Practical 시리즈는 AWS 환경 위에서 데이터 인프라를 구축하는데 참고할만한 내용들을 담고 있습니다. 이 글은 그 중 Practical Spark 의 한 챕터입니다. 이번 챕터에서는 Spark 의 컨셉에 대해 알아보며 Spark 내부 동작에 대해 이해해보겠습니다. 다루는 주제는 Transformation, Action, Shuffle 등입니다.

Practical 시리즈는 AWS 환경 위에서 데이터 인프라를 구축하는데 참고할만한 내용들을 담고 있습니다. 아래의 내용들을 주로 다룹니다.
- Practical Spark
- Practical Kafka
- Practical Kubernetes
- Practical AWS
이 블로그에 작성된 내용은 위 시리즈 중 Gitbook 으로 작성된 Practical Spark 를 옮긴 것입니다. 원본 Gitbook 와 실습에 사용하는 코드는 아래의 링크에서 보실 수 있습니다.
- (Spark Batch) https://1ambda.gitbook.io/practical-data-pipeline/02-processing/2.2-batch
- (Spark Stream) https://1ambda.gitbook.io/practical-data-pipeline/02-processing/2.4-stream
- (Code) https://github.com/1ambda/practical-data-pipeline-code
Spark Concept
지난 챕터에서는 Spark 의 기본적인 사용 방법에 대해 알아봤습니다. 이 챕터에서는 지난 챕터에서 사용했던 코드를 바탕으로 Spark 의 구성 요소에 대해 알아보겠습니다.
- Transformation
- Action
- Partition
- Shuffle
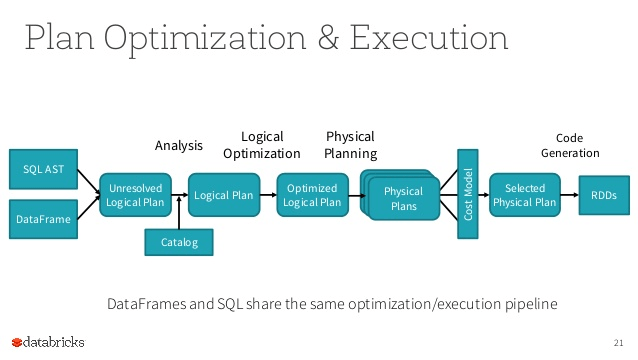
지난 챕터에서 DataFrame / SQL / Dataset API 를 이용할 경우 RDD 로 코드가 생성되어 실행된다는 이야기를 나누었습니다.
RDD 의 실제 동작은 크게 Transformation 과 Action 으로 구분할 수 있습니다.
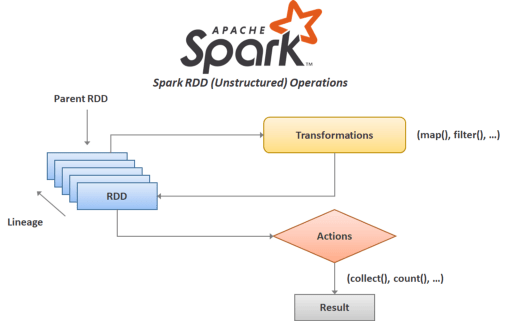
filter, map 등 다양한 Tranformation 을 적용하는 것을 반복하다가 최종적으로는 count() 와 같은 Action 을 호출해 결과를 만들어 냅니다. Spark UI 에서는 아래처럼 Transformation, Action 을 시각적으로 볼 수 있습니다.
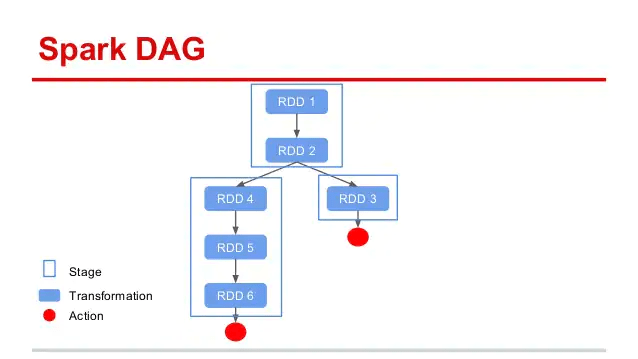
Spark 에서는 한 DataFrame 에 대해 여러번 Action 을 호출하거나, DataFrame 을 일부 변경해 (Transformation) 다시 Action 을 호출하는 것도 가능합니다. 이를 그림으로 표현해 보면 위와 같습니다.
Transformation
Transformation 에 대해 조금 더 자세히 알아봅시다. 실습을 위해 지난 시간에 사용했던 코드를 다시 가져와 보겠습니다.
| # Transformation 입니다. 아직 실행되지 않습니다. | |
| df = spark.read.load("./marketing_campaign.csv", | |
| format="csv", sep="\t", inferSchema="true", header="true") | |
| # Transformation 입니다. 아직 실행되지 않습니다. | |
| dfSelected = df.select( | |
| col("ID").alias("id"), | |
| col("Year_Birth").alias("year_birth"), | |
| col("Education").alias("education"), | |
| col("Kidhome").alias("count_kid"), | |
| col("Teenhome").alias("count_teen"), | |
| col("Dt_Customer").alias("date_customer"), | |
| col("Recency").alias("days_last_login") | |
| ) | |
| # Transformation 입니다. 아직 실행되지 않습니다. | |
| dfConverted = df.withColumn("date_joined", | |
| add_months(to_date(col("dt_customer"), "d-M-yyyy"), 72)) | |
| # Action 입니다. | |
| dfConverted.count() # 2240 을 출력 |
주석에 적혀있는 내용과 같이 dfConverted.count() 가 호출되기 전까지는 Spark 는 실제로 데이터를 읽거나 가공하는 연산을 수행하지 않습니다. 이렇게 사용자가 데이터를 미래에 ‘가공’ 하겠다는 요청만 해놓는 것을 Transformation 이라 부릅니다.
Transformation 요청을 Action 시점으로 미루는 것을 Spark 에서는 Lazy Evaluation 이라 부릅니다.그렇다면 Lazy Evaluation 의 장점은 무엇일까요? 두 가지 경우를 생각해봅시다.
map(withColumn),filter(where)과 같은 함수를 호출할 때 마다 즉시 연산이 된다면 큰 데이터를 다룰때 무슨일이 발생할까요?- map > filter 와 같이 최적화가 가능한 로직이 존재할 때 Lazy Evaluation 이 아니라 즉시 실행된다면 최적화가 가능할까요?
One advantage of this is that Spark can make many optimization decisions after it had a chance to look at the DAG in entirety. This would not be possible if it executed everything as soon as it got it.
Spark Transformation – Why is it lazy and what is the advantage?
Spark 는 어떤 Transformation 이 요청되었는지를 DataFrame 마다 기록하며 잘 모아 최종적으로 무엇이 필요한지를 판별함으로써 최적화를 수행할 수도 있습니다. withColumn 과 같은 Transformation 을 사용하면 현재 DataFrame 이 사용자가 요청한 명령을 “수행하겠다” 는 DataFrame 으로 변경됩니다.
다만 앞서 언급한 것처럼, 실제로 수행되지는 않고, “실행 계획” 이라 불리는 어떤 내용을 수행할지에 대한 내용만 새롭게 만들어지는 변경된 DataFrame 에 포함됩니다. explain() 함수를 통해 Spark DataFrame 의 실행 계획을 볼 수 있습니다.
| # dfSelected.explain("formatted") 의 실행 결과 | |
| (1) Scan csv | |
| Output [7]: [ID#16, Year_Birth#17, Education#18, Kidhome#21, Teenhome#22, Dt_Customer#23, Recency#24] | |
| Batched: false | |
| Location: InMemoryFileIndex [file:/home/jovyan/private-notebook/spark-tutorial/marketing_campaign.csv] | |
| ReadSchema: struct<ID:int,Year_Birth:int,Education:string,Kidhome:int,Teenhome:int,Dt_Customer:string,Recency:int> | |
| (2) Project [codegen id : 1] | |
| Output [7]: [ID#16 AS id#190, Year_Birth#17 AS year_birth#191, Education#18 AS education#192, Kidhome#21 AS count_kid#193, Teenhome#22 AS count_teen#194, Dt_Customer#23 AS date_customer#195, Recency#24 AS days_last_login#196] | |
| Input [7]: [ID#16, Year_Birth#17, Education#18, Kidhome#21, Teenhome#22, Dt_Customer#23, Recency#24] | |
| # dfConverted.explain("formatted") 의 실행 결과 | |
| (1) Scan csv | |
| Output [7]: [ID#16, Year_Birth#17, Education#18, Kidhome#21, Teenhome#22, Dt_Customer#23, Recency#24] | |
| Batched: false | |
| Location: InMemoryFileIndex [file:/home/jovyan/private-notebook/spark-tutorial/marketing_campaign.csv] | |
| ReadSchema: struct<ID:int,Year_Birth:int,Education:string,Kidhome:int,Teenhome:int,Dt_Customer:string,Recency:int> | |
| (2) Project [codegen id : 1] | |
| Output [8]: [ID#16 AS id#213, Year_Birth#17 AS year_birth#214, Education#18 AS education#215, Kidhome#21 AS count_kid#216, Teenhome#22 AS count_teen#217, Dt_Customer#23 AS date_customer#218, Recency#24 AS days_last_login#219, add_months(cast(gettimestamp(Dt_Customer#23, d-M-yyyy, Some(Asia/Seoul), false) as date), 72) AS date_joined#227] | |
| Input [7]: [ID#16, Year_Birth#17, Education#18, Kidhome#21, Teenhome#22, Dt_Customer#23, Recency#24 |
참고로 Spark 3 에서는 `explain()` 함수의 인자로 “simple”, “extended”, “codegen”, “cost”, “formatted” 등을 줄 수 있습니다.
explain() 함수를 이용해 나온 DataFrame 의 실행 계획을 볼 수 있습니다. dfConverted 의 경우에는 추가한 컬럼인 date_joined 에 대한 정보도 포함되어 있습니다.
| add_months(cast(gettimestamp(Dt_Customer#23, d-M-yyyy, Some(Asia/Seoul), false) as date), 72) AS date_joined#227 |
dfConverted 의 실행계획을 잘 살펴보면 dfSelected 에 date_joined 를 추가하는 Transformation 만 추가된 것임을 볼 수 있습니다. 즉, dfSelected 에 컬럼을 추가한다 해서 dfSelected 는 변경되지 않습니다. 각각의 DataFrame 은 Immutable (불변) 이며 Transformation API 호출시 새로운 DataFrame 이 기존 DataFrame 을 바탕으로 새롭게 생성됩니다.
따라서 사용자는 dfSelected 를 기반으로 dfConverted 를 만들었지만 dfSelected 는 변화 없이, 기존의 결과 그대로 사용할 수 있습니다. dfSelected.rdd.id 와 dfConverted.rdd.id 의 값의 차이에서도 이를 확인할 수 있습니다.
RDD (Resilient Distributed Dataset) 는 DataFrame 과 유사하게 Spark 에서 분산 데이터를 다룰 수 있도록 제공하는 Low-level API 입니다. 다만 DataFrame 이 컬럼 기반으로 Table 형태로 데이터를 쉽게 다룰 수 있도록 추상화 되었다면, RDD 는 “이름” 을 가진 컬럼이 아니라 0, 1, 2 번째 컬럼 등과 같이 레코드 기반으로 데이터를 가공할 수 있는 저수준 API 를 제공합니다. DataFrame 을 일종의 RDD Wrapper 라고 당장은 이해해도 괜찮습니다.
RDD, DataFrame, DataSet 에 대한 시각적인 비교는 다음 문서를 참조하실 수 있습니다.
RDD 는 DataFrame.rdd 를 통해 접근이 가능하며, 아래와 같이 서로 다른 DataFrame 은 서로 다른 RDD.id 를 가지고 있습니다.
| # `dfSelected.rdd.id` 출력 결과 | |
| <bound method RDD.id of MapPartitionsRDD[15] at javaToPython at NativeMethodAccessorImpl.java:0> | |
| # `dfConverted.rdd.id` 출력 결과 | |
| <bound method RDD.id of MapPartitionsRDD[42] at javaToPython at NativeMethodAccessorImpl.java:0> |
explain("extended") 을 호출하면 다음과 같이 추가적인 정보를 몇 가지 더 볼 수 있습니다.
| # dfConvertedxplain("extended") | |
| == Parsed Logical Plan == | |
| 'Project [id#236, year_birth#237, education#238, count_kid#239, count_teen#240, date_customer#241, days_last_login#242, add_months(to_date('date_customer, Some(d-M-yyyy)), 72) AS date_joined#257] | |
| +- Project [ID#16 AS id#236, Year_Birth#17 AS year_birth#237, Education#18 AS education#238, Kidhome#21 AS count_kid#239, Teenhome#22 AS count_teen#240, Dt_Customer#23 AS date_customer#241, Recency#24 AS days_last_login#242] | |
| +- Relation[ID#16,Year_Birth#17,Education#18,Marital_Status#19,Income#20,Kidhome#21,Teenhome#22,Dt_Customer#23,Recency#24,MntWines#25,MntFruits#26,MntMeatProducts#27,MntFishProducts#28,MntSweetProducts#29,MntGoldProds#30,NumDealsPurchases#31,NumWebPurchases#32,NumCatalogPurchases#33,NumStorePurchases#34,NumWebVisitsMonth#35,AcceptedCmp3#36,AcceptedCmp4#37,AcceptedCmp5#38,AcceptedCmp1#39,... 5 more fields] csv | |
| == Analyzed Logical Plan == | |
| id: int, year_birth: int, education: string, count_kid: int, count_teen: int, date_customer: string, days_last_login: int, date_joined: date | |
| Project [id#236, year_birth#237, education#238, count_kid#239, count_teen#240, date_customer#241, days_last_login#242, add_months(to_date('date_customer, Some(d-M-yyyy)), 72) AS date_joined#257] | |
| +- Project [ID#16 AS id#236, Year_Birth#17 AS year_birth#237, Education#18 AS education#238, Kidhome#21 AS count_kid#239, Teenhome#22 AS count_teen#240, Dt_Customer#23 AS date_customer#241, Recency#24 AS days_last_login#242] | |
| +- Relation[ID#16,Year_Birth#17,Education#18,Marital_Status#19,Income#20,Kidhome#21,Teenhome#22,Dt_Customer#23,Recency#24,MntWines#25,MntFruits#26,MntMeatProducts#27,MntFishProducts#28,MntSweetProducts#29,MntGoldProds#30,NumDealsPurchases#31,NumWebPurchases#32,NumCatalogPurchases#33,NumStorePurchases#34,NumWebVisitsMonth#35,AcceptedCmp3#36,AcceptedCmp4#37,AcceptedCmp5#38,AcceptedCmp1#39,... 5 more fields] csv | |
| == Optimized Logical Plan == | |
| Project [ID#16 AS id#236, Year_Birth#17 AS year_birth#237, Education#18 AS education#238, Kidhome#21 AS count_kid#239, Teenhome#22 AS count_teen#240, Dt_Customer#23 AS date_customer#241, Recency#24 AS days_last_login#242, add_months(cast(gettimestamp(Dt_Customer#23, d-M-yyyy, Some(Asia/Seoul), false) as date), 72) AS date_joined#257] | |
| +- Relation[ID#16,Year_Birth#17,Education#18,Marital_Status#19,Income#20,Kidhome#21,Teenhome#22,Dt_Customer#23,Recency#24,MntWines#25,MntFruits#26,MntMeatProducts#27,MntFishProducts#28,MntSweetProducts#29,MntGoldProds#30,NumDealsPurchases#31,NumWebPurchases#32,NumCatalogPurchases#33,NumStorePurchases#34,NumWebVisitsMonth#35,AcceptedCmp3#36,AcceptedCmp4#37,AcceptedCmp5#38,AcceptedCmp1#39,... 5 more fields] csv | |
| == Physical Plan == | |
| *(1) Project [ID#16 AS id#236, Year_Birth#17 AS year_birth#237, Education#18 AS education#238, Kidhome#21 AS count_kid#239, Teenhome#22 AS count_teen#240, Dt_Customer#23 AS date_customer#241, Recency#24 AS days_last_login#242, add_months(cast(gettimestamp(Dt_Customer#23, d-M-yyyy, Some(Asia/Seoul), false) as date), 72) AS date_joined#257] | |
| +- FileScan csv [ID#16,Year_Birth#17,Education#18,Kidhome#21,Teenhome#22,Dt_Customer#23,Recency#24] Batched: false, DataFilters: [], Format: CSV, Location: InMemoryFileIndex[file:/home/jovyan/private-notebook/spark-tutorial/marketing_campaign.csv], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<ID:int,Year_Birth:int,Education:string,Kidhome:int,Teenhome:int,Dt_Customer:string,Recency... |
Parsed Logical Plan, Analyzed Logical Plan, Optimized Logical Plan, Physical Plan 이란 이름에서 유추할 수 있듯이, Spark 는 실행 계획을 생성 하고 그것을 기반으로 분석하고, 최적화 한 뒤 데이터를 읽거나 가공하는 등 물리적으로 실행합니다.
조금 더 복잡한 실행 계획을 위해 다음 코드를 실행해 보겠습니다.
| # dfConverted.select("education").limit(5).explain("extended") | |
| == Analyzed Logical Plan == | |
| education: string | |
| GlobalLimit 5 | |
| +- LocalLimit 5 | |
| +- Project [education#238] | |
| +- Project [id#236, year_birth#237, education#238, count_kid#239, count_teen#240, date_customer#241, days_last_login#242, add_months(to_date('date_customer, Some(d-M-yyyy)), 72) AS date_joined#257] | |
| +- Project [ID#16 AS id#236, Year_Birth#17 AS year_birth#237, Education#18 AS education#238, Kidhome#21 AS count_kid#239, Teenhome#22 AS count_teen#240, Dt_Customer#23 AS date_customer#241, Recency#24 AS days_last_login#242] | |
| +- Relation[ID#16,Year_Birth#17,Education#18,Marital_Status#19,Income#20,Kidhome#21,Teenhome#22,Dt_Customer#23,Recency#24,MntWines#25,MntFruits#26,MntMeatProducts#27,MntFishProducts#28,MntSweetProducts#29,MntGoldProds#30,NumDealsPurchases#31,NumWebPurchases#32,NumCatalogPurchases#33,NumStorePurchases#34,NumWebVisitsMonth#35,AcceptedCmp3#36,AcceptedCmp4#37,AcceptedCmp5#38,AcceptedCmp1#39,... 5 more fields] csv | |
| == Optimized Logical Plan == | |
| GlobalLimit 5 | |
| +- LocalLimit 5 | |
| +- Project [Education#18 AS education#238] | |
| +- Relation[ID#16,Year_Birth#17,Education#18,Marital_Status#19,Income#20,Kidhome#21,Teenhome#22,Dt_Customer#23,Recency#24,MntWines#25,MntFruits#26,MntMeatProducts#27,MntFishProducts#28,MntSweetProducts#29,MntGoldProds#30,NumDealsPurchases#31,NumWebPurchases#32,NumCatalogPurchases#33,NumStorePurchases#34,NumWebVisitsMonth#35,AcceptedCmp3#36,AcceptedCmp4#37,AcceptedCmp5#38,AcceptedCmp1#39,... 5 more fields] csv |
Analyzed Logical Plan 과 Optimized Logical Plan 이 조금 다른것을 볼 수 있습니다. dfSelected 에서 한번 select() 를 여러 컬럼에 대해 수행했으나 최적화 시점에 판단해보니 그럴 필요 없이 최종적으로는 education 컬럼만 Projection 해서 쓸 수 있기 때문입니다.
Spark 는 explain() 으로 출력한 결과에 가공에 대한 이야기 이외에도, 데이터를 가져오는 저장소에 대해 정보를 표시할 수 있습니다.
예를 들어, 데이터를 필터링 하고자 하는 경우에 (SQL 의 WHERE 구문 혹은 filter 함수) Spark 의 메모리로 일단 전부 가져와 그 후에 필터링 하는것 보다는 데이터를 읽는 시점에 저장소 (또는 Parquet 와 같은 일부 파일 포맷) 단위에서 필터링이 가능하다면 더 적은양의 데이터만 읽어오면 되므로 네트워크 비용 절감 등 성능상의 이점이 있습니다. 이를 Predicate Pushdown 이라 부르는데, 이런 정보들 또한 explain() 을 통해 보여지는 실행 계획에 포함될 수 있습니다.

Predicate Push Down 을 통해 Spark 는 데이터 전체를 가져온 '후' 필터링하는 것이 아니라 저장소에서 데이터를 필터링 '된' 결과물만 가져와 네트워크 및 가공 비용을 줄일 수 있습니다.
Optimization
Action 으로 넘어가기 전에, 위에서 언급한 Logical Plan 과 Physical Plan 이 만들어지는 과정에 대해 조금 더 논의해보겠습니다.
지난 챕터 Spark Concept 마지막 부분에서 잠깐 언급했듯이 Spark 는 사용자의 SQL / DataFrame API 를 Catalyst Optimizer 를 통해 최적화하고 최종적으로는 RDD 를 위한 코드를 생성합니다.
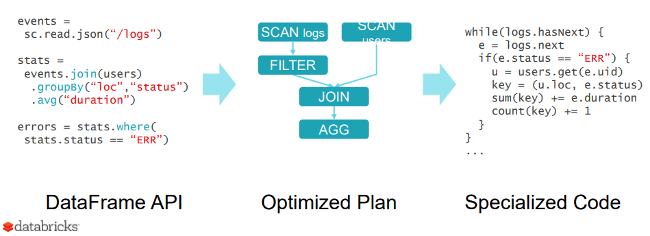
이 과정은 일반적으로 다음과 같이 구분지을 수 있습니다.
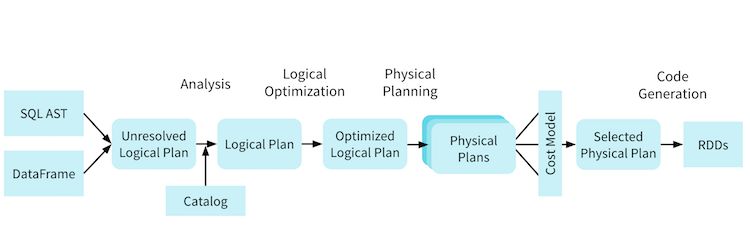
Logical Plan 은 DataFrame 또는 SQL 을 AST 형태로 변환합니다. 이 과정에서 Catalog 를 참조해 컬럼이 없는지 등을 판별하고, Cache Manager 를 참조해 캐싱된 데이터를 사용할 수 있는지 등을 판별합니다.
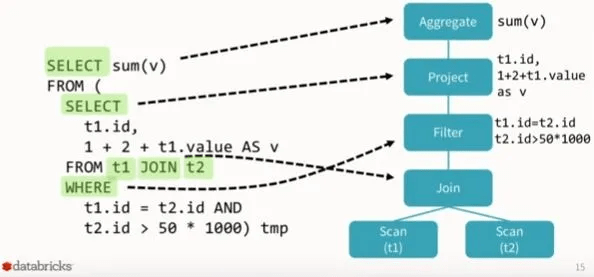
Logical Plan 이 최적화 단계를 거쳐 Physical Plan 이 생성되는데, Physical Plan 은 구체적으로 어떤 알고리즘을 수행해야 하는지 등의 정보를 담고 있습니다.
예를 들어 Logical Plan 에서는 Join 이라고 표시 되었지만 Physical Plan 에서는 Sort-merge Join 을 사용한다는 정보가 표시됩니다.

이후 Code Model 을 통해 어떤 Physical Plan 이 가장 적합한지 선택하고 코드를 생성합니다. Spark 3 에서는 explain 시에 cost 및 codegen 파라미터를 사용해 각각의 정보를 살펴볼 수 있습니다.
| df.explain("cost") | |
| df.explain("codegen") |

Action
Transformation 이 누적되면서 데이터를 어떻게 가공할지가 DataFrame 의 실행 계획으로 기록되게 되며, 사용자는 최종 시점에 여태까지 작업했던 데이터를 보거나 / 다른 곳으로 저장하는 행동을 취하게 되며, Spark 에서는 이것을 Action 이라 부릅니다. Action 을 실행하는 순간 이제까지 명령을 내렸던 Transformation 이 적용됩니다.
다음은 Action 과 Transformation 을 확인할 수 있는 목록입니다. RDD 는 유사한 DataFrame 과 동일한 기능을 하는 함수를 다른 이름으로 제공하기 때문에 RDD 의 Action, Transformation 을 정리한 문서를 통해서도 유추해볼 수 있습니다.
Dataset 은 이후 챕터에서 설명하겠지만, DataFrame 의 타입화된 버전이라고 보시면 됩니다. Dataset[Row] 가 DataFrame 이 됩니다. Row 대신, 사용자는 Dataset[MyCustomer] 와 같이 원하는 타입 (클래스) 를 넣어 컬럼이름을 문자열로 col("education") 처럼 사용하는 대신, ds.map(x => x.education) 처럼 클래스 형식으로 사용할 수 있습니다. 따라서 Dataset 의 Transformation, Action 을 정리한 문서를 통해서도 어떤 함수가 DataFrame 의 Transformation 인지 혹은 Action 인지 확인할 수 있습니다.
- Spark Docs – RDD Transformation
- Spark Docs – RDD Action
- Spark Internal – Dataset Basic Actions
- Spark Internal -Dataset Actions
- Spark Internal – Typed Transformation
- Spark Internal – Untyped Transformation
예를 들어, 지금까지 사용했던
withColumn,select,where등은 Transformation 입니다.- 반면
count,describe,show (toPandas)는 모두 Action 입니다. collect,write,foreachPartition등은 아직 다루지 않았지만 아주 많이 활용되는 Action 입니다.
Partition
RDB (MySQL 등) 의 Partition 과 Hive 의 Partition 과 Kafka 의 Partition 과 Spark 의 Partition 이 의미하는 바가 구체적으로는 다르지만, 기본적인 개념은 비슷합니다.
데이터 시스템에서 Partition 이란, 전체에서 나누어진 “부분” 을 말합니다.

우리가 지금까지 실습에 사용했던 데이터는 2240 건의 작은 CSV 단일 파일이어서 문제가 없지만, 데이터가 2240억 건일 경우 단일 머신에서 처리하기 어렵습니다. 따라서 사용자는 DataFrame 이라는 추상화된 API 를 통해 데이터를 ‘하나’ 처럼 다루지만, Spark 는 데이터를 분할해 ‘Partition’ 단위로 데이터를 처리합니다.
다음 챕터인 Spark Architecture 에서도 설명하겠지만, Spark 가 여러 머신에서 분산처리를 시도할 경우, Executor 라는 직원을 여러명 만들게 되고 Driver 라 불리는 사장님이 내린 명령을 수행하게 됩니다.

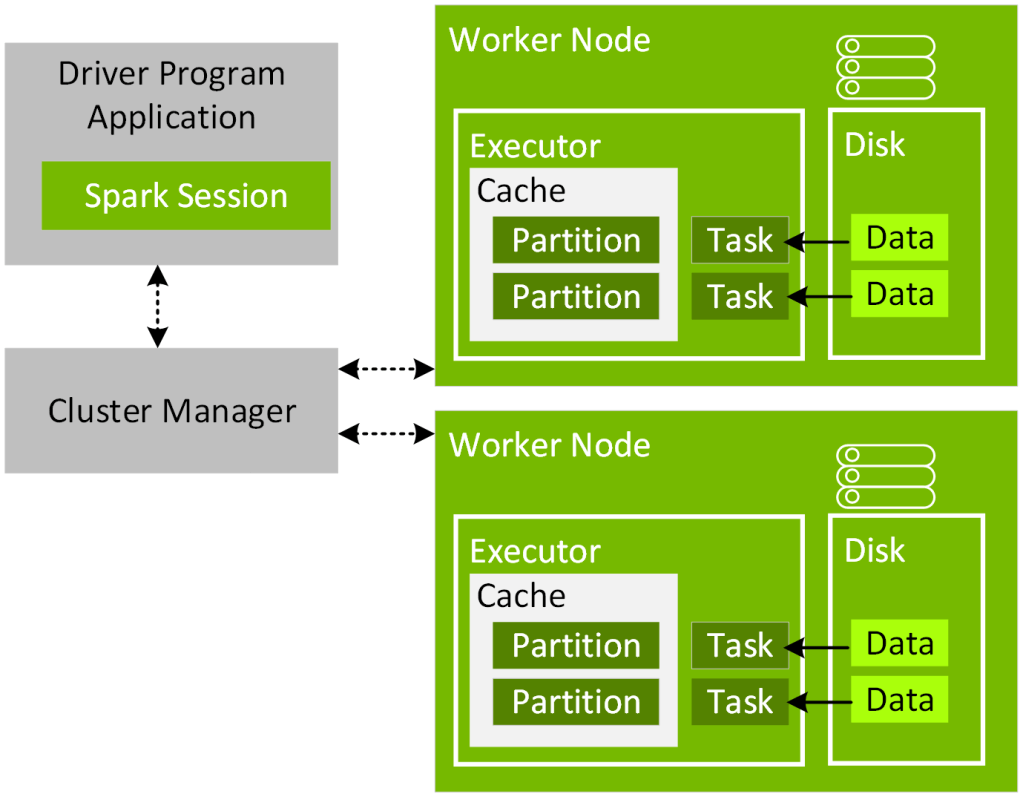
Spark 에서 데이터를 잘게 쪼개, Partition 이 많다면 Executor (직원) 가 많을 경우 동시에 여러 Executor 에서 처리가 될 수 있으므로 빠를터이고 반면 Executor 숫자가 적다면 Partition 을 아무리 잘게 쪼개도 병렬 처리가 불가능하므로 급격한 성능 향상을 보기가 어렵습니다.
Partition 이 높다고 해서 좋을까요? 아래의 질문들을 고민하며 적절한 Partition 숫자는 어떻게 구할 수 있을지 생각해 봅시다.
- Partition 이 너무 많으면 어떤 문제가 생길까요?
- Partition 이 너무 적다면 반대로 어떤 문제가 생길 수 있을까요?
Executor 에서 할당받아 진행되는 작업은 Job, Stage, Task 와 같은 단위로 조금 더 자세히 나눠볼 수 있는데, 이 부분은 본 챕터의 뒷 부분에서 추가로 다루도록 하겠습니다.
Spark 에서 Partition 를 조정하는 여러가지 설정들이 있습니다. 또한 최초 시작 이후에도 DataFrame 에 원하는 시점에 적용할 수 있는 함수들도 존재합니다.
Spark 에서는 RDD, DataFrame (SQL), Dataset 과 같이 다양한 API 를 제공하고 동적으로 초기 시점 파티션 숫자를 결정하기 때문에 이러한 설정들은 복합적으로 작용하게 됩니다. 주요 파라미터 를 나열해 보면
- (설정) spark.default.parallelism 는 주로 spark-default.conf 에 세팅되어 초기값으로 사용됩니다. 다른 설정값들이 이 값을 참조할 수 있습니다.
- (설정) spark.sql.shuffle.partitions 는 DataFrame.repartition() 에서 지정된 숫자가 없을 경우나 Join 이나 Aggregation 등 Shuffle 이 발생할 경우 사용됩니다.
- (설정) spark.sql.files.maxPartitionBytes, spark.sql.files.minPartitionNum 는 DataFrame 또는 Dataset API 로 Parquet, ORC, JSON, CSV 와 같은 파일을 읽을 경우, 파일 사이즈를 기반으로 파티션 숫자를 동적으로 계산하기 위해 사용됩니다.
이제 코드를 통해 DataFrame 의 API 를 이용해 Partition 값을 확인하고, 수정해보겠습니다. Spark Context 에서 현재 설정값을 확인해보려면 아래의 코드를 실행할 수 있습니다.
| spark.sparkContext._conf.get('spark.default.parallelism') | |
| 200 # 출력 결과, Spark 설정에 따라 200 이 아닌 값일 수 있습니다. |
그리고 Transformation 을 지정했던 DataFrame 마다 파티션 값을 얻기 위해 df.rdd.getNumPartitions() 를 사용해 보겠습니다.
| print(f"Partition Count of Dataframe df:\t\t{df.rdd.getNumPartitions()}") | |
| print(f"Partition Count of Dataframe dfSelected:\t{dfSelected.rdd.getNumPartitions()}") | |
| print(f"Partition Count of Dataframe dfConverted:\t{dfConverted.rdd.getNumPartitions()}") | |
| # 출력 결과 | |
| Partition Count of Dataframe df: 1 | |
| Partition Count of Dataframe dfSelected: 1 | |
| Partition Count of Dataframe dfConverted: 1 |
데이터 사이즈가 2240 개 Row 로 매우 작아, Spark 가 spark.default.parallelism 이나 spark.sql.files.minPartitionNum 의 기본값이 아니라 동적으로 계산된 1 임을 알 수 있습니다. 현재 데이터가 작긴 하지만, 크다고 가정하고 Partition 이 1 인 상태에서는 데이터를 분산해 처리가 어려우므로 Partition 숫자를 늘려 보겠습니다.1
| # repartition 함수를 통해 파티션 숫자를 1 -> 5 로 늘립니다. | |
| dfPartitioned = dfConverted.repartition(5) | |
| print(f"Partition Count of Dataframe dfPartitioned:\t{dfPartitioned.rdd.getNumPartitions()}") | |
| Partition Count of Dataframe dfPartitioned: 5 |
왜 Partition 숫자를 최초 시점 이후에도 조절하는 함수가 필요할까요? 데이터를 가져올때 적절히 분할해서 가져오면 그 이후에는 별 다른 조정이 필요없지 않을까요? 다음 두 가지 경우를 고민해 봅시다.
- 1.Partition 이 늘어날 수 있는 경우는 언제일까요?
- 2.Partition 이 줄어들 수 있는 경우는 언제일까요?
DataFrame.repartition() 함수 이외에도 DataFrame.coalesce() 함수가 존재합니다. DataFrame, Dataset 의 coalesce 는 Partition 을 지정한 숫자로 늘리는 것이 아니라 줄이는 것만 가능합니다. (DataFrame 이 아닌 RDD.coalesce() 는 shuffle = true 시 늘리는것도 가능합니다)
이렇게 repatition() 과 coalesce() 두개의 차이점은
repatition()은 Partition 을 늘리고 줄일 수 있습니다. 다만 이 경우 전체 데이터, 즉 전체 Partition 대해 균등하게 배분하기 위해 재배치가 (relocation) 이 발생합니다. 이 과정에서 머신간 데이터의 이동이 발생하며 뒤에서 논의하겠지만 비용이 매우 비싼 네트워크 연산입니다.- DataFrame 의
coalesce()는 Partition 을 현재 숫자 이하로만 줄일 수 있습니다. 따라서 현재 DataFrame 의 Partition 이 100 일 경우, 100 이하로만 세팅할 수 있습니다.repartition()과 달리 줄이는 과정에서 만약 옮길 필요가 없는 데이터가 있다면 옮기지 않습니다. 즉 비싼 네트워크 연산을 피할 수 있습니다.
일반적으로 repartition() 을 호출하는 경우는 크게 2가지입니다.
- DataFrame 을 가공하는 과정에서 데이터의 불균형 (Skew) 이 발생할 수 있습니다.
education = NONE만 필터링 했더니, 특정 Partition 데이터만 많이 남아있다면 분산 처리를 한다 해도 특정 Partition 데이터의 양이 많아 상대적으로 늦게 끝날 수 있습니다. - DataFrame 을 가공하는 과정에서 충분한 필터링으로 인해 데이터의 양이 줄었을 경우 Partition 을 줄일 수 있습니다. 반대로, DataFrame 을 가공하는 과정에서 Join, Union 등 을 통해 추가적으로 데이터가 늘었을 경우 Partition 을 늘릴 수 있습니다.
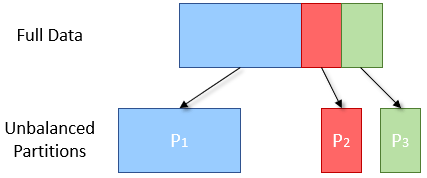
작은 규모의 데이터셋이나 분산 처리가 크게 필요하지 않은 경우, Partition 를 줄여서 사용할 수도 있습니다. 그러나 이 경우 하나의 Partition 이 가진 데이터 사이즈가 커지므로 커진 Partition 을 처리하는 머신의 메모리나 디스크 사용량으로 인해 문제가 발생할 수 있습니다.
왜 데이터가 네트워크로 이동하는 연산이 비쌀까요? AWS 문서에서 제공하는 m5.4xlarge 머신 유형의 경우 vCPU 16개 메모리 64 GiB, 그리고 네트워크 대역폭은 ‘최대’ 10 Gbps 입니다. 10 Gbps 를 전환하면 1.25 GB/s 정도인데, 만약 수백기가의 데이터를 가공한다면 네트워크 이동엔 시간이 얼마나 걸릴까요?
네트워크로 데이터가 이동한 후에, Spark 가 다시 메모리로 해당 데이터를 올릴려면 어떤 과정을 거칠지도 생각해 봅시다.
위의 예제에서는 Partition 을 분배할 때, Dataframe.repartition(5) 와 같이 데이터의 속성 (컬럼) 과 무관하게 사이즈와 Row 수 기준으로 균등하게 나눠 보았습니다.
그러나 실제 데이터 가공시에는 사용자 ID 기준, 상품 ID 기준 등 특정 데이터를 기준으로 Group By, Window Function 등을 수행하는 경우가 많으며, 이로인해 잦은 데이터의 이동이 발생할 수 있습니다. 따라서 Column 기준으로 Dataframe.repartition() 을 작업 해놓고, 이후 Transformation 에서 해당 Column 을 기준으로 연산을 수행한다면 추가적인 데이터의 이동을 줄일 수 있습니다.
| dfConverted.repartition(col("id")) |
Shuffle
Shuffle 은 특정 연산을 수행하기 위해 여러 Partition 내의 데이터가 그룹화되어 다른 Partition 들로 이동하는 것을 말합니다.
이 과정에서 어떤 데이터를 이동해야 할지 모르므로 전체 데이터에 대한 탐색이 필요할 수 있습니다. 또한 데이터를 그룹화하기 위해 특정 파티션을 담당하는 머신으로의 데이터 전송이 발생할 수 있으므로 Disk IO, 데이터 직렬화 / 네트워크 IO 등 많은 비용이 발생하게 됩니다.
Certain shuffle operations can consume significant amounts of heap memory since they employ in-memory data structures to organize records before or after transferring them. Specifically,
reduceByKeyandaggregateByKeycreate these structures on the map side, and'ByKeyoperations generate these on the reduce side. When data does not fit in memory Spark will spill these tables to disk, incurring the additional overhead of disk I/O and increased garbage collection.Shuffle also generates a large number of intermediate files on disk.
As of Spark 1.3, these files are preserved until the corresponding RDDs are no longer used and are garbage collected. This is done so the shuffle files don’t need to be re-created if the lineage is re-computed.
Performance Impact of Shuffle
Spark 에서는 일부 연산의 경우 메모리를 매우 많이 쓰기도 하며, 메모리에 다 들어가지 못하는 수백 GiB 의 데이터를 Disk 에 중간 결과로 저장하기도 합니다. 이 결과는 경우에 따라 Spark 작업이 종료되기 전까지 정리되지 않아 많은 양의 Disk 를 소모할 수도 있습니다.
즉 Shuffle 로 인해 Memory / Disk / Network 등 많은 자원이 소모됩니다. 그러므로 잘 구현한 Spark 작업은 Shuffle 을 적게, 필요한 만큼만 수행해 자원을 덜 소모하고 실행 시간도 짧아질 수 있습니다.
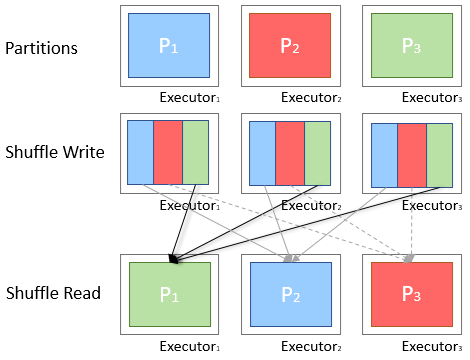
어떤 연산을 위해 Shuffle 이 필요할지 한번 생각해 봅시다. 데이터 집계를 위해서 데이터를 모아야 한다면 언제 그럴 필요가 있을까요? 다음의 연산들은 어떨지 이야기 해 봅시다.
- Count 집계
- Unique Count 집계 (Distinct)
- Sort
- Join
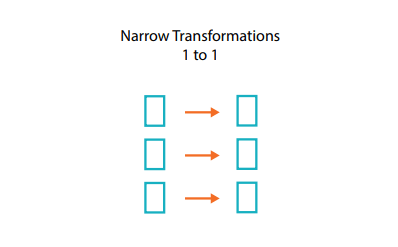
Shuffle 관련하여 추가적으로 알아야 할 Transformation 의 구분이 있습니다.
- Narrow Transformation
- Wide Transformation
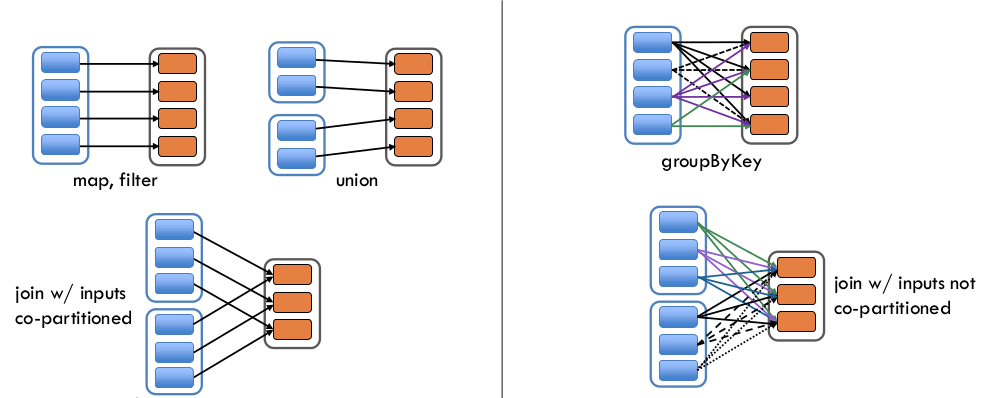
Narrow Transformation 은 데이터의 이동이 필요 없는, 즉 Shuffle 이 발생하지 않는 Transformation 을 말합니다. 함수로 치자면, map, filter, union 등이 여기에 해당합니다.
반대로 Wide Transformation 은 SQL 의 group by distinct count 처럼 특정 키를 기준으로 데이터를 모은 후 집계하는 경우를 말합니다. RDD API 로는 groupByKey 등이 해당합니다.이 문서에서는 RDD API 를 구체적으로 설명하지 않았지만, Shuffle 을 발생시킨다 하더라도 Transformation 에 따라 퍼포먼스가 더 나은 경우가 있습니다.
예를 들어 Group By 후 Count 를 집계할 때
- groupByKey 를 사용하는 경우와
- reduceByKey 를 사용하는 경우가 성능이 크게 다를 수 있습니다.
이는 데이터를 옮기기 전 현재 Partition 에서 미리 Group By 집계 후 결과만 Shuffle 하는 reduceByKey 는, Shuffle 시 옮길 데이터 양이 적기 때문입니다. 이런 방법을 Map-side aggregation 이라 부르기도 합니다.
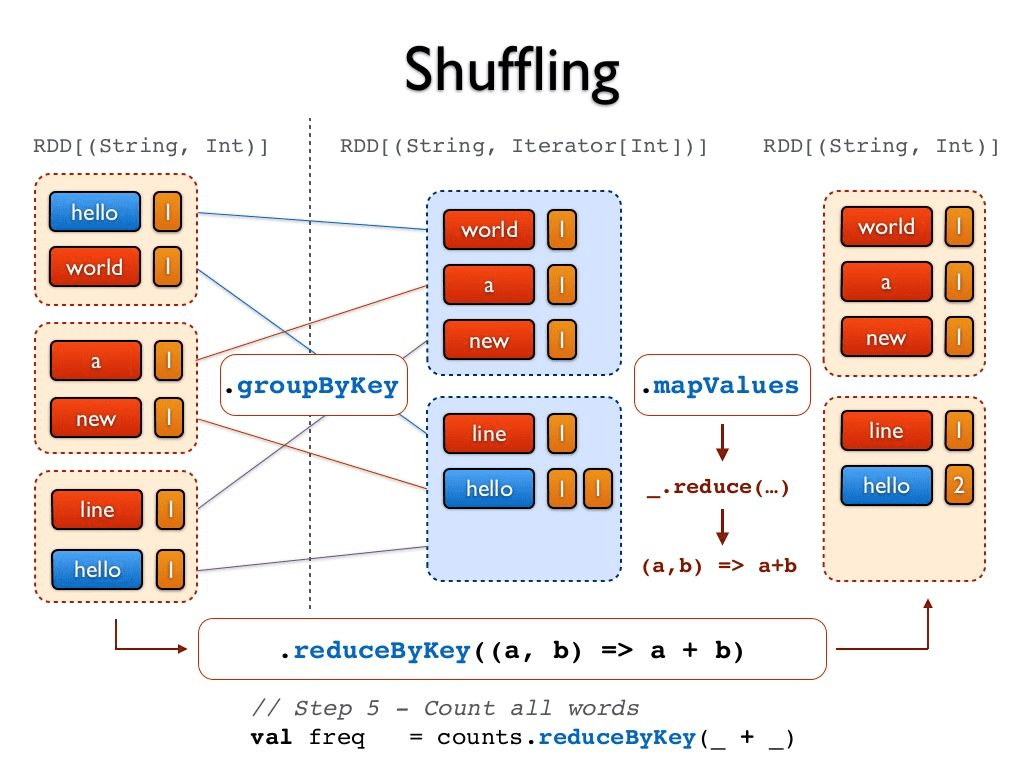
DataFrame API 를 쓰는 경우에는 이러한 함수를 직접 다루지 않고 작성한 SELECT distinct count 같은 SQL 구문이나 groupBy 같은 API 가 groupByKey 와 같은 함수로 컴파일 됩니다. (RDD 로 변환)
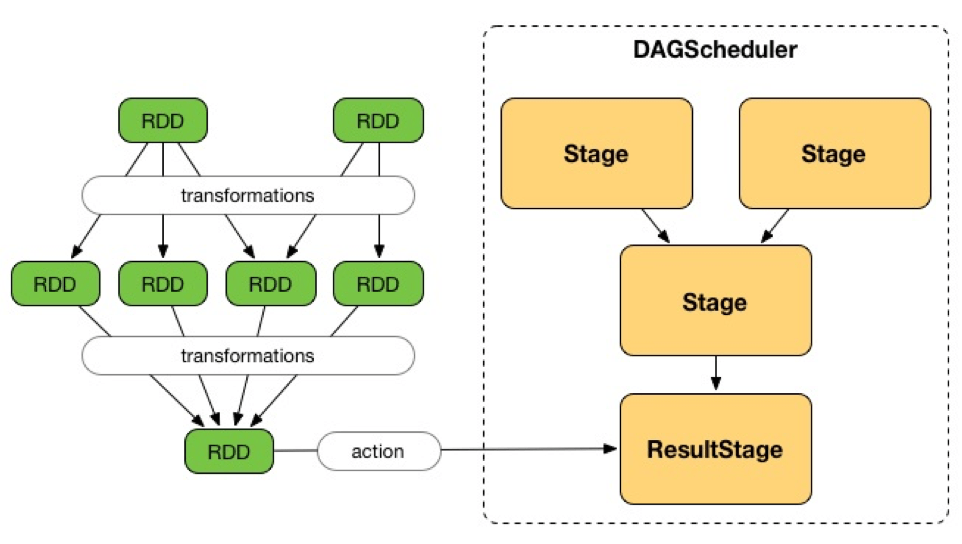
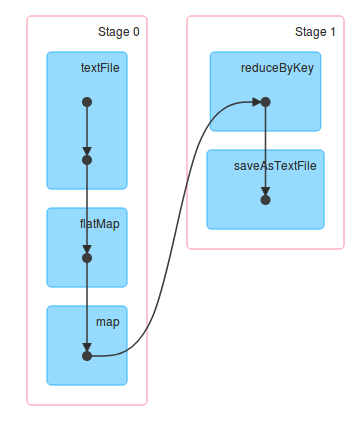
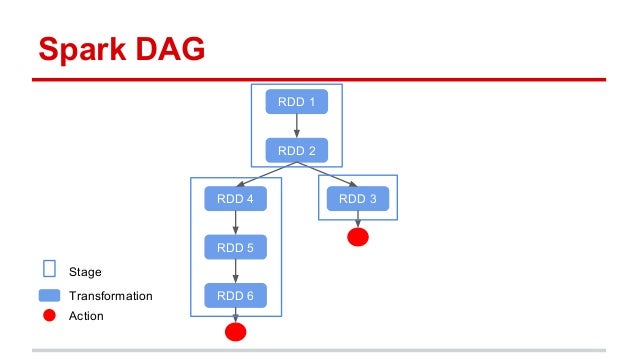
Spark 에서 RDD Operation 은 물리적 실행 단위인 Task 로 변환되는데, Task 의 묶음이 Stage 입니다. 그리고 Stage 를 구분하는 기준이 바로 Wide Transformation 인 Shuffle 입니다.

한 Stage 내에서 Task 는 병렬로 실행될 수 있습니다. 그러나 Stage 는 Shuffle 로 구분되고, 이 Shuffle 은 데이터 이동을 전제로 하기 때문에 한 Stage 가 시작되기 위해서는 원하는 데이터가 전부 준비가 되어야 합니다. 다시 말해서, 이전 Stage 가 종료가 되어야 합니다.
아래 그림에서 Join 의 경우를 보면 쉽게 이해할 수 있습니다

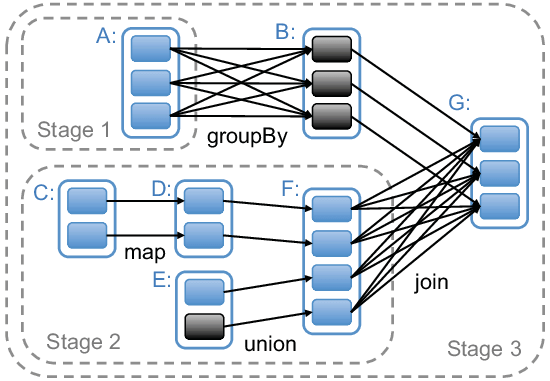
Shuffle 이 발생하는 과정을 하나의 JVM 내에서 살펴보면 다음과 같습니다. 수행하는 연산의 종류에 따라 단일 JVM 내에서의 복잡도가 달라집니다.


Task, Stage and Job
Spark Job / Batch (배치) Job 이란 용어를 많이 사용하곤 합니다. 일반적으로 Job 이란 1회성으로 실행되는 작업을 일컫습니다. 따라서 Spark Batch Job 은 Airflow, Digdag 등 스케쥴러에서 주기적으로 실행되어 할일을 마친 뒤 종료되는 Spark Application 을 의미합니다.
일반적인 의미 이외에도, Job 이라는 용어는 Spark 내부적으로도 사용됩니다.
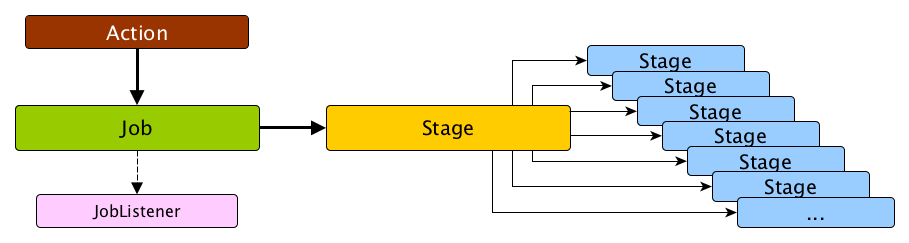
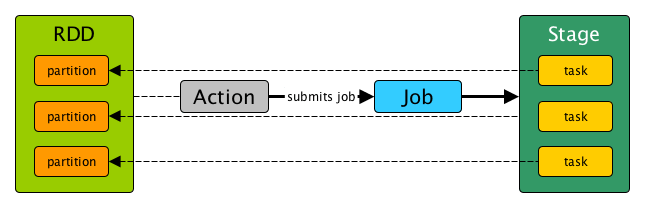
Spark 가 실행되고 Action 을 호출하면 실행 계획이 생성되고, Executor 들에 Task 가 분배되어 분산처리를 시작한다고 소개한적이 있었는데, 조금 더 나눌 수 있습니다.
- Action 이 호출되면 실행 계획이 생성됩니다
- Driver 내의 Dag Scheduler 는 사용자가 DataFrame (RDD) 에 호출한 Transformation, Action 을 바탕으로 만들어진 Logical Plan 을 Physical Plan, 즉 Stage 로 변경합니다.
- Driver 내의 Task Scheduler 는 이렇게 만들어진 Stage 들 을 Cluster 로 전달합니다.
만약 하나의 Spark Application 에서 다수의 Action 을 트리거 한다면, 그에 맞추어 이 프로세스가 여러번 반복될 수 있습니다.
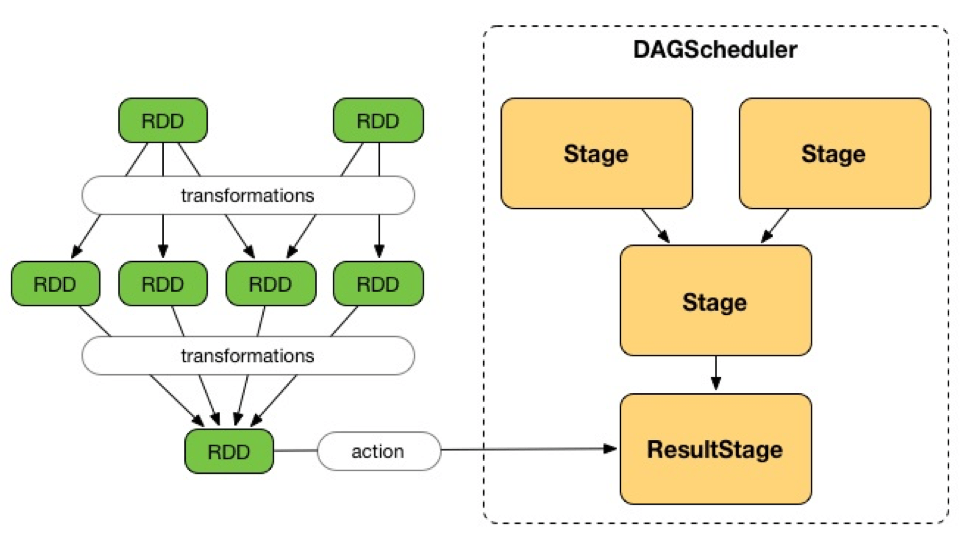
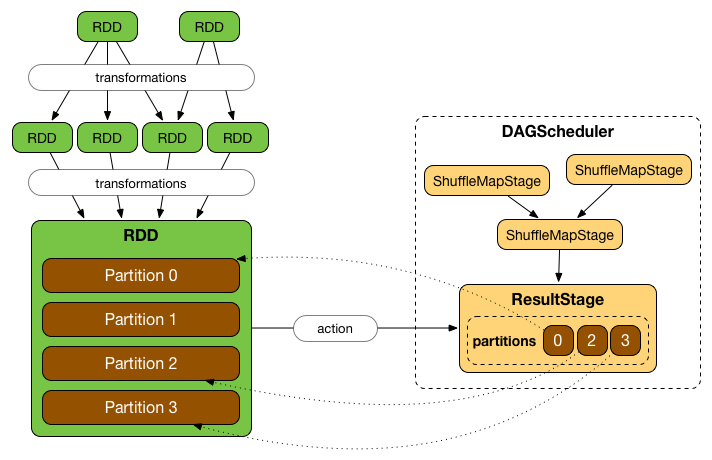
Stage 도 2가지로 구분지을 수 있습니다.
- ShuffleMapStage 는 중간 Stage 입니다.
- ResultStage 는 최종 Stage 입니다.
각각의 Stage 는 Narrow Transformation 들을 담고 있으며, Shuffle 을 기준으로 Stage 가 나누어집니다.
- 예를 들어,
map(),filter()같은 단순 연산은 함께 묶여 같은 Stage 내에 Task 들이 될 수 있지만, Shuffle 이 발생한다면 Stage 가 분리되고 하위 Stage 가 부모 Stage 의 작업이 끝나기까지 대기해야 할 수 있습니다.
어느 시점에서는 RDD 내 Partition 들은 하나의 Task 가 처리하도록 변환이 됩니다. 그러나 요청된 Action 이 전체 데이터를 필요치 않을 수 있으므로 (first(), limit() 등) 모든 Partition 이 사용되지 않을 수 있습니다.
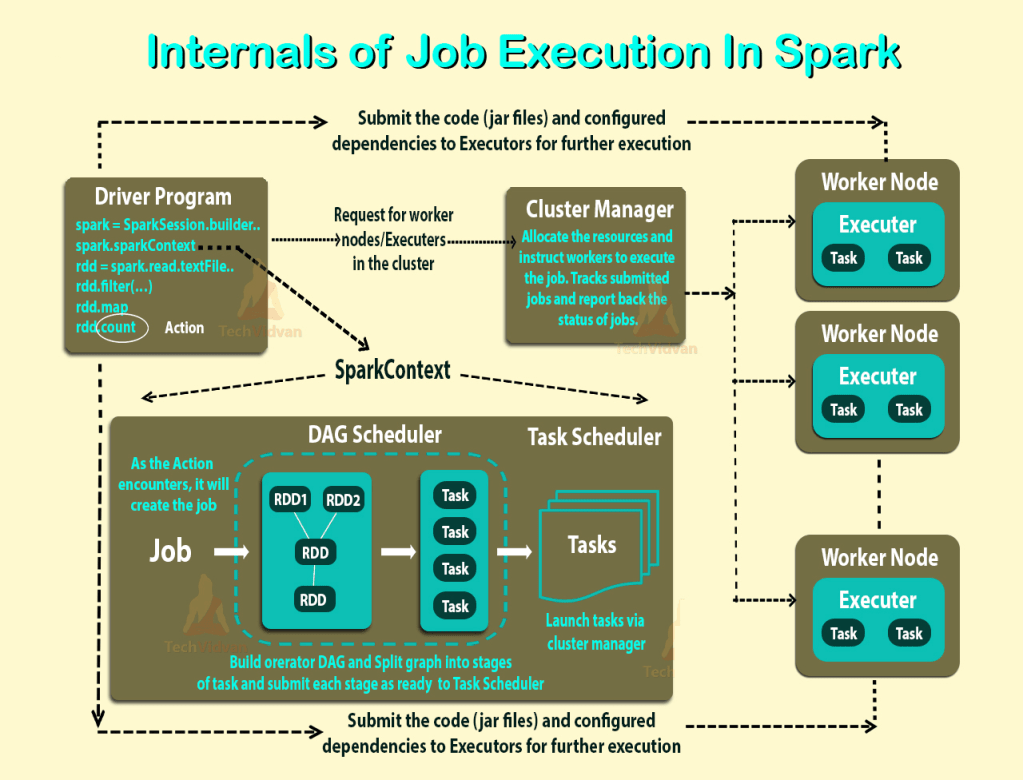
이제까지 설명한 내용을 그림으로 한번에 표현해보면 다음과 같습니다.
Practice
실습 과제입니다.
- Spark 에서는 어떤 설정 (Configuration) 의해 Partition 초기값이 정해지는지 찾아봅시다. 조금 지루하더라도 Spark Configuration 문서를 훑어보는건 큰 도움이 됩니다.
- Shuffle 이 언제 발생하는지 찾아 봅시다. 그 이후에 노트와 펜에 Shuffle 의 과정을 그려보면서 Partition 이 Executor 간에 어떻게 이동하는지 과정을 설명해 봅시다. (Hint: Shuffle Reader / Shuffle Writer)
- Action 을 호출했을 경우 Driver 로 부터 Executor 의 Task 가 실행되기 까지 어떤 과정을 거치는지 종이와 펜을 통해 그려봅시다.
“If you can’t explain it simply, you don’t understand it well enough”
“만약 그것(이론)을 쉽게 설명할 수 없다면 당신은 그걸 충분히 잘 안다고 할 수 없습니다.” (리처드 파인만)
Summary
이번 챕터에서는 Spark 의 각종 개념에 대해 알아보았습니다. 아래는 이번 챕터에서 다룬 핵심 키워드입니다.
- Partition
- Transformation / Action
- Shuffle
- Narrow / Narrow Transformation
- Job
- Stage
- Task
- Predicate Pushdown
- Execution Pipeline
- Logical Plan / Physical Plan

{kind=link}