 처럼 Partition 당 N 개의 스레드를 가져갈 수 있으나 여기서는 논의하지 않습니다. (Multi-Threaded Message Consumption with the Apache Kafka Consumer)
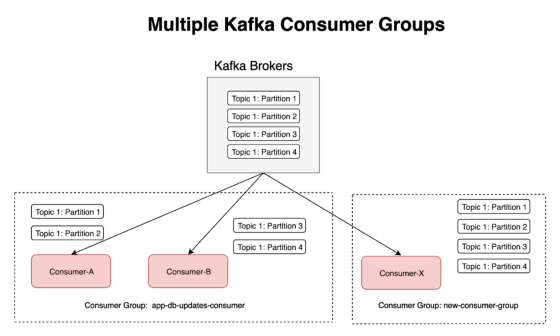
위 그림에서는 동일한 Topic / Partition 을 2 개의 Consumer A, B 가 나누어 읽는 것을 보여줍니다. 이는 Consumer Group 이 다르기 때문입니다.
- 하나의 서비스를 위해 Consumer A 가 Topic 1 내 Partition 1 번을 할당 받고 (consumer group = X)
- 또 다른 서비스를 위해 Consumer B 가 Topic 1 내 Partition 1 번을 다시 다른 용도로 할당 받을 수 있습니다 (consumer group Y)
- Consumer Group 별로 Partition 들의 Offset 이 관리됩니다
Consumer Group 내 Consumer 숫자가 추가되면 무슨 일이 발생할까요? 예를 들어
- Partition 10개의 Topic A 에 대해
- Consumer Group G1 에서 5개의 Consumer 를 이용해 Partition 10개를 할당 받아 처리하다가
- Consumer Group G1 에 5개의 새로운 Consumer 를 추가합니다 (e.g, 별도 프로세스 추가 등)
다음은 Confluent 문서 내 Kafka Consumer 에 대한 설명 중 일부입니다. 이 부분을 읽어보며 생각해 봅시다.
A consumer group is a set of consumers which cooperate to consume data from some topics. The partitions of all the topics are divided among the consumers in the group. As new group members arrive and old members leave, the partitions are re-assigned so that each member receives a proportional share of the partitions. This is known as rebalancing the group.
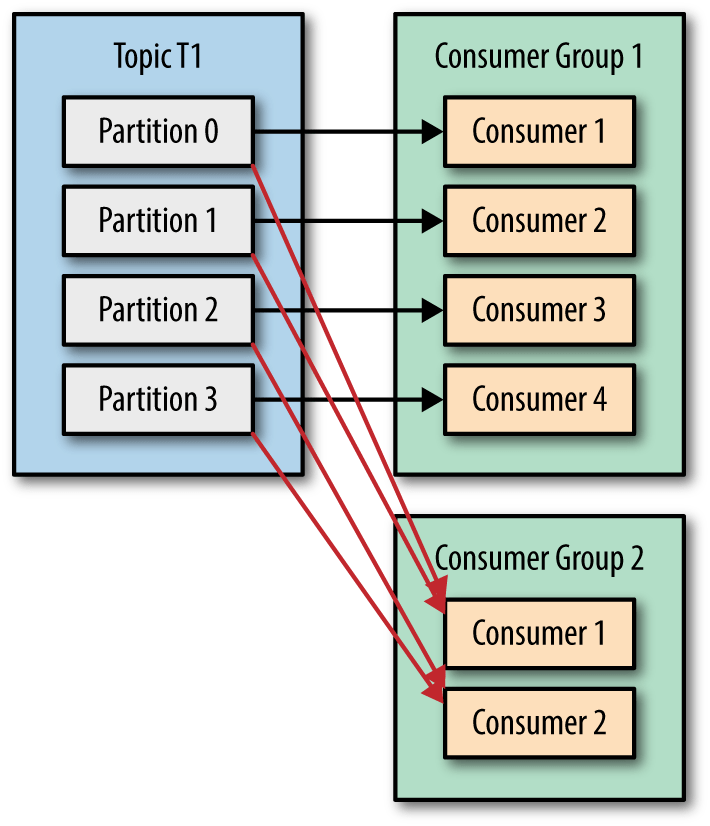
Kafka Overview

Topic 과 Producet, Consumer 관점에서 살펴보면
- 하나의 Kafka Topic 기준으로 여러 Producer 가 나누어 메세지를 보낼 수 있습니다.
- 하나의 Kafka Topic 을 기준으로 한 Consumer Group 내 여러 Consumer 가 메세지를 읽어 처리할 수 있습니다.
- 하나의 Kafka Topic 을 기준으로 두개 이상의 Consumer Group 이 동일한 메세지를 읽어 처리할 수 있습니다.
- 위 그림에는 나와있지 않으나, 필요하다면 Consumer Group 내에서 두개 이상의 Topic 을 읽어 처리할 수 있습니다.
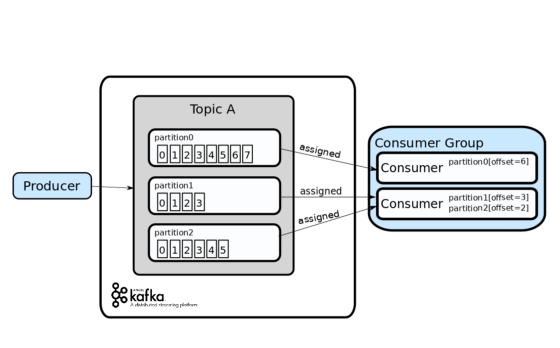
한 Topic 내에서 Partition 숫자는 병렬성을 조절하는 역할을 합니다.
- Topic 내 Partition 숫자를 높이면 데이터가 여러 Broker 에 분산될 수 있습니다.
- 그리고 나누어진 Partition 을 여러 Producer / Consumer 에서 메세지를 보내고, 읽어 처리할 수 있습니다.
- 위 그림에서는 3개의 Partition 이 2개의 Consumer 에 할당되는 것을 볼 수 있습니다.
Partition 별로 하나의 Consumer Group 내 Consumer 를 최대 한개까지 할당 할 수 있습니다. 그림으로 보면 아래와 같습니다.
- Partition 숫자보다 Consumer 가 적을 경우, Partition 들을 나누어 Consumer 가 가져갑니다
- Partition 숫자보다 Consumer 가 많을 경우, 일부 Consumer 는 Partition 을 할당 받지 못합니다.
참고로, Spark 경우에는 Consumer 를 자체적으로 관리해 Partition 보다 많은 수의 Processing Thread 를 확보할 수 있습니다.
- 예를 들어 Kafka Topic Partition 은 32개지만 Spark 의 Partition 은 64 개로 처리할 수 있습니다.
- 즉, Kafka Topic Partition 1개의 메세지를 2개의 Spark Partition 에서 나누어 처리합니다.
- 다만 이 경우 부분 실패시 Message Offset 관리가 복잡해지는 등의 문제가 발생할 수 있어 일반적으로는 1-1 (minPartitions 를 세팅하지 않음) 로 사용하는 편이 낫습니다.
- Spark Streaming 프레임워크는 Partition Offset 을 자체적으로 관리하고 (Checkpoint) Kafka Consumer 를 캐싱하는 등 별도의 로직이 존재합니다. 이 부분은 추후 Practical Spark – Streaming 에서 에서 다루겠습니다.
아래는 Spark Structured Streaming 의 Kafka 설정중 minPartitions 옵션에 대한 내용입니다.
Desired minimum number of partitions to read from Kafka. By default, Spark has a 1-1 mapping of topicPartitions to Spark partitions consuming from Kafka. If you set this option to a value greater than your topicPartitions, Spark will divvy up large Kafka partitions to smaller pieces. Please note that this configuration is like a
hint: the number of Spark tasks will be approximatelyminPartitions. It can be less or more depending on rounding errors or Kafka partitions that didn’t receive any new data.
아래 그림들은 Partition 과 Consumer 숫자에 따른 파티션 할당을 보여줍니다.
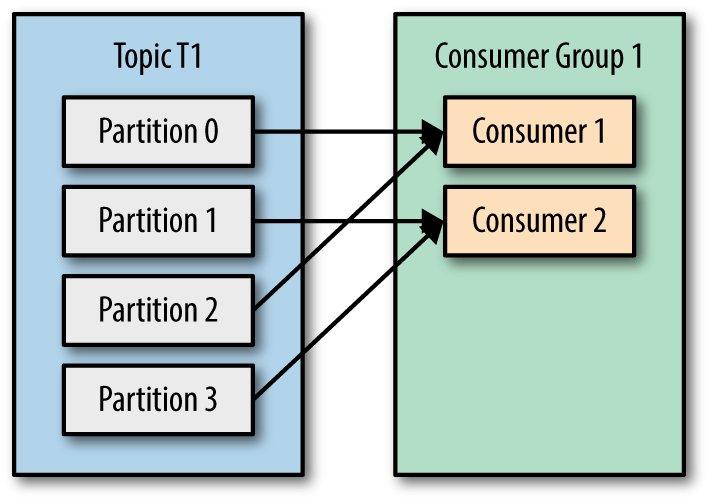
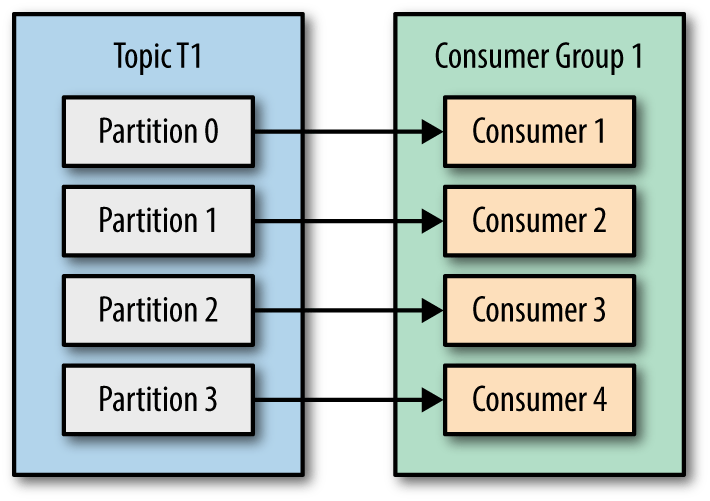
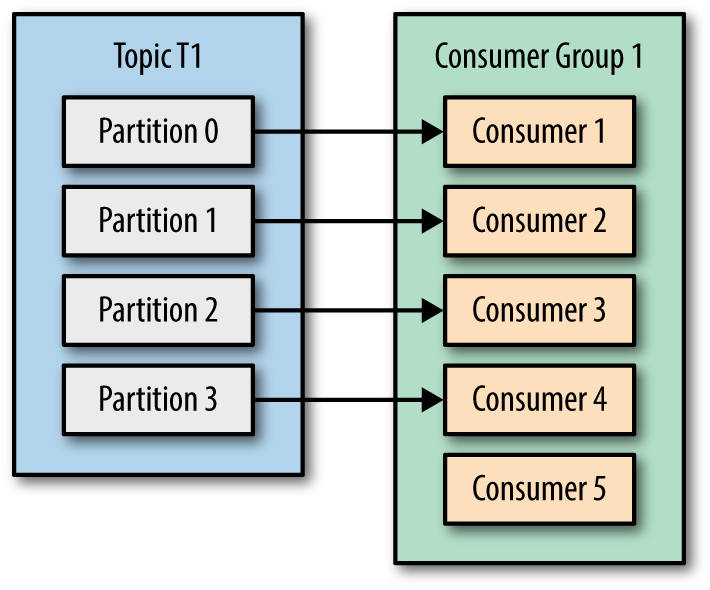
Consumer 와 Partition 숫자에 대해 논의해 봅시다.
- 1.Consumer 숫자보다 Partition 숫자가 많으면 어떤 일이 발생할까요?
- 2.Partition 숫자보다 Consumer 숫자가 많으면 어떤 일이 발생할까요?
또한 Consumer 를 Process / Thread 관점에서도 생각해 봅시다.
- JVM 언어 기준으로 1 Consumer = 1 Thread 로 이해해도 괜찮다는 이야기를 위에서 언급 했습니다. (1 Read Consumer Thread / N Processing Thread 전략 제외)
- 그렇다면 Partition = 12 인 Topic 을 기준으로 인프라 리소스 할당 및 운영 관점에서 어떤 차이가 있을까요?
- 1 개의 JVM Appliaction Process 내에서 12개의 Consumer Thread 를 실행하는 것
- 4 개의 JVM Application Process 내에서 각 3개의 Consumer Thread 를 실행하는 것
Practice
실습 과제입니다.
Practical Data Pipeline – Github 레포지토리 내 docker-compose 설정을 바탕으로 Kafka 를 띄워봅시다. 아래의 컴포넌트들이 실행되어야 하고, http://localhost:8080 에서 Kafka UI 를 확인할 수 있어야 합니다.
- Kafka Broker
- Zookeeper
- Schema Registry
- Kafka UI
Practical Spark 클래스에서는 Spark 를 이용해 Kafka 를 사용하게 됩니다. 그런데 Spark Executor 는 JVM Process 입니다. Kafka Consumer 와는 어떤 관계가 있을까요? 다음 문서를 통해 살펴봅시다.
- (Spark Streaming, DStream) https://spark.apache.org/docs/3.2.0/streaming-kafka-0-10-integration.html#consumerstrategies
- (Spark Structured Streaming) https://jaceklaskowski.gitbooks.io/spark-structured-streaming/content/spark-sql-streaming-kafka-data-source.htm
Summary
아래의 단어들은 이번 시간에 다룬 내용들입니다. 한 번씩 복기해보며 어떤 개념인지 스스로에게 설명해 봅시다. 기억이 나지 않을 경우 인터넷을 찾아봐도 좋습니다.
- Broker
- Topic
- Partition
- Offset
- Consumer
- Producer
- Consumer Group
