edx 의 FP101.x (Introduction to Functional Programming) 수업 중 3 번째 챕터입니다.
하스켈에서 repetition (반복) 은 recursion 을 통해 표현됩니다. 간단한 재귀부터 시작해서 mutual recursion 까지 알아보고, Higher order function (특히 fold) 에 대해 배운 뒤 적용을 위해 church numerals 를 구현해보고, 마지막으로 간단한 문자열 전송기를 모델링 해 보겠습니다.
Tail call?
recursion 을 주로 사용한다면 stack 이 많이 쌓일 수 있습니다. 이런 문제를 해결해 주는 것이 tail call elimination 입니다.
간단한 재귀 함수를 만들어서 스택이 어떻게 변하나 한번 보죠.
factorial 0 = 1
factorial n = n * factorial(n - 1)
이 때 factorial 3 을 평가한다면
factorial 3
3 * factorial 2
3 * (2 * factorial 1)
3 * (2 * (1 * factorial 0))
3 * (2 * (1 * 1))
3 * (2 * 1)
3 * 2
6
이렇게 각 단계가 확장되면서 n 이 매우 클 경우 마지막 단계에서 연산의 길이가 엄청나게 길어집니다. 함수 한번 호출당 스택이 하나씩 생긴다고 보면 어마어마한 스택이 생기는 것이죠.
다행히도 하스켈은 tail recursion optimization (꼬리 재귀 최적화) 를 가지고 있습니다. 꼬리 재귀에 대한 이야기는 나중에 더 이야기 하도록 하지요.
Recursion on Lists
리스트는 같은 타입을 여러개 저장할 수 있기 때문에 recursion 을 사용하기 적합하죠.
리스트 내의 모든 원소의 곱을 구하는 product 함수를 만들어 볼까요? 하스켈에 원래 있지만, 재미삼아 만들어 봅시다. 이름은 충돌이 안나게 productC 라 부릅시다.
productC :: [Int] -> Int
productC [] = 1
productC (n : ns) = n * productC ns
length 와 reverse 도 만들어 봅시다.
lengthC :: [a] -> Int
lengthC [] = 0
lengthC (x : xs) = 1 + length xs
reverseC :: [a] -> [a]
reverseC [] = []
reverseC (x : xs) = reverse(xs) ++ [x]
조금 더 복잡한 zip, drop 함수나 ++ 연산자도 어렵지 않습니다.
zipC :: [a] -> [b] -> [(a, b)]
zipC [] _ = []
zipC _ [] = []
zipC (x:xs) (y:ys) = (x, y) : zip xs ys
dropC :: Int -> [a] -> [a]
dropC 0 xs = xs
dropC _ [] = []
dropC n (x:xs) = drop (n-1) xs
(++) :: [a] -> [a] -> [a]
[] ++ ys = ys
(x:xs) ++ ys = x : (xs ++ ys)
Quick sort
퀵소트 알고리즘은 간단합니다. 매 함수 호출에서, pivot 이라 불리는 리스트 내 원소를 고른 후 pivot 좌측에는 그 보다 작은 수를, 우측에는 pivot 보다 큰 수를 배치합니다. 그리고 pivot 을 제외한 좌측 과 우측에 대해 재귀 호출을 하지요.

(https://sadakurapati.wordpress.com)
지난 강의에서 배운 list comprehension 을 이용하면 매우 간단하게 quick sort 를 만들 수 있습니다.
qsort :: [Int] -> [Int]
qsort [] = []
qsort (x:xs) = qsort smaller ++ [x] ++ qsort larger
where
smaller = [a | a <- xs, a <= x]
larger = [b | b <- xs, b > x]
위 코드에서는 매 재귀마다 인자로 받는 리스트의 첫번째 원소 x 를 pivot 으로 사용했습니다.

Recursion
위의 예에서 보았듯이 자기 자신을 호출하는 함수 패턴을 recursion (재귀) 라 부릅니다. 언제 유용할까요? 재귀를 이용하면 induction (귀납법) 을 이용해 함수의 성질을 증명할 수 있습니다. 제대로 동작하는지, 의도 했던대로 동작하는지 등을요.
Properties of functions defined using recursion can be proved using the simple but powerful mathematical technique of induction
Mutial recursion
mutual recursion 은 서로 다른 두개의 함수가 상호간 재귀를 이용해 정의되는 방식입니다.
odd 와 even 함수를 mutual recursion 을 이용해 정의할 수 있습니다. 일반적으로는 효율성을 위해 2로 나눈 나머지를 이용해 정의하지만, 양수에 대해서는 아래와 같이 mutual recursion 으로 만들 수 있죠.
even :: Int -> Bool
even 0 = True
even n = oddC (n-1)
odd :: Int -> Bool
odd 0 = False
odd n = evenC (n-1)
비슷하게 리스트에서 짝수번째, 혹은 홀수번째 원소들만 돌려주는 evens 와 odds 함수도 mutual recursion 을 이용해 정의할 수 있습니다. evens 는 0번째 부터 돌려줍니다. odds 는 턴을 넘기는데 쓰고 실제 작업은 evens 에서 한다고 생각하면 금방 이해할 수 있습니다.
evens :: [a] -> [a]
evens [] = []
evens (x:xs) = x : odds xs
odds :: [a] -> [a]
odds [] = []
odds (_:xs) = evens xs
Advice on recursion
재귀는 자전거 타기와 비슷합니다. 처음엔 불가능해 보이는데 한번 시도해보면 정말 쉽게 탈 수 있죠. 여기 재귀를 만드는데 도움이 될만한 5가지 스텝이 있습니다. init 함수를 예로 들어 설명하겠습니다.
(1) define the type
init :: [a] -> [a]
(2) enumerate the cases
init (x:xs) =
(3) define the simple case
init (x:xs) | null xs = []
| otherwise =
(4) define the other cases
init (x:xs) | null xs = []
| otherwise = x : init xs
(5) generalise and simplify
init :: [a] -> [a]
init [_] = []
init (x:xs) = x : init xs
Examples
예제 몇 가지를 좀 더 살펴봅시다. 먼저 곱셈 연산입니다.
(*) :: Int -> Int -> Int
m * 0 = 0
m * n = m + (m * (n - 1))
정렬된 리스트에 원소를 삽입하는 insert 함수입니다. 바로 다음에 만들 isort (insertion sort) 를 구현한 함수에서 사용합니다.
insert :: Ord a => a -> [a] -> [a]
insert x [] = [x]
insert x (y:ys) | x <= y = x : y : ys
| otherwise = y : insert x ys
isort :: Ord a => [a] -> [a]
isort [] = []
isort (x:xs) = insert x (isort xs)
이번엔 merge sort 입니다.
merge :: Ord a => [a] -> [a] -> [a]
merge [] ys = ys
merge xs [] = xs
merge (x:xs) (y:ys) =
if x <= y then x : merge xs (y: ys) else y : merge (x:xs) ys
halve :: [a] -> ([a], [a])
halve xs = splitAt (length xs `div` 2) xs
msort :: Ord a => [a] -> [a]
msort [] = []
msort [x] = [x]
msort xs = merge (msort ys) (msort zs)
where (ys, zs) = halve xs
Higher-order function
higher-order function 은 함수를 인자로 받아 다시 함수를 돌려주는 함수를 말합니다. 응?
A function is called higher-order if it takes a function as an argument or returns a function as a result
twice :: (a -> a) -> a -> a
twice f x = f (f x)
twice 는 인자 x 에 f 를 두번 적용한 뒤 값을 돌려줍니다. 더 정확히는 curried function 이므로 twice f 는 앞으로 뭘 인자로 받을지 모르지만 f 를 두번 적용하는 함수를 돌려줍니다.
이런 higher-order function (고차함수) 가 언제 유용할까요?
- Common programming idioms can be encoded as functions within the language itself.
- Domain specific languages can be defined as collections of higher-order functions.
- Algebraic properties of higher-order functions can be used to reason about programs.
map
먼저 map 함수를 살펴봅시다.
map :: (a -> b) -> [a] -> [b]
map (+1) [1, 3, 5, 7]
-- [2, 4, 6, 8]
이 map 함수는 우리가 이전에 배웠던 list comprehension 으로 똑같이 작성할 수 있습니다.
map f xs = [f x | x <- xs]
아니면 recursive function 으로 작성할 수도 있습니다.
map f [] = []
map f (x:xs) = f x : map f xs
filter
filter 도 고차함수입니다. filter 는 predicate 즉, (a -> Bool) 을 받아 True 인 원소만 모아 돌려줍니다.
filter :: (a -> Bool) -> [a] -> [a]
filter even [1..10]
-- [2, 4, 6, 8, 10]
filter 도 마찬가지로 list comprehension 과 recursive function 두 가지 버전으로 작성될 수 있습니다.
filter p xs = [x | x <- xs, p x]
filter p [] = []
filter p (x:xs)
| p x = x : filter p xs
| otherwise = filter p xs
단순히 list comprehension 으로 작성하는 것 보다, recursive function 으로 작성하면 위에서 볼 수 있듯이 공통점을 파악할 수 있습니다. 그러면 한단계 더 추상화 할 수 있지요. filter 와 map 의 공통점이 보이시나요?
foldr
위의 두 가지 예에서 filter, map 모두 빈 리스트와 그렇지 않은 리스트를 구분했습니다. 그리고 각각의 원소에 대해서 연산을 수행했지요.
f [] = v
f (x:xs) = x pred f xs
빈 원소라면 특정 값 v 를 돌려주고 아니라면 원소 x 에 pred를 적용하고, 나머지 tail xs 에 f 를 적용합니다. 비슷한 예제를 살펴볼까요?
-- v = 0, pred = +
sum [] = 0
sum (x:xs) = x + sum xs
-- v = 1, pred = *
product [] = 1
product (x:xs) = x * product xs
-- v = True, pred = &&
and [] = True
and (x:xs) = x && and xs
따라서 다음과 같이 foldr (fold right) 을 이용해 정의할 수 있습니다.
sum = foldr (+) 0
product = foldr (*) 1
or = foldr (||) False
and = foldr (&&) True
위에서 대략적인 정의를 봤지만, 더 엄밀하게 foldr 은 이렇게 정의할 수 있습니다.
foldr :: (a -> b-> b) -> b -> [a] -> b
foldr f v [] = []
foldr f v (x:xs) = f x (foldr f v xs)
보면 알겠지만, 리스트의 the right-most (가장 우측) 부터 연산합니다. 그래서 fold right 라는 이름이 붙었지요. 그림으로 보자면
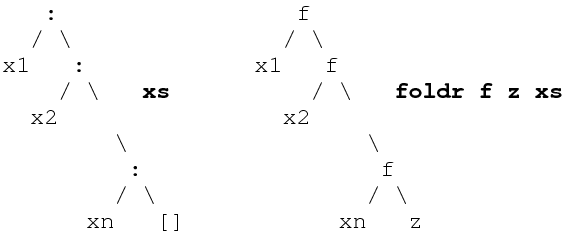
(http://www.pling.org.uk/cs/fun.html)
sum [1, 2, 3]
foldr (+) 0 [1, 2, 3]
foldr (+) 0 (1:(2:(3:[])))
1 + (2 + (3 + 0))
콘싱 : 하고 비슷합니다. 이 부분에 연산자를 집어넣고, [] 에 초기값 v 를 넣는다고 생각하면 이해하기 쉽습니다.
length 도 비슷한 패턴을 가지고 있기 때문에 foldr 로 바꿀 수 있습니다.
length :: [a] -> Int
length [] = 0
length (x:xs) = 1 + length xs
length = foldr (\_ n -> 1 + n) 0
이렇게 바꿀 수 있는 이유는
length [1, 2, 3]
length (1: (2: (3:[])))
1 + (1 + (1 + 0)))
여기서 각 : 을 \_ n -> 1 + n 으로 바꾸면 되기 때문입니다.
reverse [] = []
reverse (x:xs) reverse xs ++ [x]
이제 위 reverse 함수도 foldr 을 이용할 수 있습니다.
reverse = foldr (\x xs -> xs ++ [x]) []
처음의 filter, map 도 이렇게 정의할 수 있습니다.
foldr :: (a -> b -> b) -> b -> [a] -> b
foldr f v [] = v
foldr f v (x:xs) = f x (foldr f v xs)
filter :: (a -> Bool) -> [a] -> [a]
filter p xs = foldr (\x acc -> if p x then x : acc else acc) [] xs
map :: (a -> b) -> [a] -> [b]
map p xs = foldr (\x acc -> p x : acc) [] xs
foldr 을 이용하면 몇 가지 장점이 있습니다.
- Some recursive functions on lists, such as sum, are simpler to define using foldr.
- Properties of functions defined using foldr can ben proved using algebraic properties of foldr, such as fusion and the banana split rule.
- Advanced program optimizations can be simpler if foldr is used in place of explicit recursion.
여기서 fusion 은, 하나의 foldr 은 리스트를 순회하면서 새로운 리스트를 리턴하고, 다른 foldr 을 그 결과에 사용할 때 intermediate list 를 생성하는 것 없이 계산을 해 낸다는 뜻입니다.
In particular fusion means that I have two functions. One that uses
foldrto traverse one list and return another list. And if I do anotherfoldron the result of that I can fuse these two together, such that the intermediate list is never constructed. So program can be optimized.
다른 고차함수들을 좀 살펴봅시다.
composition
(.) 은 함수를 composition (합성) 해 줍니다.
(.) :: (b -> c) -> (a -> b) -> (a -> c)
f . g = \x -> f(g x)
예를 들어
odd :: Int -> Bool
odd = not . even
compoisition 을 사용할때는 괄호와 나머지 인자를 제거하여 함수의 정의를 간단히 할 수 있습니다.
twice f x = f (f x)
-- same as
twice f = f f
all, any
모든 원소에 대해 p 를 적용한 결과가 참인지를 돌려주는 all 은 다음처럼 정의할 수 있습니다.
all :: (a -> Bool) -> [a] -> Bool
all p xs = and [p x | x <- xs]
이번엔 list comprehension 을 사용했습니다. foldr 과의 차이는, foldr 은 모든 순회 가능한 데이터 타입에 적용 가능한 반면 list comprehension 은 리스트에만 사용할 수 있습니다. 위 예제를 foldr 로 바꾸면
all :: (a -> Bool) -> [a] -> Bool
all p xs = foldr (\x acc -> p x && acc) True xs
any 도 만들 수 있습니다.
import Data.Char
any :: (a -> Bool) -> [a] -> Bool
any p xs = or [p x | x <- xs]
-- same as
any p xs = or (map p xs)
takeWhile, dropWhile
takeWhile 은 predicate 가 참인 원소까지만 돌려줍니다. 예를 들어
takeWhile :: (a -> Bool) -> [a] -> [a]
takeWhile p [] = []
takeWhile p (x:xs) | p x = x : takeWhile p xs
| otherwise = []
takeWhile isAlpha "abc def"
-- "abc"
반면 dropWhile 은 predicate 를 적용한 결과가 참인 원소를 모두 버리고 나머지만 돌려줍니다. 예를 들어
dropWhile :: (a -> Bool) -> [a] -> [a]
dropWhile p [] = []
dropWhile p (x:xs) | p x = dropWhile p xs
| otherwise = x:xs
dropWhile isAlpha "fp 101"
-- " 101"
Church Numerals
Church Numerals give us a way to abstract over the concrete representation of a number by means of functions and unction application.
숫자 n 은 zero 에 n 번의 s function application 을 통해 정의합니다.
zero = \s z -> z
one = \s z -> s z
two = \s z -> s (s z)
-- same as
two = \s z -> (s . s) z
-- we can remove z
two = \s -> s . s
여기서 데이터 z 자체는 아무것도 정해진 것이 없습니다. 다시 말해 어떤 타입이든 가져다 쓸 수 있다는 뜻이지요.
우리가 숫자 3을 표현하기 위해 1을 세번 더해 3 을 표시하든, 아니면 * 를 세번 컨싱하든 상관 없다는 뜻 입니다.
zero = \s z -> z
one = \s z -> s z
two = \s -> s . s
-- church to int
c2i x = x (+1) 0
c2i zero
-- 0
c2i one
-- 1
c2i two
-- 2
* (에스터리스크) 의 개수로 숫자를 정의해 봅시다.
-- church to int
c2s x = x ('*' :) ""
c2s zero
-- ""
c2s one
-- "*"
c2s two
-- "**"
이제 연산자를 만들어 봅시다. 덧셈부터 시작해 보죠! c2i 에 x 를 넣어 만들어낸 수 (Number) 를 x' 라 하고 y 를 넣어 만든 수를 y' 라 합시다.
x' = c2i x
y' = c2i y
그러면 덧셈은 이렇게 정의할 수 있습니다.
x' + y' = c2i (add x y)
증명해 봅시다.
x' + y'
= c2i x + c2i y
= x (+1) 0 + c2i y -- 0 is substituted
= x (+1) (c2i y)
= x (+1) (y (+1) 0)
= (\s z -> x s (y s z)) (+1) 0 -- by beta expension
보면 알겠지만 c2i y 나 0 + c2i y 나 같습니다. 따라서 0을 지우고 x c2i 의 베이스 값으로 (c2i y) 를 사용할 수 있죠.
그리고 마지막 치환은 s 와 z 를 (+1) 과 0 으로 취하는 lambda 를 구할 수 있습니다. \s z -> x s (y s z) 를 add 라 부르면
x' + y' = (add x y) (+1) 0
= c2i (add x y)
결국 addtion 은
add x y = \s z -> x s (y s z)
c2i (add one two)
-- 3
multiplication (곱셈)은 어떻게 만들까요? 간단한 예제부터 시작해 intuition 을 얻어보도록 합시다.
two = \s -> s . s
three = \s -> s . s . s
결국 n 번째 수란건 s successor function 을 n 번 만큼 수행한거지요. 그럼 a * b 의 곱셈은 b 번 적용한 successor 를 a 번 적용하면 되므로
mul = \s z -> x (y s) z
c2i (mul two five)
-- 10
Examples
id :: a -> a
id = \x -> x
compose :: [a -> a] -> (a -> a)
compose = foldr (.) id
id 함수는 받은걸 그대로 돌려주기 때문에 id . f, f . id 는 f 입니다. 따라서 함수 리스트를 위한 foldr 의 초기값으로 id 를 사용할 수 있습니다.
String Transmitter
간단한 문자열 전송을 모델링한 코드를 작성해 봅시다.
import Data.Char
type Bit = Int
bin2int :: [Bit] -> Int
bin2int bits = sum [w * b | (w, b) <- zip weights bits]
where weights = iterate (*2) 1
-- or
-- bin2int bitis = foldr (\x acc -> x + acc * 2) 0
int2bin :: Int -> [Bit]
int2bin 0 = []
int2bin n = n `mod` 2 : int2bin(n `div` 2)
make8 :: [Bit] -> [Bit]
make8 bits = take 8 (bits ++ repeat 0)
encode :: String -> [Bit]
encode = concat . map (make8 . int2bin . ord)
chop8 :: [Bit] -> [[Bit]]
chop8 [] = []
chop8 bits = take 8 bits : chop8 (drop 8 bits)
decode :: [Bit] -> String
decode = map (chr . bin2int) . chop8
channel :: [Bit] -> [Bit]
channel = id
transmit :: String -> String
transmit = decode . channel . encode
재밌는 부분은 마지막 channel 부분인데요, id 함수를 써서 인코딩된 문자열이 바로 디코딩을 위해 전송된다는 것을 표현했습니다.
위 코드 중에서 int2bin 과 chop8 은 헤드에 특정 연산을 수행하고, tail 에 나머지 연산을 수행 한 결과를 다시 재귀적으로 호출하는 패턴을 가지고 있는데요, unfold 함수로 추상화 할 수 있습니다.
쉽게 말해서 fold 가 리스트를 접어 (folding) 원소 하나로 만든다면, unfold 는 리스트를 더 한단계 펼친다고 볼 수 있습니다.
unfold p h t x
| p x = []
| otherwise = h x : unfold p h t (t x)
그리하면 구현을
type Bit = Int
int2bin :: Int -> [Bit]
int2bin = unfold (== 0) (`mod` 2) (`div` 2)
chop8 :: [Bit] -> [[Bit]]
chop8 = unfold null (take 8) (drop 8)
map 과 iterate 도 구현할 수 있습니다.
map2 f = unfold null (f . head) tail
iterate' f = unfold (const False) id f -- const False is pred. always return False
여기서 const False 는 항상 False 만 돌려주는 predicate 라 보시면 됩니다.
References
(1) DelftX FP 101x in edx
(2) https://sadakurapati.wordpress.com
(3) Programming in Haskell, Chapter 6, 7
(4) http://www.pling.org.uk/cs/fun.html
