Practical 시리즈는 AWS 환경 위에서 데이터 인프라를 구축하는데 참고할만한 내용들을 담고 있습니다. 이 글은 그 중 Practical Spark 의 한 챕터입니다. 이번 챕터에서는 Spark 내 구성 요소와 Architecture 에 대해 익혀보며 Spark 가 어떻게 동작하는지 알아보겠습니다. 다루는 주제는 Driver, Executor, Cluster Manager 입니다.

Practical 시리즈는 AWS 환경 위에서 데이터 인프라를 구축하는데 참고할만한 내용들을 담고 있습니다. 아래의 내용들을 주로 다룹니다.
- Practical Spark
- Practical Kafka
- Practical Kubernetes
- Practical AWS
이 블로그에 작성된 내용은 위 시리즈 중 Gitbook 으로 작성된 Practical Spark 를 옮긴 것입니다. 원본 Gitbook 와 실습에 사용하는 코드는 아래의 링크에서 보실 수 있습니다.
- (Spark Batch) https://1ambda.gitbook.io/practical-data-pipeline/02-processing/2.2-batch
- (Spark Stream) https://1ambda.gitbook.io/practical-data-pipeline/02-processing/2.4-stream
- (Code) https://github.com/1ambda/practical-data-pipeline-code
Spark Archtecture
이번 챕터에서 사용할 데이터셋은 Kaggle: Customer Personality Analysis 입니다. 아래와 같이 데이터를 로딩하고 일부 가공합니다.
| from pyspark.sql.functions import * | |
| from pyspark.sql.types import * | |
| from pyspark.sql import Row | |
| # DataBricks 로 실습한다면 경로를 "/FileStore/tables/marketing_campaign.csv" 로 변경합니다 | |
| df = spark.read.load("./marketing_campaign.csv", | |
| format="csv", | |
| sep="\t", | |
| inferSchema="true", | |
| header="true") | |
| dfSelected = df.select( | |
| col("ID").alias("id"), | |
| col("Year_Birth").alias("year_birth"), | |
| col("Education").alias("education"), | |
| col("Kidhome").alias("count_kid"), | |
| col("Teenhome").alias("count_teen"), | |
| col("Dt_Customer").alias("date_customer"), | |
| col("Recency").alias("days_last_login") | |
| ) | |
| dfConverted = dfSelected.withColumn("date_joined", | |
| add_months(to_date(col("date_customer"), "d-M-yyyy"), 72)) | |
| # Spark 가 파티션을 5개로 나누어 병렬처리 하도록 설정합니다. | |
| dfPartitioned = dfConverted.repartition(5) |
Spark Driver
Spark 는 크게 두 가지 컴포넌트로 구성되어 있습니다. Driver 와 Executor 입니다.
- Driver 는 1개로, 사용자의 Main 함수, 즉 사용자가 작성한 로직을 실행합니다. 이 과정에서 실행 계획을 생성해 Executor 에게 Task 를 할당할 수 있습니다.
- Driver 는 Cluster Manager 와 통신하며 Spark Application 관리합니다.
- Executor 는 여러개가 될 수 있습니다. 분산처리를 위해 Driver 가 요청한 계산 (Task) 을 수행할 수 있습니다. 이 결과는 Action 에 따라 (
collect) Driver 로 다시 돌려 보낼 수 있습니다. 혹은 Executor 에서 분산처리할 수 있는 Action 을 이용할 수도 있습니다. (foreachPartition) - Executor 는 사용자가 cache() 와 같은 함수 호출시 데이터를 메모리 (또는 디스크) 에 저장할 수 있습니다.
Cluster Manager 는 본 챕터의 아래 섹션에서 설명하겠지만, 다수개의 Spark 작업을 실행할 수 있도록 리소스를 관리해주는 Hadoop / AWS EMR 의 Yarn 혹은 Kubernetes 와 같은 클러스터를 말합니다.
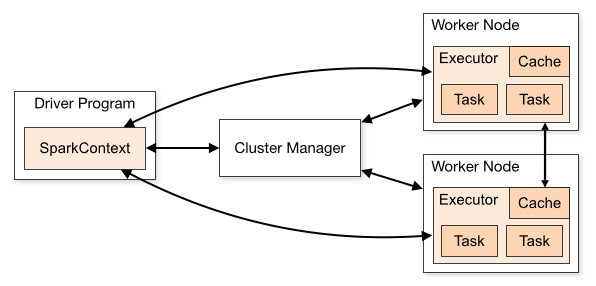
Spring Boot 와 같은 단일 머신을 위한 API Framework 와 다르게 Spark 의 코드는 Driver 와 Executor 에서 나누어 돌아갑니다. 지난 챕터에서 다루지 않았던 Action 몇 가지를 살펴보며 이 부분을 알아보겠습니다.
지난 챕터 Spark Concept 에서 다루었듯이, 데이터는 Partition 으로 구분되며 Executor 가 나누어 처리할 수 있다고 이야기 했었는데 Spark Dataframe 의 collect() Action 을 사용하면 Executor 에 분산되어 있던 데이터를 Driver 로 모을 수 있습니다.

| # 'collect()' 는 Executor 에서 파일 내의 데이터를 읽어 Driver 로 전송하는 Action 입니다. | |
| # 만약 cache() 등을 통해 캐싱되어 있다면 메모리에서 데이터를 찾아 보낼 수 있습니다. | |
| collected = dfPartitioned.collect() | |
| # type(collected) 의 실행 결과 | |
| list | |
| # collected[0] 의 실행 결과 | |
| Row(id=7196, year_birth=1950, education='PhD', count_kid=1, count_teen=1, date_customer='08-02-2014', days_last_login=20, date_joined=datetime.date(2020, 2, 8)) |
collect() 를 통해 가져온 데이터는 더이상 Spark 의 DataFrame 이 아니기에 분산되어 있는 데이터가 아닙니다. 타입도 일반 list 이며 Driver 메모리에 존재하는 일반 변수이므로 다른 변수와 같이 연산할 수 있습니다.
| from pyspark.sql import Row | |
| missing_days = 10 | |
| # Spark 의 Row 는 read-only 입니다. 따라서 Python 에서 변경하기 위해 Dict 로 변경 후 다시 Row 로 되돌립니다. | |
| # 효율적인 방법이 아니며, 내부 동작의 이해를 돕기 위해 만든 코드입니다. | |
| def updateDaysLastLogin(row): | |
| parsed = row.asDict() | |
| parsed['days_last_login'] = parsed['days_last_login'] + missing_days | |
| return Row(**parsed) | |
| updated = list(map(updateDaysLastLogin, collected)) | |
| # updated[0] 의 출력 결과 | |
| Row(id=7196, year_birth=1950, education='PhD', count_kid=1, count_teen=1, date_customer='08-02-2014', days_last_login=30, date_joined=datetime.date(2020, 2, 8)) |
missing_days = 10 는 Python, 즉 메인 로직에만 (Driver) 존재하는 변수이며 이 값을 이용해 days_last_login 값을 변경한 것을 알 수 있습니다. 주석에 달린바와 같이 일반적으로는 위와 같은 방식으로 데이터를 가공하지 않습니다. Spark DataFrame 에서 withColumn 등을 통해 효율적으로 Executor 에서 분산처리 하는것이 효율적입니다.
Python 의 경우에는 toPandas() Action 을 이용하면 Pandas DataFrame 으로 바꾼 후 데이터를 Pandas API 로 변경할 수 있습니다. (Pandas.Dataframe.add)
10개 의 Executor 가 나누어 처리하던 총합 100 GB 만큼의 데이터를, Driver 로 가져오려면 어떤일이 발생할까요? Driver 의 메모리가 모자라진 않을지, 데이터를 전송하는 과정에서 네트워크 비용이 비싸진 않을지 생각해봅시다.
Q. 그렇다면 언제 Driver 로 데이터를 가져와야 할까요?
Driver 는 다음 설정을 통해 리소스를 조절할 수 있습니다. 만약 필요에 의해 collect() 등을 사용해 Driver 로 데이터를 가져와 처리한다면 리소스를 처리에 요구되는 만큼 늘려 사용할 수 있습니다.
| spark.driver.cores # Driver 에서 사용할 CPU Core 숫자 | |
| spark.driver.memory # Driver 에서 사용할 메모리 GiB |
Executor

Executor 는 Spark Driver 에서 요청한 작업을 분산처리 하거나 cache() 로 데이터를 분산 저장한 값을 들고 있습니다. 사용자 요청에 따라 갯수와 리소스를 조절할 수 있으며 다음의 옵션을 사용합니다.
| spark.executor.instances # 하나의 Spark 작업에서 사용할 Executor 수 | |
| spark.executor.cores # 개별 Executor 에서 사용할 CPU Core 숫자 | |
| spark.executor.memory # 개별 Executor 에서 사용할 Memory GiB |
spark.executor.instances 에 지정된 숫자 만큼 Executor 가 생성됩니다. Driver 는 Executor 를 기다리기 위해 아래에 지정된 spark.scheduler 옵션만큼 대기합니다. 80% 의 Executor 가 사용할 수 있는 상태가 되기까지 기다리거나, 아니면 30초가 넘을 경우 Task 를 할당합니다.
| spark.scheduler.maxRegisteredResourcesWaitingTime = 30s (default) | |
| spark.scheduler.minRegisteredResourcesRatio = 0.8 (for Kuberntes, Yarn) |
따라서 Kubernetes 처럼 Cluster Autoscaler 로 인해 EC2 가 생성되고, 그 이후에 필요한 Docker Image 를 다운받는 등 대기 시간이 길 경우에는 위 옵션을 조절하면 충분한 시간만큼 대기 후 Executor 가 전부 준비가 되었을때 Task 를 할당해, 데이터가 특정 Executor 로 초기에 몰리는 것을 방지할 수 있습니다.
Executor 에서 분산 처리된 DataFrame 의 데이터를 Driver 에 데이터를 다시 모으기 위해 collect() 를 사용하는 방법을 다루었는데, 만약 Driver 로 데이터를 모을 필요가 없고, Executor 에서 그대로 데이터를 처리하고 싶다면 foreach(), foreachPartition() 함수를 사용할 수 있습니다.
| dfPartitioned = dfConverted.repartition(5) | |
| # foreach 함수는 Callback 파라미터로 Spark.DataFrame 의 Row 를 '하나씩' 전달합니다. | |
| def persist(row): | |
| parsed = row.asDict() | |
| # Do something here | |
| dfPartitioned.foreach(persist) |


이 때 foreach() 로 넘겨주는 커스텀으로 만든 persist Callback 함수는 Driver 가 아닌 Executor 에서 동작합니다. 따라서 persist() 내에서 print 함수를 사용하더라도 Jupyter Notebook 이나 Driver 에서 결과가 출력되지 않습니다.
Driver 가 아닌 Executor Process 의 로그를 확인해보면 다음과 같은 출력을 확인할 수 있습니다.
| ... (생략) | |
| Row(id=8397, year_birth=1951, education='Graduation', count_kid=1, count_teen=1, date_customer='10-01-2014', days_last_login=82, date_joined=datetime.date(2020, 1, 10)) | |
| Row(id=1685, year_birth=1967, education='PhD', count_kid=0, count_teen=0, date_customer='17-03-2013', days_last_login=21, date_joined=datetime.date(2019, 3, 17)) | |
| Row(id=5186, year_birth=1955, education='PhD', count_kid=0, count_teen=1, date_customer='12-03-2014', days_last_login=59, date_joined=datetime.date(2020, 3, 12)) | |
| Row(id=5429, year_birth=1948, education='PhD', count_kid=0, count_teen=1, date_customer='20-08-2013', days_last_login=10, date_joined=datetime.date(2019, 8, 20)) |
foreach 함수는 Dataframe.write 가 지원되지 않는 경우 혹은 더 세밀히 조절하기 위한 경우에 사용할 수 있는 Row-level API 로 일반적으로 DynamoDB 등 외부 스토리지로 데이터를 내보내기 위해 사용할 수 있습니다. DataFrame.write 함수는 추후에 다루겠지만, 다양한 형식으로 데이터를 내보낼때 사용합니다. Spark Data Sources 문서에서 빌트인으로 저장 가능한 형식을 확인할 수 있습니다.
spark-redis 처럼 벤더가 DataFrame.write 를 위한 라이브러리를 관리하는 경우도 있습니다. 아래에 몇개 스토리지에 대해 DataFrame.write 사용 가능한 경우를 정리해 봤습니다.
- Kafka Dataframe.write (Spark Docs, Built-in)
- ElasticSearch DataFrame.write (ElasticSearch Docs, Vendor)
- Cassandra DataFrame.write (Datastax Github, Vendor)
foreach() 함수가 DataFrame.Row (한 줄) 만큼 받아 처리할 수 있는 옵션을 제공한다면 foreachPartition() 함수는 Partition 단위로 데이터를 다룰 수 있는 Action 입니다. 우리는 이미 DataFrame.repartition() 함수를 통해 파티션을 적절히 나누어 놓았기 때문에 Partition 숫자만큼 foreachPartition() callback 이 호출됩니다.
| def persistPartition(partitionedRows): | |
| for row in partitionedRows: | |
| parsed = row.asDict() | |
| # DO something here | |
| dfPartitioned.foreachPartition(persistPartition) |
foreachPartition() 은 데이터를 뭉텅이로, 즉 Partition 단위로 사용자에게 줍니다. 따라서 사용자는 외부 저장소로 보낼때 묶음 단위 로 보낼 수 있고 외부 저장소로 보내는 커넥션 비용이 비싼 경우에 foreach() 보다 foreachPartition 을 유용하게 사용할 수 있습니다.
만약 Partition 숫자가 적어 하나의 Partition 내의 데이터가 너무 크다면, foreachPartition 을 실행하는 Executor 에겐 어떤 일이 발생할까요? 메모리 관점에서 논의해 봅시다. 더 많은 파티션으로 나눌때, 만약 사용자를 기준으로 순서를 정렬해서 전송해야 한다면 어떻게 할 수 있을까요?
- repartition(200, “id”).foreachPartition() 은 어떤 결과를 만들어낼지 논의해 봅시다.
지금까지 foreach() 와 foreachPartition() 을 알아 보았습니다. 만약 여러 Row 를 묶어서 처리하는 경우 foreach() 와 foreachPartition() 함수중 어떤 것을 사용하는 것이 좋은지 논의해 봅시다.
- Kafka 로 데이터를 보낼 때 묶어서 보낸다면 네트워크 비용을 아낄 수 있습니다. (10개, 20개 등)
- MySQL 로 데이터를 Insert 할 때 Bulk 로 Insert 할 수 있다면 Connection 과 네트워크 비용을 아낄 수 있습니다.
foreach()를 이용한다면 여러 Row 를 묶어서 보낼 수 있을까요?
또한 데이터를 전송할 때 ‘순서’ 를 보존해야 하는 경우를 생각해 봅시다.
- 사용자 A 의 로그는 이벤트 시간 순서대로 전송해야 합니다.
foreach()를 통해서 각각 보낸다면 순서를 보장할 수 있을까요?
Cluster Manager

Cluster Manager 는 Spark 가 실행될 수 있는 리소스를 제공합니다. Driver 가 관리하는 SparkContext 는 어떤 Cluster Manager 에 연결할지에 대한 정보를 포함해 다양한 내용을 담고 있습니다.Driver 를 통해 Spark 가 Cluster Manager 에 연결되면 Executor 실행에 필요한 리소스를 얻어올 수 있습니다. Spark 는 다양한 Cluster Manager 를 지원합니다.
- Standalone
- Apache Mesos
- Hadoop Yarn
- Kubernetes
일반적으로 Yarn 과 Kubernetes 가 많이 쓰입니다. AWS 환경에서는 AWS EMR 을 통해 Spark 를 위한 Yarn 클러스터를 쉽게 세팅할 수 있습니다.
AWS EMR 은 사용자에게 여러가지 편리성을 제공합니다. Hadoop Yarn 을 쓸 경우 HDFS 에 데이터로 관리하곤 하는데, AWS EMR 의 emrfs 를 이용하면 AWS S3 를 스토리지로 쓸 수 있습니다. 따라서 컴퓨팅과 데이터 보관을 분리해 클러스터 운영자가 용이하게 관리할 수 있을뿐만 아니라 S3 의 Storage Class 를 이용해 비용 절감을 하는 등 S3 의 다양한 기능을 활용할 수 있습니다. 비용 측면에서도 ‘머신’ 을 유지하며 데이터를 보관하는 것이 아니기 때문에 (Data Node) 저렴합니다.
다만 Cloud 의 오브젝트 스토리지는 파일 시스템이 아니기 때문에 Spark 문서 가이드를 따라 추가적인 옵션 설정이 필요합니다.
Kubernetes 는 Spark 3.1+ 부터 GA 로 지원되는 Cluster Manager 입니다. Kubernetes 에 존재하는 Cluster Autoscaler Addon 이나 Prometheus Stack 등 모니터링 레이어를 그대로 활용할 수 있습니다.
만약 AWS 를 사용한다면 AWS EKS (Managed Kubernetes) 를 통해 손쉽게 Kubernetes Cluster 를 띄우고 관리할 수 있습니다.
오브젝트 스토리지와 파일 시스템은 무엇이 다를까요? 그리고 그 차이점이 Spark 를 사용할 때 어떤 영향을 미칠까요?
Mode, Interface
Spark 는 사용자의 환경에 맞추어 여러가지 실행 모드를 지원합니다.
- 실행 위치 기준으로는 Local / Client / Cluster 모드를 지원하고
- 인터페이스 기준으로는 Shell / Notebook / Application (Jar Submit) 을 제공합니다.
우선 실행 위치 기준의 분류 부터 살펴보면 Local 모드는 현재 머신에서만 Spark 를 실행합니다. 1개의 머신만 사용하므로 머신 여러대로 수행하는 분산처리는 되지 않습니다. 개발 및 테스트 용도로 많이 사용합니다. 아래 사진은 Local 모드로 실행한 Spark 의 구조를 나타냅니다. 하나의 JVM (= Java Process) 안에 Driver 와 Executor 가 같이 위치해 있는것을 볼 수 있습니다.
만약 Spark 를 단일 머신에서 Local 모드로 사용한다면, 똑같은 리소스를 여러대로 나누어 분산처리 하는 케이스에 비해 어떤 이점이 있을까요?
- Case 1) 30 vCPU, 250 GiB 단일 머신
- Case 2) Driver 5 vCPU, 50 GiB 1개, Executor 5 vCPU, 40 GiB 5개
리소스 활용 측면에서의 차이 뿐만 아니라, 알고리즘이나 라이브러리 활용 측면에서는 어떨까요? 만약 우리가 사용해야 하는 모델의 학습이 분산처리가 되지 않는다면 어떤 모드를 선택해야 할지 어떨지 고민해 봅시다.

다음은 Client / Cluster 모드입니다. Client 모드와 Cluster 의 차이점은, 작업의 요청은 둘 다 사용자가 Submit 명령을 실행하는 위치에서 발생하나 Driver 의 동작 위치가 다르다는 것입니다.
- Client 모드는 Submit 이 요청된 위치에서 동작합니다. 따라서 한 머신에서 여러개의 Spark Application 으로 실행하는 경우 수 많은 Driver 로 인해 Submit 을 요청하는 머신의 리소스가 전부 소모되어 문제가 발생할 수 있습니다.
- 반면 Cluster 모드는 Submit 이 요청된 이후에 Driver 가 요청된 위치가 아니라 Cluster 에서 돌아갑니다. 따라서 요청과 실제 Driver 가 분리되며,
spark.yarn.submit.waitAppCompletion를 통해 Submit 요청하는 커맨드나 스트립트가 Driver 종료까지 대기할지, 아니면 바로 종료할지 선택할 수 있습니다.
아래 사진을 통해 Spark Client 모드와 Spark Cluster 모드를 비교해 볼 수 있습니다.

아래 그림들은 Client / Cluster 모드 각각의 경우를 조금 더 자세하게 보여줍니다.

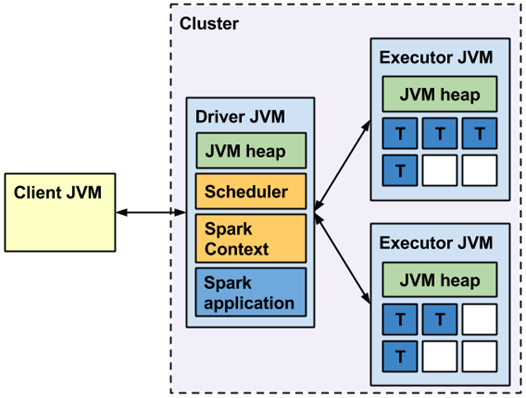
Cluster 모드는 왜 필요한걸까요? 만약 EC2 위에 설치한 Airflow 에서 Local Executor 로 Spark Submit 을 Client 모드로 수 없이 많이 하면 어떤 문제가 생길지 고민해 봅시다.
EMR and Yarn Cluster Manager
Spark 를 Cluster 모드로 Submit 할 경우 AWS EMR 을 이용한다면, 더 엄밀하는 AWS EMR 이 제공하는 Yarn 을 Cluster Manager 로 사용한다면 EMR 5 버전에서는 Spark Driver 가 EMR Core 에서 동작합니다.
- EMR 은 Master / Core / Task 로 나누어지며 Core 는 HDFS 를 관리하는 Data Node 역할을 합니다. 반면 Task 는 HDFS 를 관리하지 않고 컴퓨팅만 수행하는 Compute Node 역할을 합니다.
- https://docs.aws.amazon.com/ko_kr/emr/latest/ManagementGuide/emr-master-core-task-nodes.html
EMR 6 를 사용한다면 Core 대신 Driver 가 어디서든 동작할 수 있습니다. 혹은 EMR 5 를 사용하더라도 아래 옵션을 변경해 Spark Cluster Mode 로 요청된 Driver 의 실행 노드 타입을 결정할 수 있습니다.
| yarn.node-labels.enabled: true | |
| yarn.node-labels.am.default-node-label-expression: 'CORE' |
여기서 am 은 Yarn Appliaction Master, 즉 Spark 의 Driver 를 말합니다. Yarn 은 범용 리소스 매니저로 설계되었으므로 Flink 사용시 am 은 Flink Job Manager 가 됩니다. 아래 그림은 Spark, Flink 가 Yarn 에서 Cluster 모드로 동작할 경우 AM 과 컨테이너들이 어떤 컴포넌트인지를 잘 보여줍니다.


EMR 에 대해 조금 더 고민해 봅시다. EMR 은 Master / Core / Task 노드로 구분이 되고 일반적으로 Yarn Cluster 모드로 Submit 시에 Spark Driver 는 Core 에서 동작합니다.
- Driver 를 이렇게 Core 에서 묶어서 관리하는 것의 장점은 무엇일까요?
- Executor 는 반면 Core 가 아니라 Task 에서 돌아갈텐데, Driver 와 Executor 가 사용하는 리소스의 양은 차이가 있을까요?
- 차이가 있다면 Core 와 Task 를 분리해서 다른 타입의 EC2 머신을 사용한다면 리소스 관리에서 어떤 이점이 있을까요?


Practice
실습 과제입니다. 로컬 환경에서 Spark Cluster 를 띄우고 Spark 작업을 Submit 해 봅니다. 아래의 레포지토리 내의 코드를 참조할 수 있습니다.
Client 모드로 Submit 하는 것과 Cluster 모드로 Submit 하는 것은 각각 어떻게 하는 것인지 다음 문서를 통해 찾아보고 실행해봅시다.
또한, Cluster 모드로 작업을 Submit 한다면, Driver 가 Cluster 내에서 실행되므로 Submit 하는 프로세스가 바로 종료될 수 있습니다.
- 바로 종료되지 않도록 하려면 어떤 옵션을 사용해야 할까요?
- https://spark.apache.org/docs/latest/running-on-yarn.html 문서에서 다음 옵션을 찾아봅시다.
spark.yarn.submit.waitAppCompletion
Spark 작업이 단순히 ‘종료’ 된 것과 실제로 데이터를 잘 생성하고 적재했음을 어떻게 파악할 수 있을까요?
- Digdag 의 S3 Wait Plugin 이나 Airflow 의 S3 Key Sensor 를 찾아봅시다.
- 왜
SELECT count(*) FROM X > 0처럼 Row 숫자를 비교하지 않을까요? Hive Metastore 부담 측면에서도 같이 고민해 봅시다.
Summary
아래는 이번 챕터에서 다룬 핵심 키워드입니다.
- Driver
- Executor
- collect(), foreach(), foreachPartition()
- Spark Local / Client / Cluster 모드
- AWS EMR Master / Core / Task
