Practical 시리즈는 AWS 환경 위에서 데이터 인프라를 구축하는데 참고할만한 내용들을 담고 있습니다. 이 글은 그 중 Practical Spark 의 한 챕터입니다. 이번 챕터에서는 Spark 가 무엇인지, 어떤 기능들을 제공하는지 살펴보며 Spark 에 익숙해지는 시간을 가져보겠습니다.

Practical 시리즈는 AWS 환경 위에서 데이터 인프라를 구축하는데 참고할만한 내용들을 담고 있습니다. 아래의 내용들을 주로 다룹니다.
- Practical Spark
- Practical Kafka
- Practical Kubernetes
- Practical AWS
이 블로그에 작성된 내용은 위 시리즈 중 Gitbook 으로 작성된 Practical Spark 를 옮긴 것입니다. 원본 Gitbook 와 실습에 사용하는 코드는 아래의 링크에서 보실 수 있습니다.
- (Spark Batch) https://1ambda.gitbook.io/practical-data-pipeline/02-processing/2.2-batch
- (Spark Stream) https://1ambda.gitbook.io/practical-data-pipeline/02-processing/2.4-stream
- (Code) https://github.com/1ambda/practical-data-pipeline-code
Spark Intro
Apache Spark 는 데이터 처리를 위한 범용 프레임워크 입니다. 데이터 파이프라인을 위해 많이 사용되며, 산업 표준에 가깝습니다.
Languages and Libraries
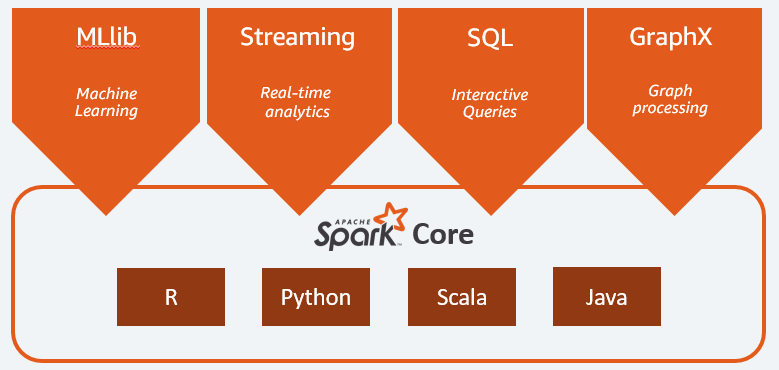
Scala 이외에도 Python, R 등 다양한 언어를 지원하며 데이터 처리를 위한 라이브러리가 많이 존재합니다. (Spark 관련 Third Party A 목록)
Supported API Levels
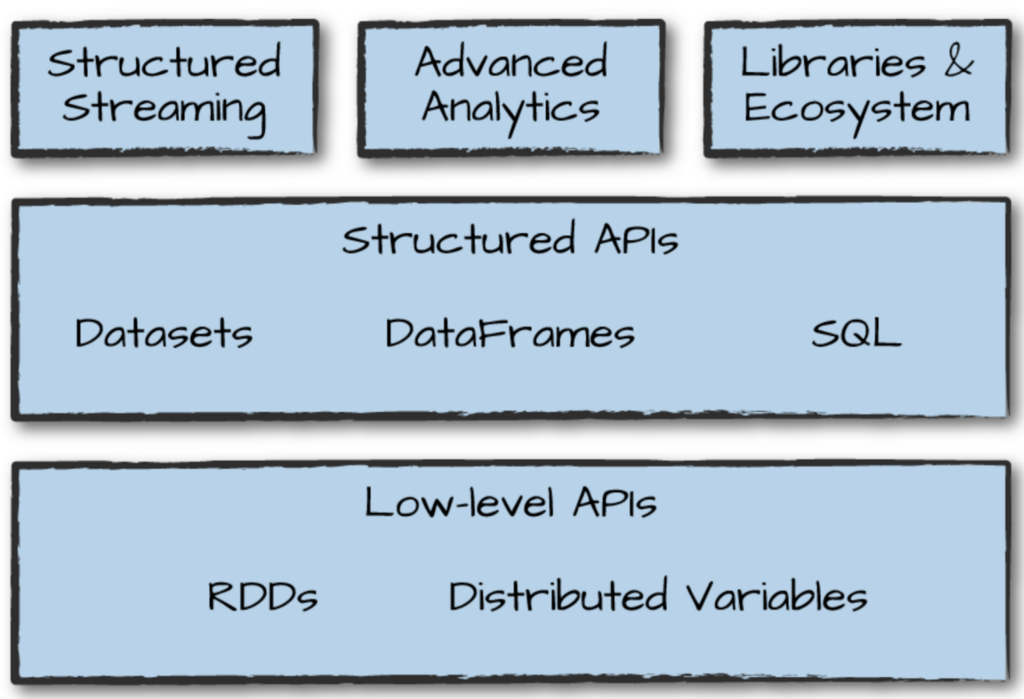
Spark SQL / Dataframe / Dataset API 등 다양한 형태의 API 를 제공해 사용자 편의 및 개발 환경에 따라 자유롭게 선택할 수 있습니다.
Storage Connectors

다양한 Storage 와 연동되는 Connector 가 존재합니다.
Cluster Managers
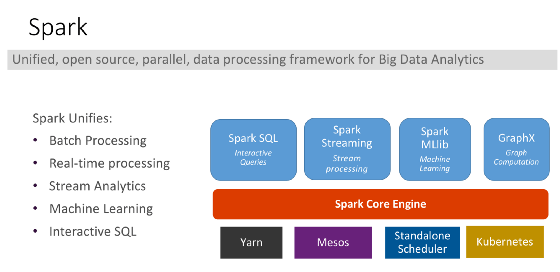


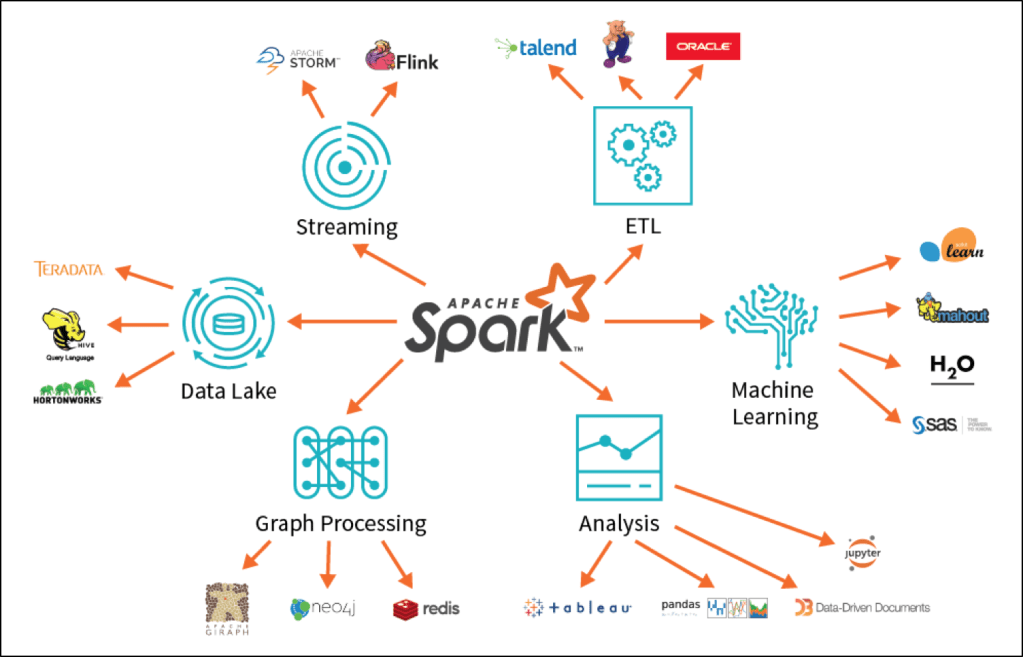
- 다양한 실행 모드 및 환경을 지원해 어느 환경에서나 사용할 수 있습니다.
- Spark Shell / Jupyter Notebook
- Local Mode / Client Mode / Cluster Mode
- Spark Batch / Stream Streaming
- Standalone / Yarn / Kubernetes Environment
Summary
요약하면 Spark 는
- 여러 환경과 모드를 지원하며
- 다양한 커넥터를 이용해 데이터를 추출 및 저장이 가능하고
- 사용자 편의에 맞추어 언어와 API, 그리고 라이브러리를 선택해
- 분산처리를 수행할 수 있는 범용 데이터 처리 도구입니다.
| spark | |
| .read // 데이터를 읽어옵니다. | |
| .format("jdbc") // "jdbc" 뿐 아니라 "kafka" 등 다양한 Format 을 사용할 수 있습니다 | |
| .join(...) // 다른 데이터와 Join (병합) 합니다. | |
| .where(...) // 데이터 Row 필터링하거나 | |
| .selectExpr(...) // 필요한 Column 만 선택합니다. | |
| repartition(5, "col1") // 얼마나 / 어떤 기준으로 분산해 처리할지를 정의합니다 | |
| .groupBy(...) // 집계 연산을 수행합니다 | |
| .agg(...) | |
| repartition(...) // 얼마나 / 어떤 기준으로 분산해 저장할지를 정의합니다. | |
| .write | |
| .format("kafka") // 데이터를 Parquet Format | |
| .option(...) // 원하는 옵션을 주어 | |
| .save(...) // 저장합니다. |
예를 들어 위 코드에서는 Spark 를 이용해
- JDBC (MySQL) Driver 로 데이터를 읽어
- 다른 데이터와 Join 하고
- Row 필터링 / Column 선택 등을 수행한 뒤
- 원하는 기준으로 집계 연산 (Group By) 를 수행하고
- 마지막으로는 Kafka 로 내보냅니다.
이 과정에서 사용자는 Spark 만 알아도 다양한 저장소 (Hive, S3, Kafka, MySQL) 와 다양한 Format (Avro, Parquet, CSV) 을 이용할 수 있고, Pandas 프레임워크 또는 RDB 의 SQL 이 제공하는 거의 유사한 API 와 문법을 이용해 데이터를 가공할 수 있습니다.또한 컴퓨팅은 분산처리되어 발생하므로, 기존의 단일 머신에서 수행되는 Pandas 컴퓨팅 / RDB SQL 컴퓨팅 보다 더 큰 데이터를 빠른 시간 내에 처리할 수 있습니다.
다음 챕테 Spark Tutorial 에서는 Spark 를 실제로 사용해보며 다른 데이터 처리 프레임워크 대비 Spark 가 주는 이점에 대해 논의해 보겠습니다.
