P2P 시스템의 기술들은 cloud computing 의 많은 분야에서 활용됩니다. 뒤에서 배울 Chord P2P hashing 같은 경우는 Cassandra, Voldmort 등의 key-value store 에서 쓰이고 있습니다.
Napster
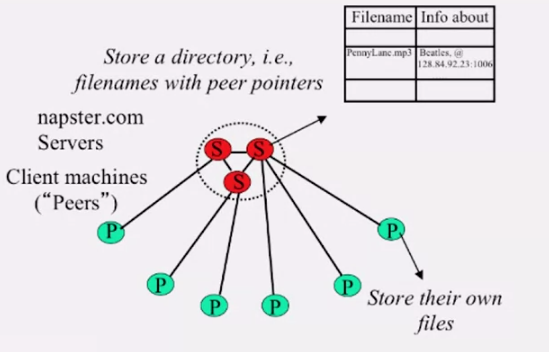
최초에 peer 는 서버에게 메세지를 보내 P2P 시스템에 가입했다는 사실을 알립니다.
Napster 에서는 중앙에 서버를 두어, 파일이 저장된 peer 를 기록합니다. 각 peer 는 파일이 어디있는지 검색하기 위해 중앙 서버에 질의해야 합니다. 그림에서 볼 수 있듯이, 각 파일은 서버가 아니라 클라이언트 에 저장되어 있습니다. 파일이 어느 클라이언트(peer) 에 저장되어있는지 알게되면, ping 을 날려 살아있는지 확인 후 파일을 다운 받습니다.
Napster 의 문제점은
- 중앙 서버로의 요청이 너무나 많습니다.
- 서버가 다운되면, 시스템이 멈춥니다.
Gnutella
Gnutella 는 Napster 시스템에서 서버를 제거했습니다. 각 클라이언트 (peer) 는 파일이 어디 저장되어있는지 파악하기 위해 서로 통신하지요. 이처럼 클라이언트가 서버처럼 행동하기때문에 servent 라 부르기도 합니다.
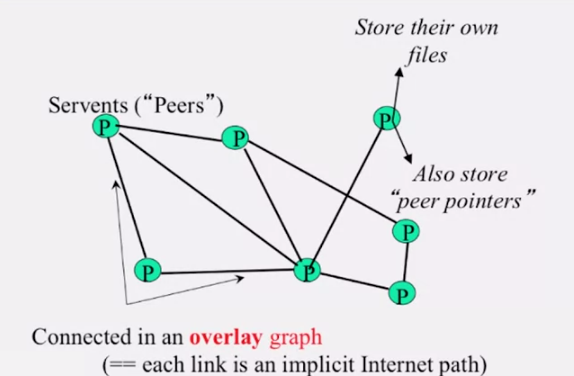
위 슬라이드에서 알 수 있듯이, 각 피어는 근처에 있는 피어로의 링크를 가지고 있습니다. 이 링크는 overlay graph 라 부르기도 합니다.
gnutella 에서 피어간 통신에 사용되는 주요 메세지 타입은
- Query: search
- QueryHit: reponse to query
- Ping: to probe network for other peers
- Pong: reply to ping, contains address of another peer
- Push: used to initiate file transfer
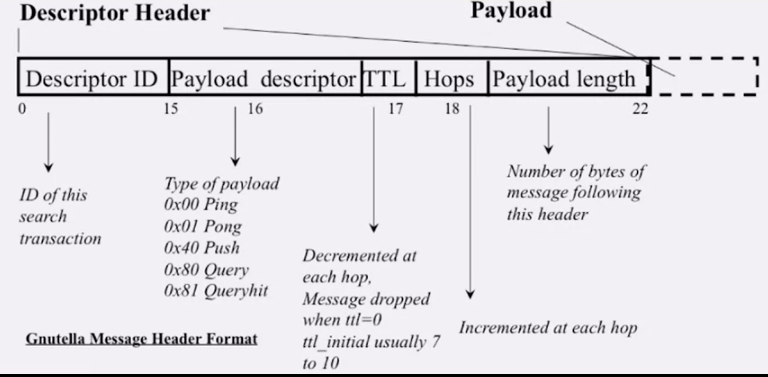
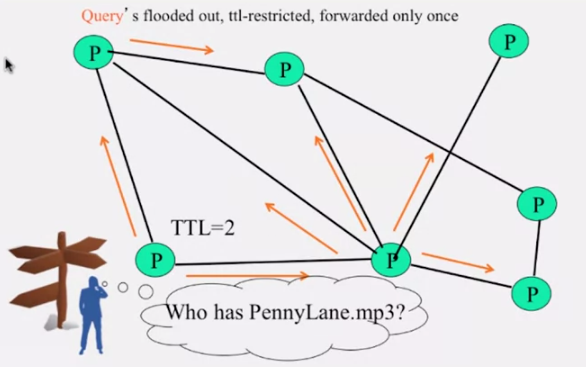
위 그림에서 TTL = 2 이기 때문에 query 메세지는 2-hop 까지만 전파됩니다. 그리고 gnutella 에서는 각 피어가 최근에 퍼트린 query 메세지 리스트를 유지하고 있기 때문에 같은 메세지를 다시 전파하지 않습니다.

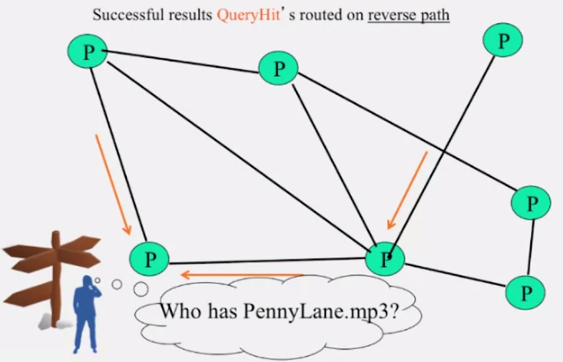
피어가 보낸 query 에 대해 해당하는 파일을 가지고 있다는 응답은 query hit 메세지를 통해 전달됩니다.
gnutella 에서는 과도한 트래픽을 방지하기 위해 다음의 방법을 사용합니다.
- to avoid duplicate transmissions, each peer maintains a list of recently received messages
- query forwarded to all neighbors except peer from which received
- each query (identified by
DescriptorID) forwarded only once - QueryHit routed back only to peer from which Query received with same
DescriptorID - for flooded messages, duplicates with same
DescriptorIDand Payload descriptor are dropped - QueryHit with
DescriptorIDfor which Query not seen is dropped

QueryHit 메세지를 requestor 가 받으면 최적의 responder 를 고르고, HTTP 를 이용해서 몇번의 통신을 한 뒤 파일을 전송받습니다. 여기서 gnutella 가 HTTP 를 이용하는 이유는, HTTP 가 standard, well-debugged, widely used 이기 때문입니다.
그런데 만약, responder 가 방화벽(firewall) 뒤에 있으면 어떻게 될까요? 일반적으로 방화벽은 incomming message 를 필터링 합니다. gnutella 는 이럴 경우 대비해 push 를 만들어 놓았습니다.
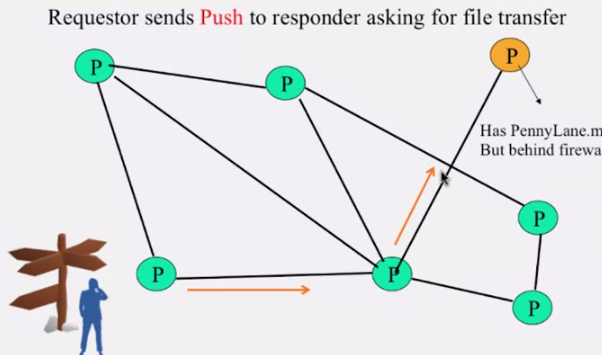
query hit 메세지를 받은 후에 requestor 가 보내는 HTTP 메세지에 responder 가 응답하지 않으면 overlay link (이미 연결되어있는) 을 통해서 push 메세지를 requestor 가 보냅니다. responder 는 방화벽 뒤에 있어도, overlay link 를 통해 받은 push 메세지를 확인하고 파일 전송을 시작합니다.
만약 requestor 가 방화벽 뒤에 있다면, gnutella 프로토콜로는 파일을 전송 받을 수 없습니다.
gnutella 에서 생기는 문제점은
- ping/pong constituted 50% traffic: use multiplex, cache and reduce freq of ping/pong
- modem-conncted hosts do not have enough bandwidth for passing gnutella traffic: use a central server to act as proxy for such peers. or use FastTrack System
- large number of free loaders
- flooding causes excessive traffic: use Structured P2P system e.g Chord System
FastTrac
FastTrac 은 Kazza, KazzaLite, Grokster 라는 기술을 기반으로 한 Napster Gnutella 의 하이브리드입니다.
healthier participants 를 이용하겠다는 기본적인 아이디어로부터 출발했습니다. gnutella 와 비슷하지만 노드중 일부가 supernode 가 되어, 특별한 역할을 수행합니다.
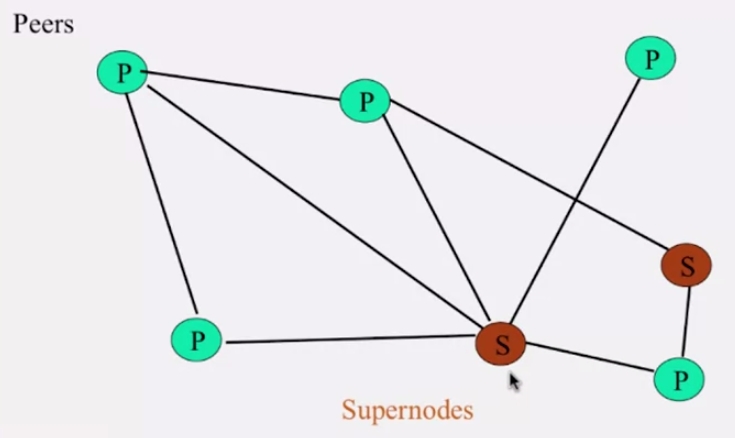
- *supernode*는 Napster server 와 비슷하게 근처에 있는 노드의
리스트를 저장합니다 - supernode 의 멤버십은 시간이 지나면서 변합니다
- 어떤 노드도 supernode 가 될 수 있습니다. 그러기 위해서는 reputation 을 얻어야 합니다
- 각 노드는 데이터를 탐색하기 위해 supernode 에 질의합니다
이 reputation system 은 Kazaalite 처럼 upload 한 파일의 양으로 결정할 수도 있고, 경제학적인 원리를 적용한 방법도 있습니다
BitTorrent
이전에 언급했듯이 다운만 받는 peer 도 존재할 수 있습니다. BitTorrent 는 업로드 하는 peer 에게 보상을 해 주어, peer 들의 업로드를 더 이끌어 낼 수 있습니다.
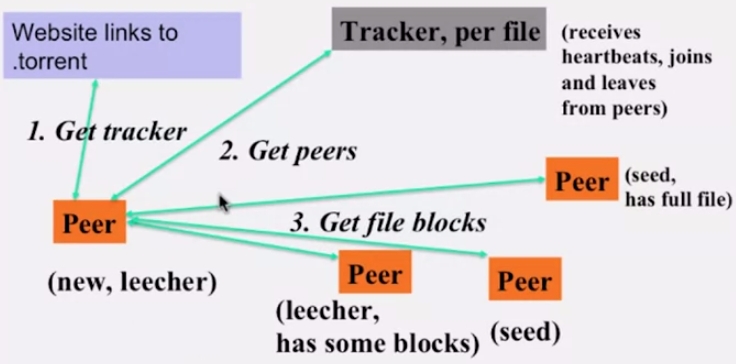
BitTorrent 네트워크 구성은 위 슬라이드와 같습니다.
- Tracker: 파일당 하나씩 존재하며 heartbeat 를 받아 peer 의 join, leave 를 관리합니다.
- Seed: 전체 파일을 가지고 있는 peer
- Leecher: 파일의 일부분을 가지고 있는 peer
BitTorrent 에서는 블럭단위로 파일을 전송하는데, 이 때 사용하는 몇 가지 규칙이 있습니다.
- Local Rarest First: 파일을 다운받을때, 귀한 블럭부터 먼저 받습니다
- Tit for tat: 업로드 하는 만큼, 다운로드 bandwidth 를 할당받습니다. 다시 말해서 업로드를 많이해야 빠르게 받을 수 있습니다
- Choking: 동시에 업로드하는 neighbor 수를 제한해서 bandwidth 가 너무 많이 사용되지 않도록 합니다. best neighbor 를 선택하여 unchoked set 을 유지하고, 주기적으로 이 집합을 재평가합니다. 이외의 다른 peer 는 choked set 입니다.
optimistic unchoke 기법은 주기적으로 랜덤한 neighbor 를 unchoke 해서, unchoked set 을 fresh 하게 유지합니다. 여기서 random choice choking 을 쓰는 이유는
- To avoid the sysem from getting stuck where only a few peers receive service
DHT
지금까지 본 Napster, Gnutella, FastTrac 은 일종의 DHT, Distribute Hash Table 입니다.
DHT 에서의 performance concerns 는
- load balancing
- fault-tolerance
- efficiency of lookup and inserts
- locality
우리가 배울 Chord 는 이런 구조가 적용된 structured peer to peer system 입니다.
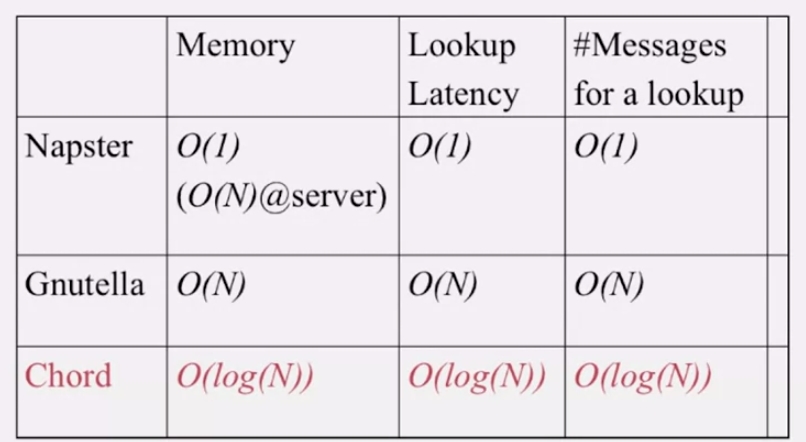
Napster 는 peer 의 경우 파일을 저장하지 않기 때문에 메모리가 많이 들지 않지만, server 에서 많은 메모리를 요구합니다. 서버로 질의가 가기때문에 lookup latency 나 lookup 을 위한 메세지 수 자체는 많지 않지만, 서버의 부하가 상당히 심할 수 있습니다.
반면 Gnutella 에서는 서버가 없습니다. 그렇기 때문에 피어는 파일이 저장되어있는 주변 피어의 목록을 가지고 있어야 하는데, N 만큼의 이웃이 주변에 있을 수 있습니다. 따라서 한 피어에서 필요한 메모리 양은 O(N) 입니다.
그리고 네트워크가 직선으로 구성되어 있다고 할때, lookup latency 는 O(N) (N-1) 이고 룩업을 위한 메세지 수도 O(N) (2(N-1)) 입니다.
반면 Chord 는 모두 O(log N) 입니다. 이론적으로 constant 는 아니지만, real world 에서는 상당히 낮은 수가 될 수 있습니다.
Chord
Chord 는 Berkeley 와 MIT 에서 개발된 P2P 프로토콜입니다.latency 와 message cost of routing (lookups/inserts) 를 줄이기 위해 지능적으로 neighbor 를 선택하고 Consistent Hashing 기법을 사용합니다.
Consistent Hasing 값은 peer 에 부여되는 주소값으로
- IP 와 Port로 SHA1 로 해싱해서 160 비트 스트링을 만들고
m비트로 절단해서 사용합니다- peer 의 ID 라 불리기도 하는데, 이 값은 당연히 최대
2^m - 1입니다 - 해싱값이므로 unique 하진 않지만 충돌이 일어날 확률은 굉장히 적습니다
- 그리고 이 값이
2^m개의 점이 되어 하나의 원을 구성합니다
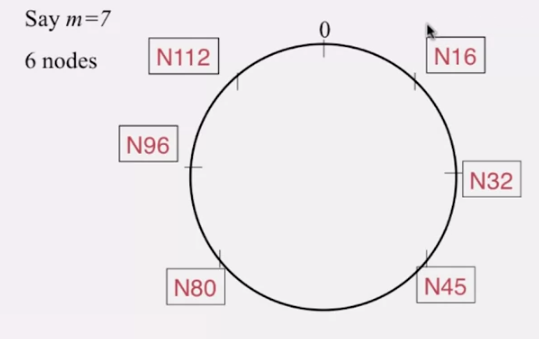
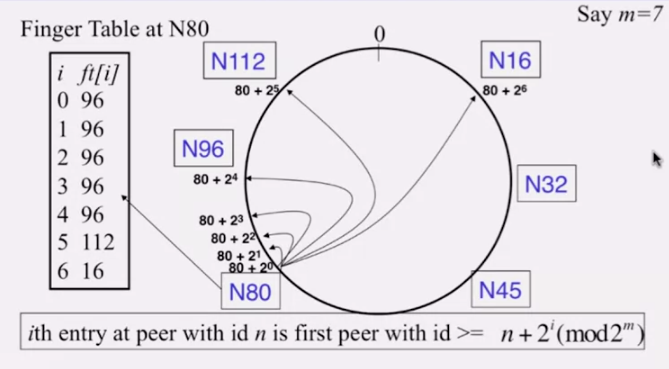
각 노드는 (반) 시계방향으로의 successor 를 가지고 있고, 다른 노드를 가리키기 위한 finger table 을 가지고 있습니다.

파일도 마찬가지로 SHA-1 으로 해싱해서, 160 비트로 짜른 뒤 mod 2^m 연산해서, 같은 값이거나 그보다 큰 값을 가지는 peer 에 저장합니다.
만약 균일하게 해싱된다면 K 개의 키, N 개의 피어에서 파일은 각 피어당 K/N 개씩 저장되므로 피어당 걸리는 부하는 O(K/N) 입니다.
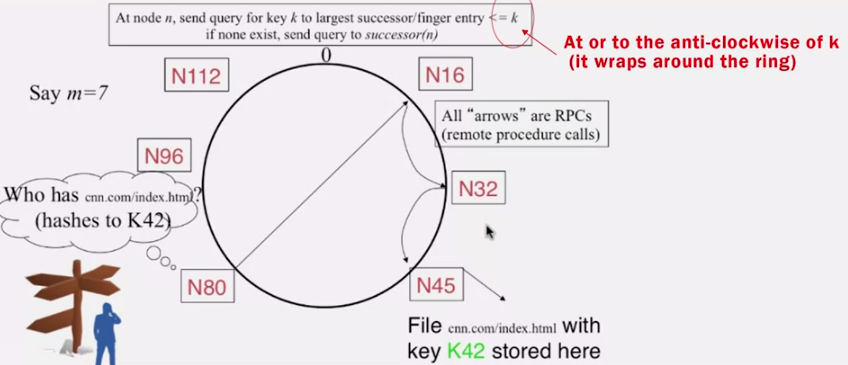
위 그림에서 N80 피어가 K42 파일을 찾을때,
- finger table 에
42가 없으므로 최대한 먼N16에 질의하고, N16은N32와N80밖에 모르므로N32를 거쳐N45로 질의합니다.

chrod search 는 O(log N) 의 시간이 듭니다. 증명에 대한 intuition 은 쉽습니다.
만약 현재 Here 에서 Key 를 모른다고 합시다. 그러면 그 거리의 1/2 만큼은 점프를 해야합니다. 그것보다 더 적게 점프하면 거리를 d 라 합시다. finger table entry 값은 2배씩 증가하기 때문에, 2d 만큼 점프할 수 있는 엔트리가 있어야 하고, 그럼 애초부터 2d 만큼 점프했어야 했기 때문에 모순입니다.
log(N) 만큼의 점프 뒤에는 key 까지의 거리는 아무리 멀어봐야 2^m / N 입니다. 균일하게 분포되는 해싱을 쓴다 가정하면, 이 사이에는 적은 수의 노드만 있습니다. 따라서 O(logN) 만큼만 더 점프한다면 높은 확률로 key 를 찾을 수 있습니다. O(logN) + O(logN) = O(logN) 이므로, search 는 O(logN) 입니다.
insertion 도 searching 과 마찬가지로 O(logN) 입니다. 그러나 이 성능은 finger table 과 successor 가 잘못되지 않았을 경우에만 참입니다.
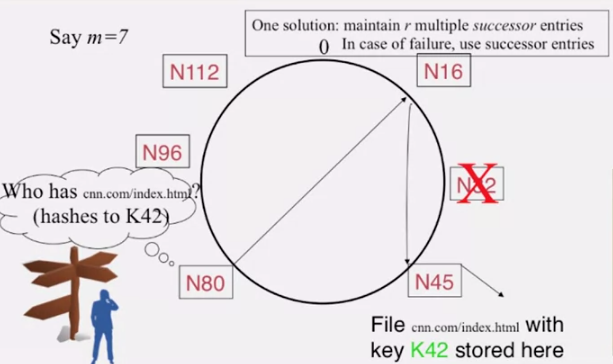
chrod 는 successor 한개만 가질땐 failure 에 취약하기 때문에, 위 그림처럼 다수개의 successor 를 가질 수 있습니다. 이 경우 성능은 어떻게될까요?

2log(N) 개의 successor 를 유지할 경우를 한번 생각해 봅시다. 50% 씩 failure 가 발생하면
- 하나의 노드에서 유지하는 successor 중, 적어도 하나의 successor 가 살아있을 확률은
- 위 확률은 모든 살아있는 노드(
50%) 에서 참일때, 다시 말해서 모든 노드에서 적어도 하나의 successor 가 존재할 확률은N이 매우 클때
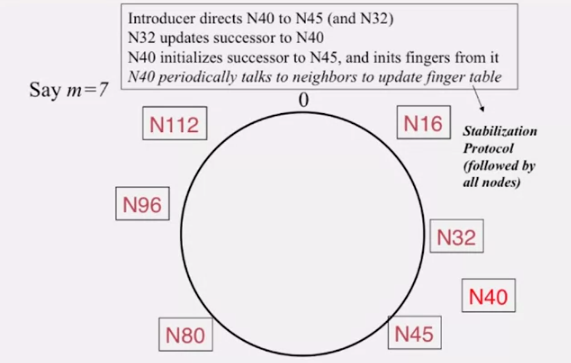
- a new peer affects
O(logN)other finger entires in the system, on average - number of messages per peer join
O(logN * logN)

join, leave, failure 등 churn 이 자주 일어나므로 loop 가 있는지 없는지 검사하기 위해 주기적으로 stabilization protocol 를 사용합니다.
Pastry


Pastry 는 chord 처럼 node 에 id 를 부여합니다. routing table 은 prefix matching 에 기반하기 때문에 log(N) 의 성능을 보여줍니다. 그리고 짧은 prefix 일 수록 가까이에 있을 확률이 높습니다.
Kelips
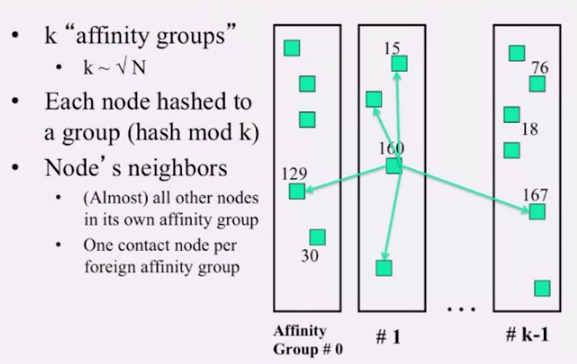
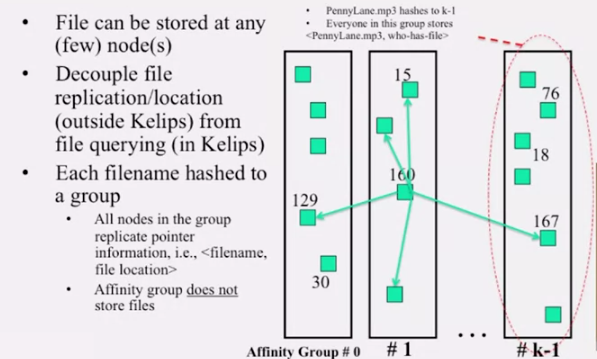
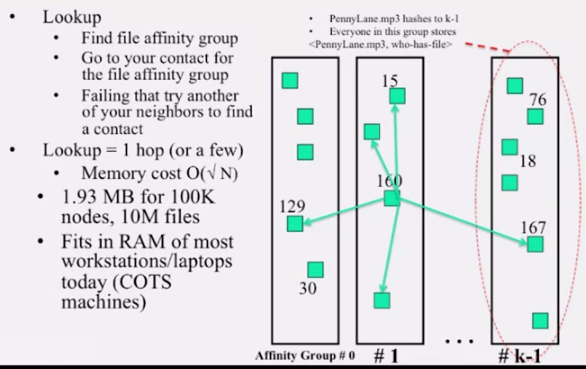
Kelips 는 1-hop lookup 을 보여줍니다. 이럴 수 있는 이유는 위 그림에서 보듯이 affinity group 이란걸 사용하기 때문입니다. 루트 N 에 가까운 숫자 k 를 정하고, 이 수로 mod 연산을 해, 그룹을 만듭니다. 각각의 그룹은 내에 있는 모든 노드는 서로 어떤 파일을 저장하는지 알고 있습니다. 그리고 각 노드는 다른 그룹으로의 링크를 하나씩 가지고 있습니다. 따라서 어딜가든 거의 1번 혹은 2번 내에 lookup 이 가능합니다.
chord 에 비해 메모리를 더 잡아먹긴 합니다. O(logN) 보단 많은 양이지만, 그렇게 많지도 않습니다. 메모리가 귀하다면 chord 나 pastry 를, 그렇지 않고 lookup 속도가 중요하다면 kelips 를 사용하면 됩니다.
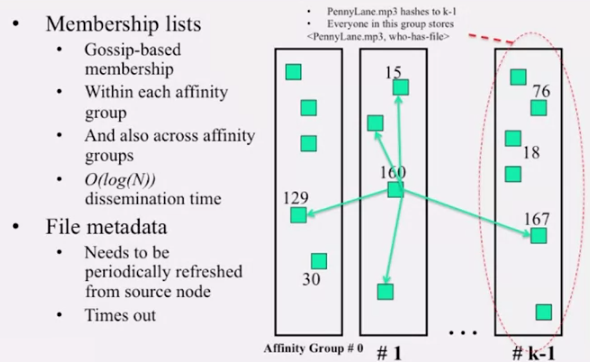
membership 은 gossip-based 프로토콜로 관리할 수 있습니다.
Refs
(1) Title Image
(2) Cloud Computing Concept 1 by Indranil Gupta, Coursera
