Practical 시리즈는 AWS 환경 위에서 데이터 인프라를 구축하는데 참고할만한 내용들을 담고 있습니다. 이 글은 그 중 Practical Spark 의 한 부분입니다. 이번 챕터에서는 기본적인 DataFarme 의 사용법을 알아보며 Spark 를 익혀보겠습니다. 다루는 주제는 DataFrame, Dataset 그리고 Spark SQL 입니다.

Practical 시리즈는 AWS 환경 위에서 데이터 인프라를 구축하는데 참고할만한 내용들을 담고 있습니다. 아래의 내용들을 주로 다룹니다.
- Practical Spark
- Practical Kafka
- Practical Kubernetes
- Practical AWS
이 블로그에 작성된 내용은 위 시리즈 중 Gitbook 으로 작성된 Practical Spark 를 옮긴 것입니다. 원본 Gitbook 와 실습에 사용하는 코드는 아래의 링크에서 보실 수 있습니다.
- (Spark Batch) https://1ambda.gitbook.io/practical-data-pipeline/02-processing/2.2-batch
- (Spark Stream) https://1ambda.gitbook.io/practical-data-pipeline/02-processing/2.4-stream
- (Code) https://github.com/1ambda/practical-data-pipeline-code
Spark Tutorial
Hello Spark
Spark 를 활용해 사용자는 데이터를 읽고 가공 할 수 있습니다. 예를 들어, 아래의 코드는 파일 시스템에 있는 작은 CSV 파일을을 읽어 몇 가지 함수를 이용해 가공하는 샘플입니다.
환경은 편의에 따라 Databricks Notebook / 로컬 내 PySpark Shell 등 자유롭게 사용할 수 있습니다. 이 문서에서는 코드를 간략히 표현하기 위해 PySpark 3 와 DataFrame API 를 사용했습니다.
| from pyspark.sql.functions import * | |
| from pyspark.sql.types import * | |
| # 현재 디렉토리에 CSV 파일을 다운받은 후 아래 코드를 실행합니다. | |
| # 해당 파일의 확장자는 `.csv` 로 되어있으나, 실제로 데이터의 구분자는 `\t` (탭) 입니다 | |
| # DataBricks 로 실습한다면 경로를 "/FileStore/tables/marketing_campaign.csv" 로 변경합니다 | |
| df = spark.read.load("./marketing_campaign.csv", | |
| format="csv", | |
| sep="\t", | |
| inferSchema="true", | |
| header="true") |
위 코드를 실행하면, CSV 파일로 존재하는 데이터를 Spark 읽습니다.
df 라는 DataFrame 변수에 데이터를 로딩한 결과를 저장했으므로, df 변수를 통해 읽은 데이터를 조작해볼 수 있습니다.
| df.printSchema() # 스키마, 즉 데이터의 형태를 보여줍니다. | |
| root | |
| |-- ID: integer (nullable = true) | |
| |-- Year_Birth: integer (nullable = true) | |
| |-- Education: string (nullable = true) | |
| |-- Marital_Status: string (nullable = true) | |
| |-- Income: integer (nullable = true) | |
| |-- Kidhome: integer (nullable = true) | |
| |-- Teenhome: integer (nullable = true) | |
| |-- Dt_Customer: string (nullable = true) | |
| |-- Recency: integer (nullable = true) | |
| |-- MntWines: integer (nullable = true) | |
| |-- MntFruits: integer (nullable = true) | |
| ... (생략) |
spark.read.load 를 사용해 데이터를 로딩할 때, inferSchema="true", header="true" 옵션을 사용했으므로 Spark 가 CSV 파일의 첫 줄을 헤더로 인식해 스키마에서 Column 명을 지정하고, 데이터를 읽으며 컬럼의 타입값을 자동으로 결정합니다. (integer, string 등)
데이터를 보거나 Row (행) 의 숫자를 세기 위해서는 df, 즉 DataFrame 의 다양한 함수를 사용할 수 있습니다.
| df.count() # 로딩한 데이터의 숫자를 센 후 출력합니다 | |
| df.show() # 데이터를 일부 콘솔에 출력합니다. | |
| df.toPandas() # PySpark 에서 사용할 수 있는 함수로, Jupyter 에서 데이터를 편하게 볼 수 있습니다. |
| # df.count() 의 결과 | |
| 2240 | |
| # df.toPandas() 의 결과 (일부 Row, Column 생략) | |
| ID Year_Birth Education Marital_Status Income Kidhome Teenhome Dt_Customer Recency MntWines ... NumWebVisitsMonth AcceptedCmp3 AcceptedCmp4 AcceptedCmp5 AcceptedCmp1 AcceptedCmp2 Complain Z_CostContact Z_Revenue Response | |
| 0 5524 1957 Graduation Single 58138.0 0 0 04-09-2012 58 635 ... 7 0 0 0 0 0 0 3 11 1 | |
| 1 2174 1954 Graduation Single 46344.0 1 1 08-03-2014 38 11 ... 5 0 0 0 0 0 0 3 11 0 | |
| 2 4141 1965 Graduation Together 71613.0 0 0 21-08-2013 26 426 ... 4 0 0 0 0 0 0 3 11 0 | |
| 3 6182 1984 Graduation Together 26646.0 1 0 10-02-2014 26 11 ... 6 0 0 0 0 0 0 3 11 0 | |
| 4 5324 1981 PhD Married 58293.0 1 0 19-01-2014 94 173 ... 5 0 0 0 0 0 0 3 11 0 | |
| ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... | |
| 2235 10870 1967 Graduation Married 61223.0 0 1 13-06-2013 46 709 ... 5 0 0 0 0 0 0 3 11 0 | |
| 2236 4001 1946 PhD Together 64014.0 2 1 10-06-2014 56 406 ... 7 0 0 0 1 0 0 3 11 0 | |
| 2237 7270 1981 Graduation Divorced 56981.0 0 0 25-01-2014 91 908 ... 6 0 1 0 0 0 0 3 11 0 | |
| 2238 8235 1956 Master Together 69245.0 0 1 24-01-2014 8 428 ... 3 0 0 0 0 0 0 3 11 0 |
Hello DataFrame

Spark 는 데이터를 테이블 형태로 다룰 수 있도록 API 를 제공합니다. 물리적으로는 여러 머신의 메모리에 분산되어 있더라도, 사용자가 데이터를 마치 하나의 테이블처럼 논리적으로 다룰 수 있습니다.
우선 데이터를 간단히 조작해보겠습니다. 컬럼 이름을 쉽게 다루기 위해, 몇개만 선택후 이름을 변경하겠습니다.
| # 컬럼을 선택하고 이름을 변경합니다. | |
| # SQL 의 SELECT 'ID' as id, 'Year_Birth' as 'year_birth'... 과 동일합니다. | |
| dfSelected = df.select( | |
| col("ID").alias("id"), | |
| col("Year_Birth").alias("year_birth"), | |
| col("Education").alias("education"), | |
| col("Kidhome").alias("count_kid"), | |
| col("Teenhome").alias("count_teen"), | |
| col("Dt_Customer").alias("date_customer"), | |
| col("Recency").alias("days_last_login") | |
| ) | |
| dfSelected.count() | |
| dfSelected.printSchema() |
| # dfSelected.count() 의 결과 | |
| 2240 | |
| # dfSelected.printSchema() | |
| root | |
| |-- id: integer (nullable = true) | |
| |-- year_birth: integer (nullable = true) | |
| |-- education: string (nullable = true) | |
| |-- count_kid: integer (nullable = true) | |
| |-- count_teen: integer (nullable = true) | |
| |-- date_customer: string (nullable = true) | |
| |-- days_last_login: integer (nullable = true) |
여기서 기억하고 넘어가야 할 부분이 몇 가지 있습니다.
- 컬럼 이름을 변경한 결과를
dfSelectedDataFrame 에 저장했기 때문에 최초의dfDataFrame 은 그대로 존재합니다. 따라서df와dfSelected는 다른 DataFrame 입니다. - 그러나 DataFrame 은 논리적인 테이블이므로 실제 물리적으로 데이터가 복사되어
df,dfSelect두 벌이 되는 것은 아닙니다. - 물리적인 데이터는 여전히 Disk 에 CSV 파일로 존재하고,
count()toPandas()와 같은 RDD 액션을 수행할 때 데이터를 메모리로 읽어 처리 하게됩니다. RDD 와 액션에 대해서는 추후 다른 챕터에서 더 자세히 설명하겠습니다.
| # df.rdd.id() 실행 결과 | |
| <bound method RDD.id of MapPartitionsRDD[25] at javaToPython at NativeMethodAccessorImpl.java:0> | |
| # dfSelected.rdd.id() 실행 결과 | |
| <bound method RDD.id of MapPartitionsRDD[31] at javaToPython at NativeMethodAccessorImpl.java:0> |
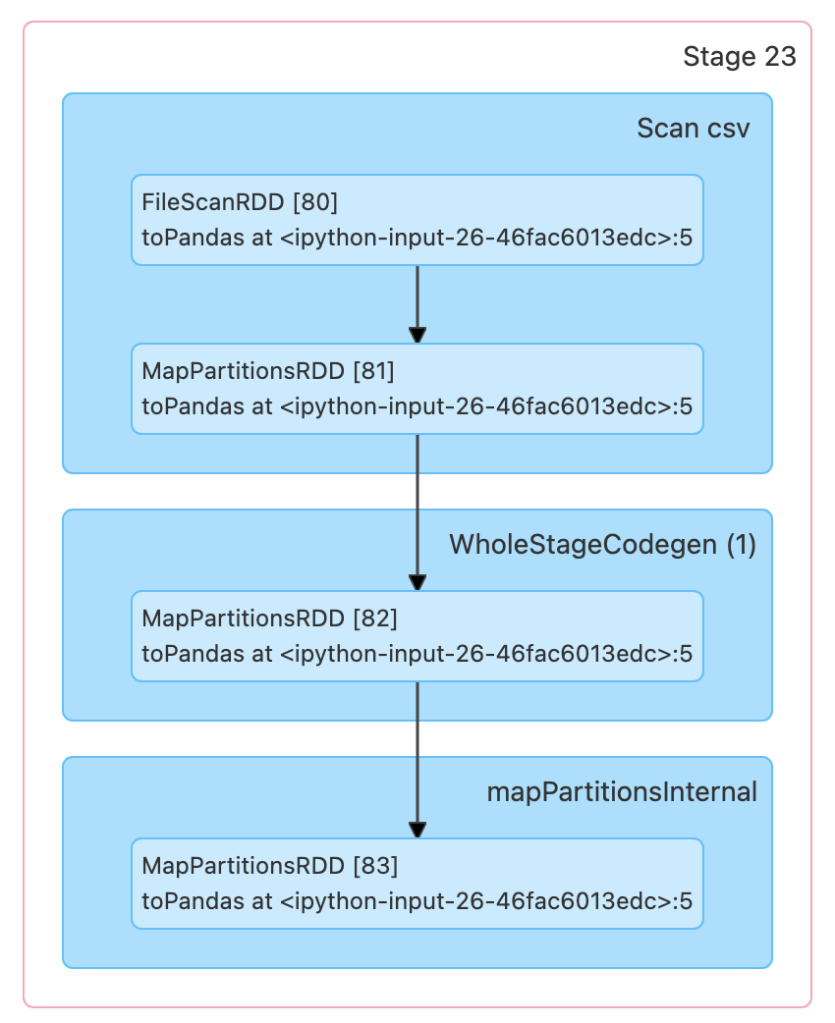
위 스크린샷은 Spark UI 에서 확인할 수 있는 Stage 정보로, toPandas() 를 호출하기 까지 실행되는 Spark 연산입니다.
이제 데이터를 로딩해서 원하는 컬럼만 추출했으니 데이터를 일부 가공해보겠습니다.
count_kid는 고객의 유아 자녀,count_teen은 고객의 초등학생 이상 자녀를 나타내는 컬럼인데, 이 값을 더한count_children컬럼을 만들어 보겠습니다. 다만 이 때, 양쪽 또는 한쪽의 값이 NULL 일 수 있으므로 덧셈에 유의해야 합니다.education컬럼은 졸업 학위를 나타냅니다. 이 때2n Cycle값을 허용하지 않는다는 정책이 세워져, 대신 문자열NONE값을 넣도록 하겠습니다. 여기서는 IF ELSE 와 유사한 SQL 구문인 CASE WHEN 을 사용해 보겠습니다.date_customer는 최초 가입일 컬럼인데 팀원의 실수로 데이터가 잘못되었다고 가정하고 7년을 더해보겠습니다. 예를 들어2013-01-01이면 변경 후에는2020-01-01이 되어야 합니다.
Spark DataFrame API 는 SQL 에 대응되는 함수가 대부분 존재하므로 어떻게 다룰지 모르더라도 SQL 함수를 기반으로 생각해보고 구글링을 통해 해결할 수 있습니다.
우선 시작 전에 통계 정보와 스키마를 다시 살펴 보면,
| dfSelected.printSchema() # 스키마를 확인합니다. | |
| dfSelected.describe().show() # 통계 정보를 확인합니다. PySpark 에서는 `show` 대신 `toPandas` 를 활용할 수 있습니다. | |
| # printSchema() 의 출력 결과 | |
| root | |
| |-- id: integer (nullable = true) | |
| |-- year_birth: integer (nullable = true) | |
| |-- education: string (nullable = true) | |
| |-- count_kid: integer (nullable = true) | |
| |-- count_teen: integer (nullable = true) | |
| |-- date_customer: string (nullable = true) | |
| |-- days_last_login: integer (nullable = true) | |
| # describe().show() 의 출력 결과 | |
| +-------+------------------+------------------+---------+-------------------+------------------+-------------+-----------------+ | |
| |summary| id| year_birth|education| count_kid| count_kid|date_customer| days_last_login| | |
| +-------+------------------+------------------+---------+-------------------+------------------+-------------+-----------------+ | |
| | count| 2240| 2240| 2240| 2240| 2240| 2240| 2240| | |
| | mean| 5592.159821428571|1968.8058035714287| null|0.44419642857142855| 0.50625| null| 49.109375| | |
| | stddev|3246.6621975643416|11.984069456885827| null| 0.5383980977345935|0.5445382307698761| null|28.96245280837821| | |
| | min| 0| 1893| 2n Cycle| 0| 0| 01-01-2013| 0| | |
| | max| 11191| 1996| PhD| 2| 2| 31-12-2013| 99| | |
| +-------+------------------+------------------+---------+-------------------+------------------+-------------+-----------------+ |
| dfConverted1 = dfSelected\ | |
| withColumn("count_children", coalesce("count_kid", lit(0)) + coalesce("count_teen", lit(0))) | |
| dfConverted1\ | |
| .select(col("id"), col("count_kid"), col("count_teen"), col("count_children"))\ | |
| .limit(5)\ | |
| .show() | |
| # `show() 출력 결과 | |
| +----+---------+----------+--------------+ | |
| | id|count_kid|count_teen|count_children| | |
| +----+---------+----------+--------------+ | |
| |5524| 0| 0| 0| | |
| |2174| 1| 1| 2| | |
| |4141| 0| 0| 0| | |
| |6182| 1| 0| 1| | |
| |5324| 1| 0| 1| | |
| +----+---------+----------+--------------+ |
count_kid 또는 count_teen 컬럼에 미래에는 NULL 값이 들어올 수도 있으므로 coalesce("count_kid", lit(0)) 와 같이 기본값을 0 으로 세팅합니다. 그리고 두 컬럼의 값을 더해 count_children 컬럼을 만듭니다.
이후에는 결과 DataFrame 인 dfConverted1 에서 보기 쉽게 원하는 컬럼만 선택해서 5개만 추출해 데이터를 확인해봅니다. 아까 언급했던 바와 같이 Spark DataFrame 은 Immutable 하므로 (더 엄밀히는 DataFrame 을 구성하는 RDD) dfConverted1.select 구문은 그 위에서 만든 dfConverted1에 영향을 미치지 않습니다.
그 다음으로는 education 컬럼을 살펴보고 변경해보겠습니다.
| # 이 작업에서는 컬럼 이름을 가공하지 않으므로, `select` 내에서 `col` 함수를 사용하지 않았습니다. | |
| # Spark 는 이와 같이 API 에서 다양한 형태로 사용자의 편의성을 지원합니다. | |
| dfConverted1\ | |
| .select("education")\ | |
| .distinct()\ | |
| .show() | |
| # `show()` 출력 결과 | |
| +----------+ | |
| | education| | |
| +----------+ | |
| | 2n Cycle| | |
| | PhD| | |
| | Master| | |
| |Graduation| | |
| | Basic| | |
| +----------+ |
앞서 언급한 것과 같이 2n Cycle 값은 CASE WHEN 구문을 사용해 NONE 으로 변경하도록 하겠습니다.
| educationInvalid = '2n Cycle' | |
| educationDefault = 'NONE' | |
| # 다음 SQL 구문과 동일합니다. | |
| # | |
| # SELECT CASE WHEN education = '2n Cycle' THEN 'NONE' ELSE education as education | |
| # | |
| dfConverted2 = dfConverted1.withColumn( | |
| "education", | |
| when(col("education") == lit(educationInvalid), educationDefault).otherwise(col("education")) | |
| ) | |
| dfConverted2.select("education").distinct().show() | |
| # `show()` 의 출력 결과 | |
| +----------+ | |
| | education| | |
| +----------+ | |
| | PhD| | |
| | Master| | |
| |Graduation| | |
| | Basic| | |
| | NONE| | |
| +----------+ |
오늘 작업한 education 컬럼에는 NULL 값이 없었지만, 미래에는 들어올지 모릅니다. 만약 정책적으로 지정한 값 이외에 허용되지 않는 데이터를 전부 NONE 으로 세팅하려면 코드를 어떻게 변경해야 할까요?
PySpark 의 API 문서에서 isin 함수를 살펴보고, 이것을 통해 문제를 해결할 수 있을지 고민해 봅니다.
Spark DataFrame API 는 selectExpr 이란 함수를 제공합니다. SQL 문법을 사용할 수 있습니다. 예를 들어, 위와 동일한 작업을 할 때 다음처럼 코드를 작성할 수 있습니다.
| dfConverted3 = dfConverted1\ | |
| .selectExpr("*", | |
| f"CASE WHEN education == '{educationInvalid}' THEN '{educationDefault}' ELSE education END as education" | |
| ) |
이제 마지막으로 date_customer 컬럼을 날짜 타입으로 변경 후 6년을 더해 보겠습니다. 만약 월 (Month) 가 아니라 일 (Day) 기준으로 변경하고 싶다면 date_add 함수를 사용할 수 있습니다.
| # 기존 date_customer 컬럼의 값과 비교를 위해 `date_joined` 라는 다른 이름으로 컬럼 값 변환 결과를 저장합니다 | |
| # 1. 이 과정에서 `to_date` 함수를 사용해 타입을 변경하고 | |
| # 2. `add_months` 함수를 통해 72개월 (= 6년) 을 기존 값에 추가했습니다. | |
| dfWithJoined = dfConverted2.withColumn("date_joined", add_months(to_date(col("date_customer"), "d-M-yyyy"), 72)) | |
| dfWithJoined.select("date_customer", "date_joined").limit(5).show() | |
| dfWithJoined.printSchema() | |
| # `show()` 출력 결과 | |
| +-------------+-----------+ | |
| |date_customer|date_joined| | |
| +-------------+-----------+ | |
| | 04-09-2012| 2018-09-04| | |
| | 08-03-2014| 2020-03-08| | |
| | 21-08-2013| 2019-08-21| | |
| | 10-02-2014| 2020-02-10| | |
| | 19-01-2014| 2020-01-19| | |
| +-------------+-----------+ | |
| # `printSchema()` 출력 결과 | |
| root | |
| |-- id: integer (nullable = true) | |
| |-- year_birth: integer (nullable = true) | |
| |-- education: string (nullable = true) | |
| |-- count_kid: integer (nullable = true) | |
| |-- count_teen: integer (nullable = true) | |
| |-- date_customer: string (nullable = true) | |
| |-- days_last_login: integer (nullable = true) | |
| |-- count_children: integer (nullable = false) | |
| |-- date_joined: date (nullable = true) |
이쯤에서 분산처리는 어디서 하고 실시간 처리는 어떻게 하냐는 질문이 생기실 수 있습니다.
Spark 는 사용자가 데이터를 처리하는 비즈니스 로직과, 분산처리 및 로딩 가공 등을 담당하는 인프라 로직을 분리해 사용할 수 있도록 아주 높은 수준에서 추상화를 제공합니다. 이로인해 사용자는
- Spark Batch / Spark (Structured) Stream 구분없이 데이터를 가공할 수 있습니다. 비즈니스 로직을, 즉 코드를 재활용하는 것이 가능해 Stream 의 State (상태) 를 다시 복구하기 위한 배치 작업을 쉽게 만들 수 있습니다.
- 분산 처리 / 데이터의 로딩 및 저장 등은 비즈니스 로직과 분리되므로 사용자는 데이터를 하나의 테이블처럼 취급해 가공에만 집중할 수 있습니다.
- 여기에도 물론 예외는 있습니다. 공식 Kinesis 등 일부 커넥터는 DataFrame 이 아니라 RDD 형태로 데이터를 가공해야 할 수 있습니다. 또한 Stream 의 경우 State (상태) 와 Window (단위 간격) 을 다루므로 추가적인 API 가 존재할 수 있습니다.
위에서 다루었던 예제에서는 1개의 CSV 파일 내에 2240 개의 Row 밖에 없었지만, 데이터가 매우 크다고 가정하면 하나의 파일로 만들 수 없어, 일반적으로 파일을 분할해 S3 나 HDFS 등에 보관하게 됩니다. Spark 는 데이터 가공시에 여러 파일들을 메모리에 읽어 처리할 수 있습니다.
이 과정에서 Spark 를 Local 모드 (단일 머신) 모드로 사용한다면 하나의 머신에서 처리가 되고, 여러 머신에서 분산처리를 진행하려면 Client / Cluster 모드를 선택할 수 있습니다. 모드와 환경 부분은 Spark Architecture 부분에서 설명 드리겠습니다.
DataFrame, Dataset and SQL
Spark 는 Scala, Java, R, Python, SQL 등 다양한 언어를 제공합니다. 이번 섹션에서는 Python 언어, 즉 PySpark 를 사용해보았으며 데이터를 다루기 위해 DataFrame API 를 사용해 보았습니다.
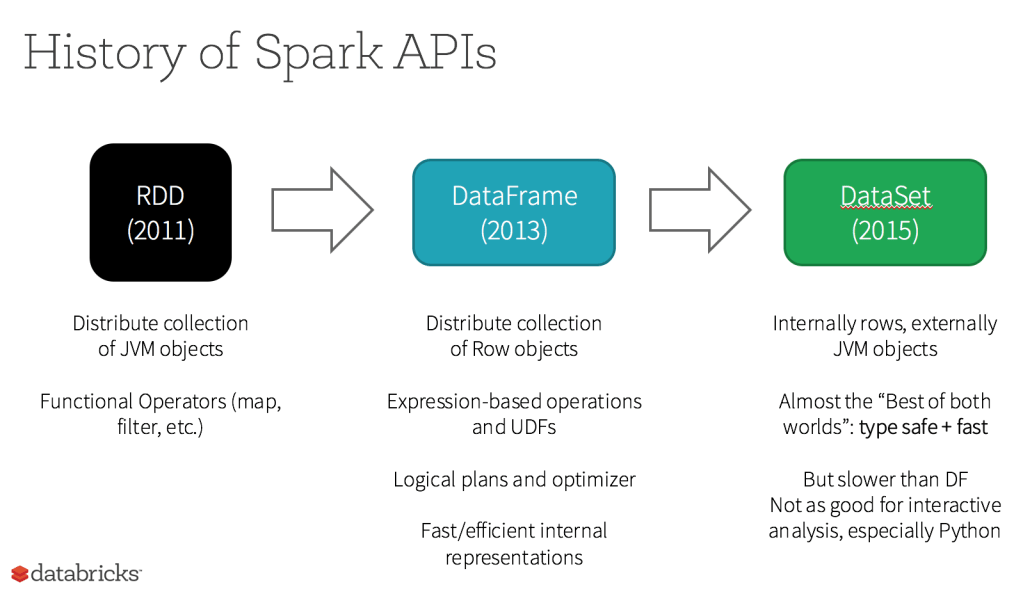
Spark 초기 버전은 RDD 만 지원했으나, DataFrame / Dataset 과 같은 고수준의, 사용자가 다루기 쉬운 API 들이 추가되었습니다. Spark 2.0 부터는 DataFrame 은 Dataset[Row] 타입이 됨으로써 DataFrame 과 Dataset 이 통합되었습니다.
| { | |
| "device_id": 198164, | |
| "device_name": "sensor-pad-198164owomcJZ", | |
| "ip": "80.55.20.25", | |
| "cca2": "PL", | |
| "cca3": "POL", | |
| "cn": "Poland", | |
| "latitude": 53.08, | |
| "longitude": 18.62, | |
| "scale": "Celsius", | |
| "temp": 21, | |
| "humidity": 65, | |
| "battery_level": 8, | |
| "c02_level": 1408, | |
| "lcd": "red", | |
| "timestamp": 1458081226051 | |
| } |
| case class DeviceIoTData ( | |
| battery_level: Long, | |
| c02_level: Long, | |
| cca2: String, | |
| cca3: String, | |
| cn: String, | |
| device_id: Long, | |
| device_name: String, | |
| humidity: Long, | |
| ip: String, | |
| latitude: Double, | |
| lcd: String, | |
| longitude: Double, | |
| scale:String, | |
| temp: Long, | |
| timestamp: Long) | |
| val ds = spark.read(...).as[DeviceIoTData] | |
| val dsAvgTmp = ds | |
| .filter(d => {d.temp > 25}) | |
| .map(d => (d.temp, d.humidity, d.cca3)) | |
| .groupBy($"_3").avg() |
참고로 Dataset API 는 Type 이 지원되는 언어인 Scala / Java 만 지원합니다. Python 및 R 은 DataFrame API 를 이용할 수 있습니다.
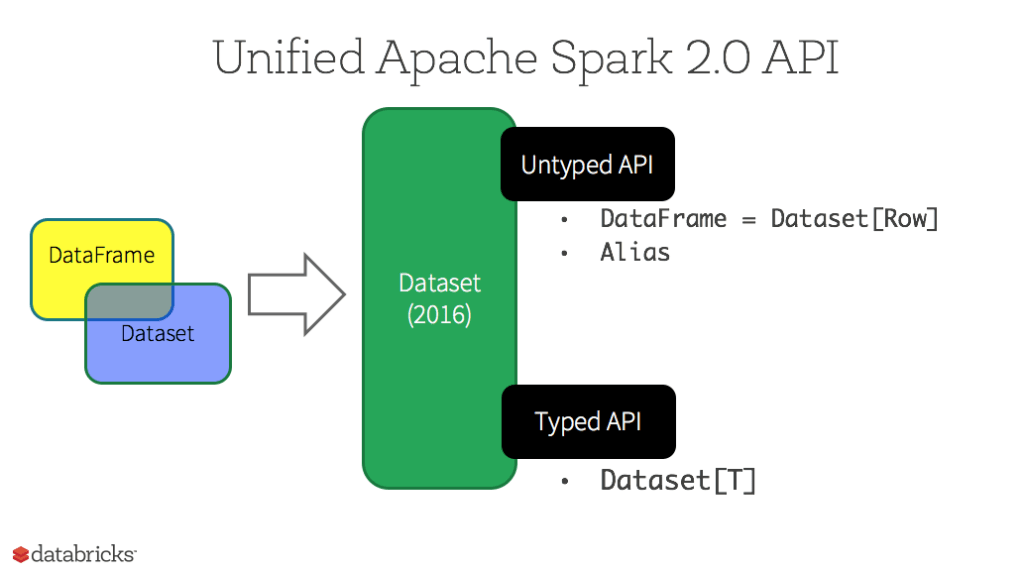
어떤 API 가 ‘우월하거나‘ 그렇지는 않습니다. 생산성과 타입 안전성을 고려해 어떤 API 를 사용할지 취사 선택할 수 있습니다.
- 데이터를 탐색하거나 빠르게 (생산성 있게) 가공하고 싶다면 SQL API 를 선택할 수 있습니다
- 조금 더 타입을 갖추고 싶다면, DataFrame API 를 이용하고 UDF 등을 위한 Unit Test 를 작성할 수 있습니다
- 복잡한 Spark Streaming Application 을 작성하고 Kafka Avro 데이터를 읽어 가공한다면 Scala 로 Dataset 의 함수형 API 를 이용해 가공할 수 있습니다
- 낮은 수준의 API 인 RDD 를 이용한다면 여러분이 더 많은 컨트롤을 가질 수 있습니다. 많은 제어권 = 더 많은 책임인 경우가 대다수이므로, 고도의 촤적화 등 특별한 경우가 아니라면 사용하지 않는 편이 낫습니다.
- 그리고 일정 규모에서는 머신을 더 부어 넣는게 고도의 최적화를 유지보수하는 것 보다 저렴합니다. Cloud 시대에는 기계가 사람보다 구하기 쉽기 때문입니다.
- 예를 들어, DataFrame 의 경우에는 Spark 가 컬럼의 타입을 알고 있으므로 단순히 Row 로 표현되는 RDD 에 비해 Serialization / Deserializaiton 을 효율적으로 수행할 수 있습니다. Dataset 을 사용한다면 Encoder 를 이용해 JVM 에 최적화된 형태로 객체를 Serialization / Deserialization 을 수행할 수 있습니다.
아래 그림은 RDD 가 아니라 Spark SQL 또는 DataFrame (Dataset) API 를 사용할 경우 Spark 의 Catalyst Optimizer 를 이용해 최적화 되는 과정을 보여줍니다.



Hello Dataset
위에서 다루었던 DataFrame 은 Dataset[Row] 입니다. 즉 Row 라는 타입의 Dataset 이 DataFrame 인데, Dataset 은 사용자가 지정한 타입도 당연히 사용할 수 있습니다.
예를 들어 MarketingUser 라는 클래스가 있을 때 Dataset[MarketingUser] 처럼 사용할 수 있습니다.
A Dataset is a distributed collection of data. Dataset is a new interface added in Spark 1.6 that provides the benefits of RDDs (strong typing, ability to use powerful lambda functions) with the benefits of Spark SQL’s optimized execution engine.
in Datasets and DataFrames
Dataset 은 Scala / Java 언어로만 사용할 수 있습니다. RDD 와 같이 혹은 List 를 다루듯이 map, flatmap, filter 등 함수형 Collection API 의 일부를 사용할 수 있고 DataFrame 과 같이 SQL Optimizer 에 의해 최적화 됩니다.
일반적으로 Streaming 이나 Batch Application 만들때 주로 사용합니다. 데이터 탐색 / 프로토타이핑시에는 생산성을 이유로 PySpark 가 자주 사용됩니다.
이제 데이터를 읽어 Dataset API 를 사용해보겠습니다.
| import org.apache.spark.sql.functions._ | |
| import org.apache.spark.sql.types._ | |
| // 만약 Databricks 노트북을 사용한다면 경로를 | |
| // `/FileStore/tables/marketing_campaign.csv"` 로 변경할 수 있습니다. | |
| val df = spark.read | |
| .format("csv") | |
| .option("format", "csv") | |
| .option("sep", "\t") | |
| .option("inferSchema", "true") | |
| .option("header", "true") | |
| .load("marketing_campaign.csv") |
| // df.printSchema() | |
| root | |
| |-- ID: integer (nullable = true) | |
| |-- Year_Birth: integer (nullable = true) | |
| |-- Education: string (nullable = true) | |
| |-- Marital_Status: string (nullable = true) | |
| |-- Income: integer (nullable = true) | |
| |-- Kidhome: integer (nullable = true) | |
| |-- Teenhome: integer (nullable = true) | |
| |-- Dt_Customer: string (nullable = true) | |
| |-- Recency: integer (nullable = true) | |
| |-- MntWines: integer (nullable = true) | |
| |-- MntFruits: integer (nullable = true) | |
| ... |
컬럼 이름을 가져와 소문자 또는 Camel Case 로 변경 하겠습니다. Scala 에서는 Case Class 에 Camel Case 를 주로 사용하기 때문입니다.
_* 연산자는 splats 이란 이름으로 불립니다. 배열 또는 리스트 등 컬렉션을 풀어 헤쳐 가변인자로 하나씩 넘겨 줍니다.
- 예를 들어
val columns = List("userId", "userName", "address")가 있다 가정했을 때 calculate(columns) 와 calculated(columns: _*) 는 다릅니다. 전자는 List 를 파라미터로 받는 함수이고 후자는 여러개의 개별 컬럼을 파라미터로 받는 함수입니다.
| def camelToUnderscores(name: String) = "[A-Z\\d]".r.replaceAllIn(name, {m => | |
| "_" + m.group(0).toLowerCase() | |
| }) | |
| def underscoresToCamel(name: String) = { | |
| val splitted = name.split("_") | |
| val converted = splitted.head.toLowerCase() +: splitted.tail.map(_.capitalize) | |
| converted.mkString | |
| } | |
| val columnsLower = df.columns.map(x => col(x).as(x.toLowerCase)) | |
| val columnsCamel = df.columns.map(x => col(x).as(underscoresToCamel(x))) | |
| val dfLower = df.select(columnsLower: _*) | |
| val dfCamel = df.select(columnsCamel: _*) |
위에서 사용자가 만든 함수를 통해 컬럼 이름을 변경해보았습니다. 출력해서 확인해보면 다음과 같습니다.
| // dfLower.select("id", "year_birth", "education", "income", "kidhome", "teenhome", "dt_customer").show() | |
| +----+----------+----------+------+-------+--------+-----------+ | |
| | id|year_birth| education|income|kidhome|teenhome|dt_customer| | |
| +----+----------+----------+------+-------+--------+-----------+ | |
| |5524| 1957|Graduation| 58138| 0| 0| 04-09-2012| | |
| |2174| 1954|Graduation| 46344| 1| 1| 08-03-2014| | |
| |4141| 1965|Graduation| 71613| 0| 0| 21-08-2013| | |
| |6182| 1984|Graduation| 26646| 1| 0| 10-02-2014| | |
| |5324| 1981| PhD| 58293| 1| 0| 19-01-2014| | |
| |7446| 1967| Master| 62513| 0| 1| 09-09-2013| | |
| | 965| 1971|Graduation| 55635| 0| 1| 13-11-2012| | |
| |6177| 1985| PhD| 33454| 1| 0| 08-05-2013| |
이제 필요한 컬럼만 선택해보겠습니다.
| val dfSelected = dfCamel.select("id", "yearBirth", "education", "income", "kidhome", "teenhome", "dtCustomer", "recency").cache() |
Dataset[T] 로 변경시 타입으로 사용할 사용자 커스텀 클래스 T, 즉 여기서는 MarketingUser 를 만들어보겠습니다.
- Case Class 는 불변성을 가지고 있어 데이터를 변경하면 새로운 인스턴스가 생성됩니다.
- Scala / Spark 에서는 자주 활용됩니다. (https://docs.scala-lang.org/ko/tour/case-classes.html)
| case class MarketingUser(userId: Int, | |
| yearBirth: Int, | |
| education: String, | |
| income: Int, | |
| kidhome: Int, | |
| teenhome: Int, | |
| dtCustomer: String, | |
| recency: Int) |
이제 dfSelected 를 Dataset 으로 변경해보겠습니다.
- Encoder 를 이용해
DataFrame[Row]을Dataset[T]으로 변경합니다. - Encoder 는 컬럼 타입을 바탕으로 최적화된 Serialization / Deserialization 을 합니다.
- 더 자세한 내용은 Spark Internals: Encoder 문서를 참고할 수 있습니다.
| val dsMarketingUser = dfSelected | |
| .withColumnRenamed("id", "userId") | |
| .as[MarketingUser] |
타입을 보면 다음과 같이 Dataset[MarketingUser] 임을 볼 수 있습니다.
| # dfSelected | |
| org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [id: int, yearBirth: int ... 6 more fields] | |
| # dsMaretingUser | |
| org.apache.spark.sql.Dataset[MarketingUser] = [userId: int, yearBirth: int ... 6 more fields] |
Dataset 도 DataFrame 과 같은 API 를 이용해 집계 연산이 가능합니다.
| dsMarketingUser.groupBy(col("education")).agg(sum("income")) |
DataFrame 에서는 select, withColumn 등을 이용해 컬럼을 가공했지만 Dataset 은 List 내 객체를 다루듯이 map, flatMap 등을 이용해 변경이 가능합니다.
| val dsUserFiltered = dsMarketingUser.filter(x => x.education == "Master") |
그런데 석사 학위 소지 사용자만 추출한 dsUserFiltered 를 보기 위해 show() 함수를 호출하면 다음처럼 오류가 발생하는 것을 볼 수 있습니다.
| # dsUserFiltered.show() | |
| Caused by: NullPointerException: Null value appeared in non-nullable field: | |
| - field (class: "scala.Int", name: "income") | |
| - root class: "$line9228218dd17046b3aa8b6bbe593dc28a520.$read.$iw.$iw.$iw.$iw.$iw.$iw.$iw.$iw.$iw.$iw.$iw.$iw.$iw.$iw.MarketingUser" | |
| If the schema is inferred from a Scala tuple/case class, or a Java bean, please try to use scala.Option[_] or other nullable types (e.g. java.lang.Integer instead of int/scala.Int). |
이는 NULL 값을 가지기 위해서 Scala 에서는 Int 가 아니라 Option[Int] 를 사용해야 하기 때문입니다.
따라서 오류에 나온대로 income 을 Option[Int] 로 변경해보겠습니다.
| case class MarketingUserRefined(userId: Int, | |
| yearBirth: Int, | |
| education: String, | |
| income: Option[Int], | |
| kidhome: Option[Int], | |
| teenhome: Option[Int], | |
| dtCustomer: String, | |
| recency: Option[Int]) | |
| val dsUserRefined = dfSelected | |
| .withColumnRenamed("id", "userId") | |
| .as[MarketingUserRefined] | |
| val dsUserFiltered = dsUserRefined.filter(x => x.education == "Master") | |
| dsUserFiltered.show() |
Map 함수도 이용해보겠습니다. 다만 Case Class 는 불변이기 때문에 한 필드를 생성하면 객체가 새로 생성됩니다. Copy 를 이용해 원하는 필드를 변경할 수 있습니다.
| val dsUserUpdated = dsUserFiltered | |
| .map(x => x.copy(yearBirth = x.yearBirth + 3)) |
Practice
실습 과제입니다.
조건입니다.
- 마케팅 플랫폼에서 최근 활동날짜가 10-30 일이 지난 (포함) 사용자에 대해서 재방문 Push 메세지를 보내려고 합니다.
- 보내려는 상품은 집에 아동 (
kidhome) 또는 청소년 자녀 (teenhome) 가 있는 경우입니다. - Push 메세지는 비용이 드므로, 구매 확률이 높은 사용자에게 보내기 위해 당사 플랫폼에서 구매 금액이 $30000 이상의 사용자만 추출합니다.
- Dataset API 를 이용합니다.
결과물은 아래와 같아야 합니다.
- 조건에 해당하는 사용자가 전체 몇 명인지 구해봅시다.
recency를 기준으로 10-20, 21-30 두 가지 그룹과 kidhome, teenhome 유무 여부에 따라 groupBy 를 통해 사용자가 몇 명인지 구분해봅니다. 이에 따라 마케팅 담당자는 Push 메세지를 다양화 할 수도 있습니다.- Case Class TargetUser 를 아래와 같이 생성하고 dsUserRefined.map(x-> TargetUser(…)) 을 통해
dsTargetUser를 만듭니다.
| TragetUser(userId, income, hasKidhome, hasTeenhome, recency) |
Summary
이번 챕터에서는 Spark 의 기본적인 개념과 사용법에 대해 알아보았습니다. 아래는 이번 챕터에서 다룬 핵심 키워드입니다. 시간이 된다면 구글링을 통해 찾아봅시다.
- Partition
- RDD
- DataFrame
- Dataset
- Catalyst Optimizer
- Encoder
- Serialization / Deserialization
- Spark UI
- Stage
다음 챕터부터는 이러한 Spark 의 다양한 API 및 컨셉등을 하나씩 익혀보겠습니다.
