Practical 시리즈는 AWS 환경 위에서 데이터 인프라를 구축하는데 참고할만한 내용들을 담고 있습니다. 이 글은 그 중 Practical Spark 의 한 챕터입니다. 이번 챕터에서는 DataFrame 을 사용해보며 실제 Case 를 바탕으로 문제를 해결해봅니다. 이 과정에서 Window Function 을 사용해보고, Attribution 과 Session 을 만드는 방법을 배웁니다.

Practical 시리즈는 AWS 환경 위에서 데이터 인프라를 구축하는데 참고할만한 내용들을 담고 있습니다. 아래의 내용들을 주로 다룹니다.
- Practical Spark
- Practical Kafka
- Practical Kubernetes
- Practical AWS
이 블로그에 작성된 내용은 위 시리즈 중 Gitbook 으로 작성된 Practical Spark 를 옮긴 것입니다. 원본 Gitbook 와 실습에 사용하는 코드는 아래의 링크에서 보실 수 있습니다.
- (Spark Batch) https://1ambda.gitbook.io/practical-data-pipeline/02-processing/2.2-batch
- (Spark Stream) https://1ambda.gitbook.io/practical-data-pipeline/02-processing/2.4-stream
- (Code) https://github.com/1ambda/practical-data-pipeline-code
Loading Sample Data
Spark Tutorial 에서는 DataFrame 의 기초적인 내용을 2천 건 정도의 작은 데이터셋을 이용해 다루어보았습니다. 이제는 조금 더 복잡하면서도 실제로 많이 활용되는 사례를 바탕으로 유용한 함수들을 알아봅시다.
이번 챕터에서 사용할 데이터는 Kaggle eCommerce Events History In Cosmetic Shop (2020-Jan.csv) 입니다.
ecommerce_event.csv 란 이름으로 저장 후 다음과 같이 SparkSession.read.load 함수를 이용해 로딩합니다. 이번에 사용하는 데이터셋의 구분자는 \t 가 아니라 , (comma) 이므로 sep 옵션을 생략해도 좋습니다.
| from pyspark.sql.types import * | |
| from pyspark.sql.functions import * | |
| from pyspark.sql.window import Window | |
| df = spark.read.load("./ecommerce_event.csv", | |
| format="csv", inferSchema="true", header="true") | |
| df.count() # 4264752, 약 450 MiB 파일 | |
| df.printSchema() | |
| root | |
| |-- event_time: string (nullable = true) | |
| |-- event_type: string (nullable = true) | |
| |-- product_id: integer (nullable = true) | |
| |-- category_id: long (nullable = true) | |
| |-- category_code: string (nullable = true) | |
| |-- brand: string (nullable = true) | |
| |-- price: double (nullable = true) | |
| |-- user_id: integer (nullable = true) | |
| |-- user_session: string (nullable = true) |
DataFrame Basic and Aggregation
우선 event_time 컬럼을 살펴봅시다. agg 함수는 SQL 에서 Group By 후 Select 에서 사용하는 Aggregation 함수와 동일합니다.
| df.agg(max("event_time"), min("event_time")).show(truncate=False) | |
| +-----------------------+-----------------------+ | |
| |max(event_time) |min(event_time) | | |
| +-----------------------+-----------------------+ | |
| |2020-01-31 23:59:58 UTC|2020-01-01 00:00:00 UTC| | |
| +-----------------------+-----------------------+ |
brand 별로 category 를 살펴봅시다. SQL 로 치자면 Group By 후 Count 하는 간단한 함수입니다.
| df.groupBy(col("brand"), col("category")).agg(count("*")).show() | |
| +---------+-------------------+--------+ | |
| | brand| category_id|count(1)| | |
| +---------+-------------------+--------+ | |
| | runail|1487580007936033754| 4395| | |
| | oniq|1487580005092295511| 3298| | |
| | domix|1487580011970953351| 1292| | |
| | bioaqua|1597770225539875791| 113| | |
| | domix|1487580007256556476| 1133| | |
| | ingarden|1487580011996119176| 900| | |
| | markell|1783999067156644376| 205| | |
| | null|1487580008145748965| 19054| | |
| | null|1487580011677352062| 6008| | |
| | null|1998040852064109417| 880| | |
| |beautific|1487580008288355308| 37| | |
| | naomi|1487580012524601496| 86| | |
| | missha|1783999073758478650| 6| | |
| | null|2145935122136826354| 1| | |
| | runail|1487580009051717646| 2630| | |
| | kiss|1487580013506068678| 237| | |
| | pnb|1487580007457883075| 491| | |
| |bespecial|1487580013338296510| 134| | |
| | eunyul|1487580011585077370| 1860| | |
| | matrix|1487580008263189483| 573| | |
| +---------+-------------------+--------+ |
여러분이 작업하는 대부분의 DataFrame 데이터 가공은 SQL 로 생각하면 쉽습니다. 대응하는 함수가 거의 대부분 있습니다. 필요하다면 Spark SQL 을 사용할 수 있습니다. 추후 이어질 아래의 섹션에서 Spark SQL 을 이용해 데이터를 가공하는 법을 배웁니다.
| df\ | |
| .groupBy("brand", "category_code")\ | |
| .agg(countDistinct("product_id").alias("product_count"))\ | |
| .show(truncate=False) | |
| +------------+--------------------------------------+-------------+ | |
| |brand |category_code |product_count| | |
| +------------+--------------------------------------+-------------+ | |
| |beautix |null |316 | | |
| |dr.gloderm |null |31 | | |
| |farmona |null |39 | | |
| |profhenna |null |56 | | |
| |runail |appliances.environment.vacuum |3 | | |
| |invisibobble|null |2 | | |
| |macadamia |appliances.environment.air_conditioner|1 | | |
| |riche |null |58 | | |
| |nova |null |1 | | |
| |oniq |null |590 | | |
| |lebelage |null |45 | | |
| |fancy |null |15 | | |
| |vilenta |null |20 | | |
| |siberina |null |181 | | |
| |tertio |null |115 | | |
| |jaguar |null |21 | | |
| |nitrimax |apparel.glove |21 | | |
| |jas |null |16 | | |
| |rocknailstar|null |6 | | |
| |koreatida |null |3 | | |
| +------------+--------------------------------------+-------------+ |
SQL 과 유사하게 하나의 컬럼에 존재하는 ENUM 타입 값을 보기 위해 Group By 를 사용할수도 있겠지만, Distinct 를 활용할 수 있습니다.
| df.select("event_type").distinct().show() | |
| +----------------+ | |
| | event_type| | |
| +----------------+ | |
| | purchase| | |
| | view| | |
| | cart| | |
| |remove_from_cart| | |
| +----------------+ |
purchase (구매) 이벤트가 있으니, 일별로 구매 이벤트를 집계해봅시다. event_time 은 epoch second 값이므로, 일 (Day) 로 변경해야 합니다. selectExpr 함수를 쓰면, SQL 식으로 컬럼을 변경할 수 있습니다.
여기서 잠깐 생각해 볼 것은, 시간 값으로 Epoch Second, Epoch Millis 를 사용할 때의 장점은 무엇일까요?
- 만약 원본 데이터가 KST 로 되어있을때, 해외에 거주하는 엔지니어 입장에서 데이터를 보면서 디버깅이 쉬울지도 생각해봅시다.
- 만약 다국적 서비스를 하면서 데이터를 한 곳으로 모아야 한다면 어떤 Time Zone 을 쓰는게 맞을까요?
event_time 을 DATE 로 변경한 후 Group By 해서 일별 구매 이벤트 숫자를 집계해보면 다음과 같습니다. 이 과정에서 구매 이벤트만 필터링 하기 위해 where 함수를 사용합니다.
| eventPurchase = "purchase" | |
| df\ | |
| .selectExpr("CAST(event_time as DATE) as event_date", "event_type")\ | |
| .where(col("event_type") == lit(eventPurchase))\ | |
| .groupBy("event_date")\ | |
| .agg(count("*").alias("purchase_count"))\ | |
| .orderBy(asc("event_date"))\ | |
| .show(truncate=False) | |
| +----------+--------------+ | |
| |event_date|purchase_count| | |
| +----------+--------------+ | |
| |2020-01-01|3269 | | |
| |2020-01-02|4875 | | |
| |2020-01-03|6031 | | |
| |2020-01-04|6602 | | |
| |2020-01-05|7227 | | |
| |2020-01-06|6368 | | |
| |2020-01-07|7564 | | |
| |2020-01-08|7602 | | |
| |2020-01-09|8774 | | |
| |2020-01-10|8575 | | |
| |2020-01-11|7470 | | |
| |2020-01-12|8147 | | |
| |2020-01-13|10138 | | |
| |2020-01-14|10316 | | |
| |2020-01-15|9962 | | |
| |2020-01-16|9354 | | |
| |2020-01-17|9265 | | |
| |2020-01-18|6197 | | |
| |2020-01-19|8168 | | |
| |2020-01-20|9014 | | |
| +----------+--------------+ |
이제 where 함수를 익혔으니 브랜드별 전체 판매 금액에 대해서도 추출해 볼 수 있습니다. 전체 기간 내 판매가 가장 많은 브랜드 10개만 추출해 보겠습니다.
| df\ | |
| .selectExpr("brand", "price")\ | |
| .where("brand IS NOT NULL")\ | |
| .groupBy("brand")\ | |
| .agg(sum("price").alias("sales_price"))\ | |
| .orderBy(desc("sales_price"))\ | |
| .limit(10)\ | |
| .show(truncate=False) | |
| +--------+------------------+ | |
| |brand |sales_price | | |
| +--------+------------------+ | |
| |strong |2651513.6799999983| | |
| |jessnail|2297451.200000003 | | |
| |runail |2108654.9900000114| | |
| |irisk |1467889.08999999 | | |
| |grattol |1055984.4699999897| | |
| |marathon|789238.6300000004 | | |
| |masura |693152.7399999842 | | |
| |cnd |599136.3200000003 | | |
| |uno |546019.0499999991 | | |
| |estel |544366.7999999983 | | |
| +--------+------------------+ |

광고 비즈니스에서는 다음의 용어가 존재합니다.
- ARPU (Average Revenue Per User): 전체 사용자 대비 수익입니다.
- ARPPU (Average Revenue Per Paid User): 결제 사용자 대비 수익입니다.
위 그림에서는 A/B 테스팅시에 실험군과 대조군을 나누어 ARPPU / ARPU 를 비교하는 것을 도표로 보여줍니다.
이제 Spark DataFrame 을 이용해 현재 우리가 사용하는 데이터셋 내 브랜드별 ARPPU 와 ARPU 를 구해봅시다.
| df\ | |
| .selectExpr("brand", "price", "user_id", "event_type")\ | |
| .where("brand IS NOT NULL")\ | |
| .groupBy("brand")\ | |
| .agg( | |
| countDistinct("user_id").alias("user_count_all"), | |
| countDistinct(when(col("event_type") == lit(eventPurchase), col("user_id"))).alias("user_count_purchase"), | |
| sum("price").alias("sales_price"))\ | |
| .selectExpr( | |
| "brand", | |
| "sales_price", | |
| "user_count_all", | |
| "sales_price / user_count_all as ARPU", | |
| "user_count_purchase", | |
| "sales_price / user_count_purchase as ARPPU", | |
| )\ | |
| .orderBy(desc("sales_price"))\ | |
| .limit(10)\ | |
| .show(truncate=False) | |
| +--------+------------------+--------------+------------------+-------------------+------------------+ | |
| |brand |sales_price |user_count_all|ARPU |user_count_purchase|ARPPU | | |
| +--------+------------------+--------------+------------------+-------------------+------------------+ | |
| |strong |2651513.6799999983|5683 |466.5693612528591 |186 |14255.449892473109| | |
| |jessnail|2297451.200000003 |21039 |109.19963876610119|1119 |2053.1288650580905| | |
| |runail |2108654.9900000114|59595 |35.38308566154898 |9096 |231.8222284520681 | | |
| |irisk |1467889.08999999 |48028 |30.56319417839573 |7277 |201.71624158306858| | |
| |grattol |1055984.4699999897|34884 |30.271312636165284|4732 |223.15817202028524| | |
| |marathon|789238.6300000004 |2871 |274.9002542668061 |38 |20769.437631578956| | |
| |masura |693152.7399999842 |22668 |30.578469207692965|3085 |224.6848427876772 | | |
| |cnd |599136.3200000003 |9129 |65.63000547705118 |597 |1003.578425460637 | | |
| |uno |546019.0499999991 |16370 |33.35485949908364 |2446 |223.2293744889612 | | |
| |estel |544366.7999999983 |24438 |22.27542352074631 |2130 |255.571267605633 | | |
| +--------+------------------+--------------+------------------+-------------------+------------------+ |
Window Function
이제 몇 가지 조금 더 복잡한 집계를 위해 Window 함수를 익혀봅니다. Window 함수를 통해 사용자는 특정 집합에 대해 행간의 관계를 집계할 수 있습니다.

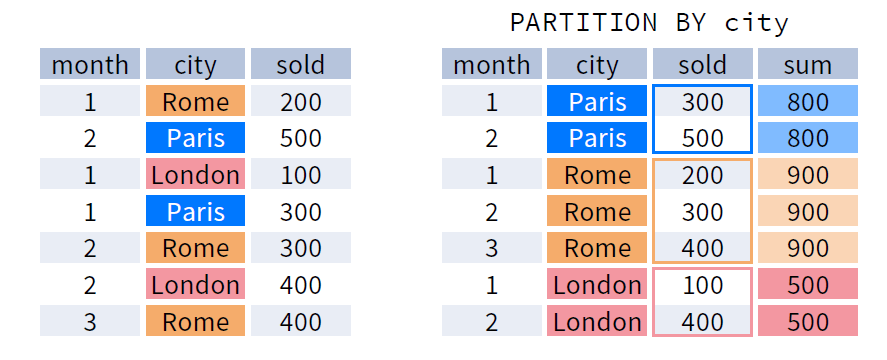
대부분의 데이터 처리 프레임워크는 Window Function 을 지원합니다.
이제 Window Function 을 이용해 다음 4가지 문제를 풀어봅시다.
- 전체 기간동안 브랜드별로 두번째로 많이 팔린 (판매 금액 총합이 높은) 상품 카테고리는 무엇입니까?
- 일별로 많이 팔린 (판매 금액 총합이 높은) 브랜드별 랭킹 Top 3 는 무엇입니까?
- 전체 기간동안 브랜드별 판매 금액의 합이나 순위가 아니라, 실제 격차를 나타낼 수 있는 비중을 (Percentile) 구하면 어떻게 됩니까?
- 일별로 모든 브랜드를 통틀어, 판매 금액의 합산을 누적으로 구하면 매출의 변화량은 어떻게 변화합니까?
문제를 잘 살펴보면, 단순 Group By 보다는 조금 더 까다로움을 알 수 있습니다. 이해를 돕기 위해 우선 Spark SQL 을 이용해 문제를 풀어보고, 각각의 경우에 대해 PySpark DataFrame 코드도 같이 적어보겠습니다.

Spark DataFrame.createOrReplceTempView 를 이용하면 DataFrame 을 일종의 Table (더 엄밀히는 실존하지 않고, 테이블처럼만 보이는 View) 와 같이 쓸 수 있습니다. 등록 이후에 SparkSession.sql 을 이용해 만들어진 View (DataFrame) 를 가공할 수 있으며 이 것의 결과 또한 DataFrame 입니다. 즉 SQL 문법을 이용해 Transformation 을 수행할 수 있습니다.
| df.createOrReplaceTempView("PURCHASE") | |
| spark.sql(""" | |
| SELECT * | |
| FROM PURCHASE | |
| LIMIT 10 | |
| """).show() | |
| +--------------------+----------------+----------+-------------------+-------------+--------+------+---------+--------------------+ | |
| | event_time| event_type|product_id| category_id|category_code| brand| price| user_id| user_session| | |
| +--------------------+----------------+----------+-------------------+-------------+--------+------+---------+--------------------+ | |
| |2020-01-01 00:00:...| view| 5809910|1602943681873052386| null| grattol| 5.24|595414620|4adb70bb-edbd-498...| | |
| |2020-01-01 00:00:...| view| 5812943|1487580012121948301| null|kinetics| 3.97|595414640|c8c5205d-be43-4f1...| | |
| |2020-01-01 00:00:...| view| 5798924|1783999068867920626| null| zinger| 3.97|595412617|46a5010f-bd69-4fb...| | |
| |2020-01-01 00:00:...| view| 5793052|1487580005754995573| null| null| 4.92|420652863|546f6af3-a517-475...| | |
| |2020-01-01 00:00:...| view| 5899926|2115334439910245200| null| null| 3.92|484071203|cff70ddf-529e-4b0...| | |
| |2020-01-01 00:00:...| view| 5837111|1783999068867920626| null| staleks| 6.35|595412617|46a5010f-bd69-4fb...| | |
| |2020-01-01 00:00:...| cart| 5850281|1487580006300255120| null|marathon|137.78|593016733|848f607c-1d14-474...| | |
| |2020-01-01 00:00:...| view| 5802440|2151191070908613477| null| null| 2.16|595411904|74ca1cd5-5381-4ff...| | |
| |2020-01-01 00:00:...| view| 5726464|1487580005268456287| null| null| 5.56|420652863|546f6af3-a517-475...| | |
| |2020-01-01 00:01:...|remove_from_cart| 5850281|1487580006300255120| null|marathon|137.78|593016733|848f607c-1d14-474...| | |
| +--------------------+----------------+----------+-------------------+-------------+--------+------+---------+--------------------+ |
이제 SQL / DataFrame 버전으로 각각 Window 함수를 이용해 위 문제를 풀어보겠습니다.
1. 전체 기간동안 브랜드별로 가장 많이 팔린 (판매 금액 총합이 높은) 상품 카테고리

Spark SQL 을 이용하면 아래와 같이 문제를 풀수 있습니다.
| spark.sql(""" | |
| WITH CALCULATED ( | |
| SELECT | |
| brand, | |
| category_code, | |
| sum(price) as price_sum | |
| FROM PURCHASE | |
| WHERE | |
| brand IS NOT NULL | |
| AND category_code IS NOT NULL | |
| GROUP BY brand, category_code | |
| ), | |
| RANKED ( | |
| SELECT | |
| brand, | |
| category_code, | |
| price_sum, | |
| rank() OVER (PARTITION BY brand ORDER BY price_sum DESC) as rank | |
| FROM CALCULATED | |
| ) | |
| SELECT * | |
| FROM RANKED | |
| WHERE rank = 1 | |
| ORDER BY price_sum DESC | |
| """).show(truncate=False) |
다음은 PySpark DataFrame 으로 위 코드를 변환한 결과입니다.
| dfCalculated = df\ | |
| .select( | |
| col("brand"), | |
| col("category_code"), | |
| col("price"), | |
| )\ | |
| .where(col("brand").isNotNull() & col("category_code").isNotNull())\ | |
| .groupBy("brand", "category_code")\ | |
| .agg(sum("price").alias("price_sum")) | |
| dfRanked = dfCalculated\ | |
| .select( | |
| col("brand"), | |
| col("category_code"), | |
| col("price_sum"), | |
| rank().over(Window.partitionBy(col("brand")).orderBy(desc("price_sum"))).alias("rank") | |
| ) | |
| dfRanked\ | |
| .where(col("rank") == lit(1))\ | |
| .orderBy(desc("price_sum"))\ | |
| .show(truncate=False) |
결과는 아래와 같이 동일합니다.
| +---------+-------------------------------+------------------+----+ | |
| |brand |category_code |price_sum |rank| | |
| +---------+-------------------------------+------------------+----+ | |
| |max |appliances.environment.vacuum |489141.04999999976|1 | | |
| |polarus |appliances.environment.vacuum |418171.82000000007|1 | | |
| |emil |appliances.environment.vacuum |296071.9100000001 |1 | | |
| |jessnail |appliances.environment.vacuum |136883.68 |1 | | |
| |runail |furniture.living_room.cabinet |125213.18000000004|1 | | |
| |irisk |furniture.bathroom.bath |79211.96 |1 | | |
| |vosev |accessories.bag |48592.50000000001 |1 | | |
| |benovy |apparel.glove |43165.819999999985|1 | | |
| |kosmekka |furniture.living_room.cabinet |42673.57000000006 |1 | | |
| |italwax |stationery.cartrige |17865.97999999999 |1 | | |
| |jaguar |appliances.personal.hair_cutter|16316.279999999988|1 | | |
| |nitrimax |apparel.glove |14064.090000000006|1 | | |
| |nitrile |apparel.glove |10399.849999999999|1 | | |
| |kondor |appliances.personal.hair_cutter|9074.939999999997 |1 | | |
| |domix |furniture.bathroom.bath |5248.419999999998 |1 | | |
| |shik |accessories.cosmetic_bag |4122.72 |1 | | |
| |depilflax|stationery.cartrige |3861.7799999999966|1 | | |
| |gezatone |appliances.personal.massager |3240.320000000001 |1 | | |
| |naturmed |furniture.bathroom.bath |2997.71 |1 | | |
| |naomi |apparel.glove |2002.319999999998 |1 | | |
| +---------+-------------------------------+------------------+----+ |
2. 일별로 많이 팔린 (판매 금액 총합이 높은) 브랜드별 랭킹 Top 3
Spark SQL 을 이용해 WITH 구문과 rank() Window 함수를 이용하면 다음과 같이 문제를 풀 수 있습니다.
| spark.sql(""" | |
| WITH CALCULATED ( | |
| SELECT | |
| CAST(event_time AS DATE) as event_date, | |
| brand, | |
| sum(price) as price_sum | |
| FROM PURCHASE | |
| WHERE | |
| brand IS NOT NULL | |
| GROUP BY 1, 2 | |
| ), | |
| RANKED ( | |
| SELECT | |
| event_date, | |
| brand, | |
| price_sum, | |
| rank() OVER (PARTITION BY event_date ORDER BY price_sum DESC) as rank | |
| FROM CALCULATED | |
| ) | |
| SELECT * | |
| FROM RANKED | |
| WHERE rank <= 3 | |
| ORDER BY event_date ASC, rank ASC | |
| """).show(truncate=False) |
다음은 실행 결과입니다.
| +----------+--------+------------------+----+ | |
| |event_date|brand |price_sum |rank| | |
| +----------+--------+------------------+----+ | |
| |2020-01-01|jessnail|58125.96000000012 |1 | | |
| |2020-01-01|strong |45510.60999999997 |2 | | |
| |2020-01-01|runail |40028.73999999981 |3 | | |
| |2020-01-02|jessnail|75567.9100000001 |1 | | |
| |2020-01-02|strong |53850.130000000005|2 | | |
| |2020-01-02|runail |46773.700000000055|3 | | |
| |2020-01-03|jessnail|130618.19000000042|1 | | |
| |2020-01-03|strong |67431.65 |2 | | |
| |2020-01-03|runail |65798.47999999997 |3 | | |
| |2020-01-04|jessnail|77021.25000000009 |1 | | |
| |2020-01-04|strong |72237.20999999993 |2 | | |
| |2020-01-04|runail |55250.03000000005 |3 | | |
| |2020-01-05|jessnail|83268.23000000014 |1 | | |
| |2020-01-05|strong |69062.75999999997 |2 | | |
| |2020-01-05|runail |56429.79000000005 |3 | | |
| |2020-01-06|strong |80781.73999999989 |1 | | |
| |2020-01-06|jessnail|66437.16000000012 |2 | | |
| |2020-01-06|runail |50932.03000000017 |3 | | |
| |2020-01-07|jessnail|76882.80000000008 |1 | | |
| |2020-01-07|strong |74643.85999999997 |2 | | |
| +----------+--------+------------------+----+ |
일별로 가장 많이 팔린 브랜드를 정렬해 Top 3 개의 브랜드를 추출하는 위 Spark SQL 코드를 DataFrame 으로 만들어 봅시다.
3. 전체 기간동안 브랜드별 매출(판매 금액의 합) 을 구하되, 자신보다 한단계 높은 순위 또는 낮은 순위의 매출도 같이 표시하기

Spark SQL 과 Window Function 의 lead(), lag() 함수를 이용하면 다음과 같이 문제를 풀 수 있습니다.
| spark.sql(""" | |
| WITH CALCULATED ( | |
| SELECT | |
| brand, | |
| sum(price) as price_sum | |
| FROM PURCHASE | |
| WHERE | |
| brand IS NOT NULL | |
| GROUP BY brand | |
| ), | |
| RANKED ( | |
| SELECT | |
| brand, | |
| lag(price_sum, 1) OVER (PARTITION BY 1 ORDER BY price_sum DESC) as price_sum_prev, | |
| price_sum as price_sum_current, | |
| lead(price_sum, 1) OVER (PARTITION BY 1 ORDER BY price_sum DESC) as price_sum_next, | |
| dense_rank() OVER (PARTITION BY 1 ORDER BY price_sum DESC) as rank | |
| FROM CALCULATED | |
| ) | |
| SELECT * | |
| FROM RANKED | |
| ORDER BY rank ASC | |
| """).show(truncate=False) |
다음은 실행 결과입니다.
| |brand |price_sum_prev |price_sum_current |price_sum_next |rank| | |
| +---------+------------------+------------------+------------------+----+ | |
| |strong |null |2651513.6799999983|2107905.480000001 |1 | | |
| |jessnail |2651513.6799999983|2107905.480000001 |1877075.9400000153|2 | | |
| |runail |2107905.480000001 |1877075.9400000153|1280128.789999989 |3 | | |
| |irisk |1877075.9400000153|1280128.789999989 |1055984.4699999897|4 | | |
| |grattol |1280128.789999989 |1055984.4699999897|789238.6300000004 |5 | | |
| |marathon |1055984.4699999897|789238.6300000004 |693014.0199999842 |6 | | |
| |masura |789238.6300000004 |693014.0199999842 |599136.3200000003 |7 | | |
| |cnd |693014.0199999842 |599136.3200000003 |546019.0499999991 |8 | | |
| |uno |599136.3200000003 |546019.0499999991 |544323.2499999983 |9 | | |
| |estel |546019.0499999991 |544323.2499999983 |489141.04999999976|10 | | |
| |max |544323.2499999983 |489141.04999999976|427986.93999999884|11 | | |
| |ingarden |489141.04999999976|427986.93999999884|418171.82000000007|12 | | |
| |polarus |427986.93999999884|418171.82000000007|365795.62000000005|13 | | |
| |italwax |418171.82000000007|365795.62000000005|306945.5899999999 |14 | | |
| |browxenna|365795.62000000005|306945.5899999999 |296071.9100000001 |15 | | |
| |emil |306945.5899999999 |296071.9100000001 |293430.7299999994 |16 | | |
| |kapous |296071.9100000001 |293430.7299999994 |293421.13 |17 | | |
| |shik |293430.7299999994 |293421.13 |260097.03000000014|18 | | |
| |jas |293421.13 |260097.03000000014|254294.83999999994|19 | | |
| |kosmekka |260097.03000000014|254294.83999999994|245135.18000000008|20 | | |
| +---------+------------------+------------------+------------------+----+ |
위의 SQL 코드를 DataFrame 으로 변경해봅시다. 또한 rank() 와 dense_rank() 의 차이는 무엇일까요? row_number() 등 다른 함수도 살펴봅시다.
4. 일별로 모든 브랜드를 통틀어, 판매 금액의 합산을 누적으로 구하면 매출의 변화량은 어떤지 살펴보기


Spark SQL 과 Window Function 의 sum() 함수를 이용하면 다음과 같이 문제를 풀 수 있습니다.
| spark.sql(""" | |
| WITH CALCULATED ( | |
| SELECT | |
| CAST(event_time AS DATE) as event_date, | |
| sum(price) as price_sum | |
| FROM PURCHASE | |
| WHERE | |
| brand IS NOT NULL | |
| GROUP BY 1 | |
| ), | |
| RANKED ( | |
| SELECT | |
| event_date, | |
| price_sum, | |
| sum(price_sum) OVER (PARTITION BY 1 ORDER BY event_date RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) as price_acc | |
| FROM CALCULATED | |
| ) | |
| SELECT * | |
| FROM RANKED | |
| ORDER BY event_date ASC | |
| """).show(truncate=False) |
다음은 실행 결과입니다.
| +----------+------------------+--------------------+ | |
| |event_date|price_sum |price_acc | | |
| +----------+------------------+--------------------+ | |
| |2020-01-01|478880.47999999445|478880.47999999445 | | |
| |2020-01-02|591996.0299999958 |1070876.5099999902 | | |
| |2020-01-03|764825.2799999974 |1835701.7899999875 | | |
| |2020-01-04|672783.4599999917 |2508485.249999979 | | |
| |2020-01-05|698293.9199999882 |3206779.1699999673 | | |
| |2020-01-06|648607.0899999944 |3855386.2599999616 | | |
| |2020-01-07|702788.3999999919 |4558174.659999954 | | |
| |2020-01-08|710164.8099999978 |5268339.469999951 | | |
| |2020-01-09|786942.4299999884 |6055281.89999994 | | |
| |2020-01-10|769210.5999999931 |6824492.499999933 | | |
| |2020-01-11|732801.5299999891 |7557294.029999922 | | |
| |2020-01-12|818940.0799999872 |8376234.109999909 | | |
| |2020-01-13|860498.5800000073 |9236732.689999916 | | |
| |2020-01-14|867423.4899999918 |1.0104156179999907E7| | |
| |2020-01-15|858057.1199999887 |1.0962213299999895E7| | |
| |2020-01-16|788017.7599999914 |1.1750231059999887E7| | |
| |2020-01-17|771007.1899999875 |1.2521238249999875E7| | |
| |2020-01-18|714140.5399999954 |1.323537878999987E7 | | |
| |2020-01-19|781291.109999992 |1.4016669899999863E7| | |
| |2020-01-20|849404.3399999914 |1.4866074239999853E7| | |
| +----------+------------------+--------------------+ | |
| only showing top 20 rows |
Window Function 이 돌아갈때의 데이터 흐름을 생각해봅시다.
- Shuffle 이 발생할까요?
- 발생한다면 어떻게 데이터가 나누어지고 집계될까요?
Window Function – Attribution
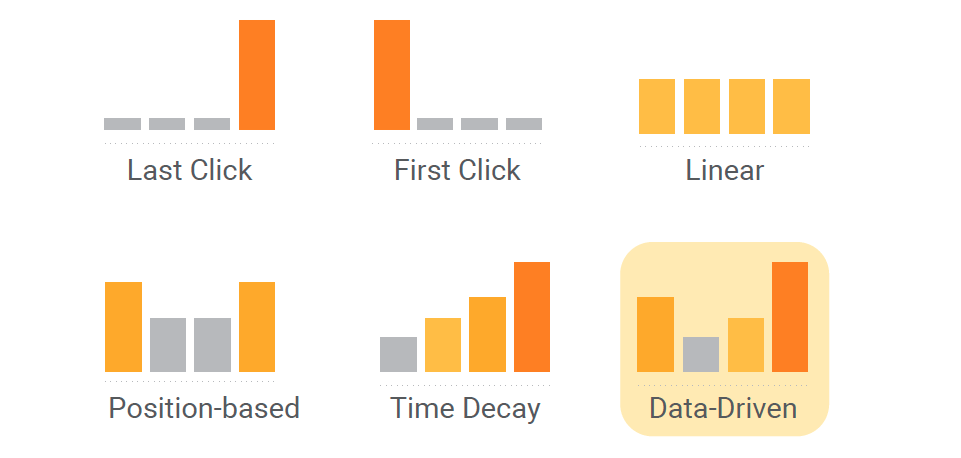
광고 또는 마케팅에는 기여도 (Attribution) 이라는 개념이 있습니다. 광고 또는 마케팅 켐페인을 위해 지불한 비용의 효과를 측정하기 위해, “원하는 Action 을 이끌어낸 것이 내가 돈을 지불한 광고가 맞느냐” 를 판별하기 위한 방법입니다. 다음과 같은 우동마켓의 시나리오를 가정해 봅시다.
- 사용자 A 는 우동마켓 앱 내에서 검색 키워드 K1 (어묵우동) 이후에 상품을 P1, P2, P3 를 탐색합니다.
- 사용자 A 는 검색 키워드 K2 (대파우동) 로 검색을 해 P3, P4, P5 를 탐색합니다.
- 사용자 A 는 어느정도 시간이 지난 후 마음의 결정을 해 상품 P3 를 구매합니다.
이 때, 데이터의 유실이 없고 키워드 검색 이벤트가 상품 클릭 이벤트보다 항상 먼저 들어온다고 가정하면
(A, K1, [P1, P2, P3])(A, K2, [P3, P4, P5])
위 처럼 데이터를 묶어, 아래와 같이 만들어 볼 수 있을 것입니다. 사용자 A 가 P3 를 주문했을때,
- 그 주문을 위해 탐색한 키워드 K1 (Non-last Click간접 기여), K3 (Last Click, 직접 기여)
(A, [K1, K3], P3)
위와 같이 이벤트를 Window 함수로 묶어 K1, K3 가 사용자 A 의 상품 주문 P3 에 기여했음을 만들 수 있지 않을까요? Spark Window Function 에서 제공되는 다음의 함수를 통해 어떻게 Attribution 데이터를 가공할지 생각해 봅시다.
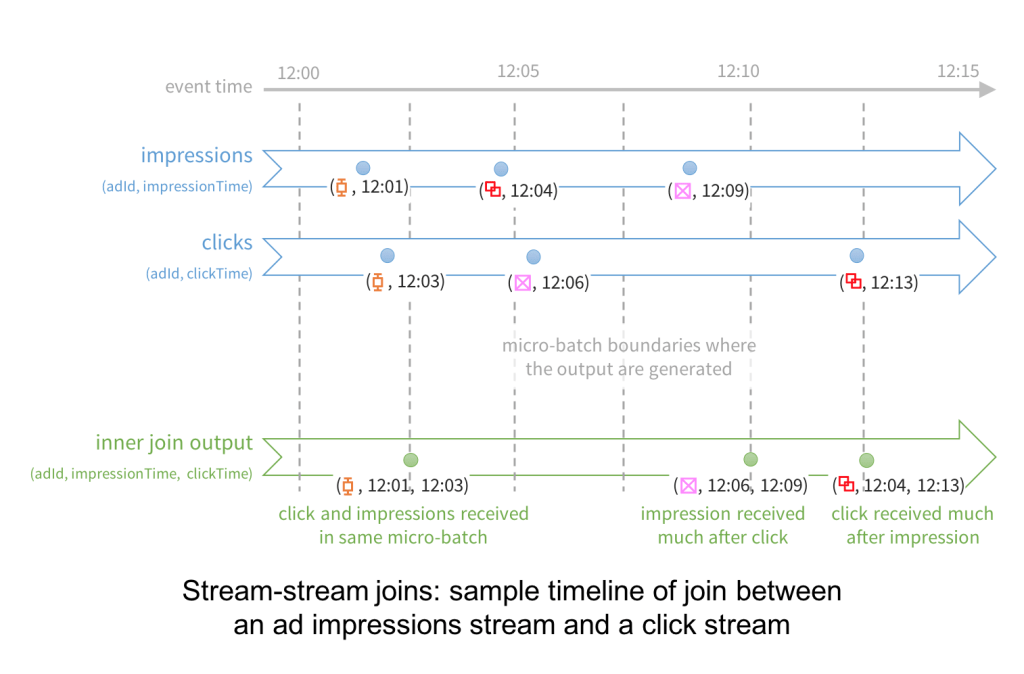
만약 배치가 아니라 실시간으로 Attribution 을 계산해야 한다면 어떤 제약이 있을까요?사용자가 상품을 본 뒤로 최대 몇시간까지 기다려야 할지 논의해 봅시다.
Window Function – Session
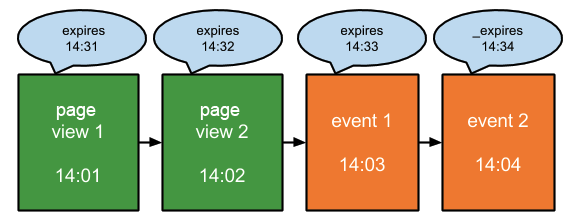
데이터 분석에는 일반적으로 Session 이라는 개념이 자주 사용됩니다. 동일한 사용자라도, 특정 시점에는 특정 상품에 관심이 있다는 이론을 바탕으로 사용자를 지정된 ‘시간’ 단위로 나눌 수 있습니다.
예를 들어 Google Analytics (GA) 에서는 시간 기반으로 세션을 나눌때, 활동이 없을 경우 30 분이 지나면 새로운 세션으로 구분됩니다.
위 그림에서 사용자는 14:04 가 마지막 이벤트라고 가정하면, 14:35 에 다시 이벤트가 발생했을 때 다른 세션 ID 를 발급 받습니다.
- User A, Session 1 이벤트: 14:04 까지
- User B, Session 2 이벤트: 14:35 부터 발생하는 이벤트
만약 ecommerce_event 데이터 셋을 이용해 세션을 만든다면, Window 함수를 어떻게 사용할 수 있을까요? 다음 문서를 참조해 봅시다.
구현에 참조할 만한 몇 가지 아이디어는 다음과 같습니다.
- Window Function 중 Lag 는, 현재 집합 (Window) 에 대해 이전의 값을 현재 컬럼에 붙일 수 있습니다.
- event_time – Lag(event_time) > Threshold
Spark 는 Session 생성을 위한 Window 함수를 제공하기도 합니다. 직접 만들어 보았다면, 이 함수를 이용해서 구현해봅시다.
Array Type and Unnest
SQL 에서 함수의 적용 대상은 date_to(event_time) 와 같이 일반적으로 Column 입니다. 그러나 경우에 따라 Array (배열) 를 취급해야 하는 경우가 있습니다.
- 원본 데이터가 배열을 담고 있어 풀어 헤친 뒤 (Explode) 작업을 하거나
- 아니면 Array 타입의 컬럼 그대로 array_contains 와 같은 연산을 수행할 수도 있습니다.
이번 섹션에서는 ecommerce_event 데이터를 바탕으로 Array 연산을 알아보겠습니다.
- Deep Dive into Apache Spark Array Functions 문서에서 기본적인 사용법을 파악하거나
- Spark SQL Functions 문서에서 Array 함수를 찾아볼 수 있습니다
데이터가 지금은 펼쳐진 상태이기에 몇몇 컬럼을 Array 타입으로 변경해보겠습니다. 브랜드별로 판매하는 product_id 를 배열로 묶어 하나의 컬럼으로 만들어 보면 다음과 같습니다.
| df\ | |
| .where(col("brand").isNotNull())\ | |
| .groupBy("brand")\ | |
| .agg( | |
| collect_list("product_id").alias("product_id_list"), | |
| size(collect_list("product_id")).alias("product_id_list_count"), | |
| collect_set("product_id").alias("product_id_set"), | |
| size(collect_set("product_id")).alias("product_id_set_count"), | |
| )\ | |
| .show() |
| +------------+--------------------+---------------------+--------------------+--------------------+ | |
| | brand| product_id_list|product_id_list_count| product_id_set|product_id_set_count| | |
| +------------+--------------------+---------------------+--------------------+--------------------+ | |
| | beautix|[5862589, 5722999...| 19861|[5885135, 5706318...| 316| | |
| | dr.gloderm|[5875651, 5875661...| 578|[5875646, 5865200...| 31| | |
| | farmona|[5685354, 5685382...| 1484|[5685353, 5685348...| 46| | |
| | profhenna|[5853441, 5853441...| 1531|[5853440, 5853419...| 56| | |
| |invisibobble| [5597144, 5712776]| 2| [5712776, 5597144]| 2| | |
| | riche|[5842213, 5842221...| 758|[5922120, 5842233...| 58| | |
| | nova| [5755588]| 1| [5755588]| 1| | |
| | oniq|[5884364, 5884359...| 24010|[5884342, 5834400...| 592| | |
| | lebelage|[5830804, 5830809...| 714|[5866297, 5830820...| 45| | |
| | vilenta|[5840375, 5840374...| 851|[5840374, 5840410...| 20| | |
| | fancy|[5810171, 5810177...| 287|[5810175, 5817137...| 15| | |
| | jaguar|[5809118, 5809118...| 1991|[5712807, 5712808...| 22| | |
| | siberina|[5870946, 5914135...| 2392|[5914135, 5869563...| 181| | |
| | tertio|[5865103, 5780729...| 1179|[5780317, 5771070...| 115| | |
| | koreatida|[5868794, 5868794...| 119|[5868794, 5868792...| 3| | |
| | jas|[5862545, 5862544...| 5882|[5862544, 5618277...| 16| | |
| |rocknailstar|[5683806, 5683806...| 11|[5629064, 5630048...| 6| | |
| | depilflax|[24390, 24390, 24...| 5651|[36210, 82960, 24...| 64| | |
| |protokeratin|[5856625, 5856574...| 579|[5856533, 5856483...| 70| | |
| | relouis|[5916864, 5916864...| 6234|[5916494, 5916617...| 94| | |
| +------------+--------------------+---------------------+--------------------+--------------------+ |
만약 위의 DataFrame 계산을 SQL 로 바꾸면 어떻게 될까요? 한번 변경해 봅시다.
collect_list() 함수에서는 Executor 가 2개 이상일 경우 분산처리를 수행할 수 있으므로 순서가 보존되지 않을 수 있습니다. collect_list 에서 순서를 보존하기 호출 전 row_number 등을 호출하고 UDF 를 이용하거나, 값을 기준으로 정렬한다면 sort_array() 함수를 이용해 순서를 정렬할 수 있습니다.
Spark DataFrame 은 다양한 Array 함수를 제공합니다. 이름을 보고 어떤 역할을 할지 유추해본 뒤에, Spark 문서를 읽으며 확인해 봅시다.
- Spark Docs – 전체 목록
- array_contains
- array_distinct
- array_except
- array_intersect
- array_join
- array_max
- array_min
- array_position
- array_remove
- array_repeat
- array_sort
- array_union
- array_overlap
- array_zip
- concat
- element_at
- flatten
- slice
- explode
- posexplode
이제 전체 브랜드에서 일별로 판매된 상품의 ID 를 중복 제거해 배열로 만들어 보겠습니다. 그리고 추후 분석을 위해 category_id, category_code 컬럼을 묶으면 아래와 같습니다.
| df\ | |
| .selectExpr("CAST(event_time AS DATE) as event_date", "brand", "product_id", "ARRAY(category_code, category_id) as category")\ | |
| .where( | |
| col("brand").isNotNull() & | |
| ((col("category_code").isNotNull())) | |
| )\ | |
| .groupBy("event_date")\ | |
| .agg( | |
| collect_set("product_id").alias("product_id_set"), | |
| collect_set("category").alias("category_set") | |
| )\ | |
| .orderBy(asc("event_date"))\ | |
| .limit(1)\ | |
| .show(truncate=False) |
| +----------+--------------------+--------------------+ | |
| |event_date| product_id_set| category_set| | |
| +----------+--------------------+--------------------+ | |
| |2020-01-01|[5911195, 5901859...|[[furniture.bathr...| | |
| |2020-01-02|[5911195, 5901859...|[[furniture.bathr...| | |
| |2020-01-03|[5911195, 5901859...|[[furniture.bathr...| | |
| |2020-01-04|[5911195, 5901859...|[[furniture.bathr...| | |
| |2020-01-05|[5911195, 5901859...|[[appliances.envi...| | |
| |2020-01-06|[5911195, 5901859...|[[appliances.envi...| | |
| |2020-01-07|[5911195, 5901859...|[[furniture.bathr...| | |
| |2020-01-08|[5911195, 5901859...|[[furniture.bathr...| | |
| |2020-01-09|[5911195, 5901859...|[[furniture.bathr...| | |
| |2020-01-10|[5911195, 5901859...|[[appliances.envi...| | |
| |2020-01-11|[5911195, 5901859...|[[appliances.envi...| | |
| |2020-01-12|[5911195, 5901859...|[[appliances.envi...| | |
| |2020-01-13|[5911195, 5807068...|[[appliances.envi...| | |
| |2020-01-14|[5911195, 5901859...|[[furniture.bathr...| | |
| |2020-01-15|[5911195, 5901859...|[[furniture.bathr...| | |
| |2020-01-16|[5911195, 5889693...|[[appliances.envi...| | |
| |2020-01-17|[5911195, 5889693...|[[furniture.bathr...| | |
| |2020-01-18|[5911195, 5889693...|[[furniture.bathr...| | |
| |2020-01-19|[5911195, 5901859...|[[appliances.envi...| | |
| |2020-01-20|[5911195, 5901859...|[[appliances.envi...| | |
| +----------+--------------------+--------------------+ | |
| # event_date | |
| 2020-01-01 | |
| # product_id | |
| [5911195, 5901859, 5810081, 5914941, 5788783, 5889695, 5854574, 5767493, 5896431, 5665819, 5712700, 5885587, 24336, 5712694, 5901857, 5746974, 5835254, 5873430, 5820598, 5855509, 5873432, 5395, 5904212, 5856192, 5835931, 5877461, 5847851, 5749198, 5796100, 5753706, 5675830, 5809792, 5803579, 5915204, 24330, 5861762, 5884578, 5880245, 5825604, 5889696, 5767494, 5885596, 5824088, 5823936, 5861764, 5884580, 5854579, 5848272, 5885592, 5914105, 5810082, 5907080, 5901862, 5901854, 5809118, 5810084, 5746848, 5665820, 5855512, 5863222, 5820603, 5712695, 5830789, 5901858, 5914940, 5873431, 5788782, 5856191, 5712516, 5746846, 5855510, 24335, 5861767, 5835932, 55717, 5796101, 5824195, 5901869, 5885595, 5861763, 5823935, 5775813, 5884579, 5885291, 5732026, 5868559, 5885589, 5787829, 5901988, 5766983, 5901861, 82962, 5902675, 5810083, 5855511, 5856194, 5901855, 5665821, 5820604, 5766981, 5775822, 5855507, 5877459, 5788781, 5765551, 5907079, 24334, 5861766, 5771614, 5823938, 5856184, 5892336, 5830786, 5891197, 5796102, 5873428, 5743974, 5901870, 5775814, 5885588, 5901872, 5867188, 5885590, 5888124, 5861098, 82959, 5861760, 5753698, 5889694, 5767492, 5914107, 5885586, 5892330, 5913318, 5901987, 5889690, 5766980, 5835253, 24331, 5712697, 5855508, 5861765, 5854573, 5765552, 5901852, 5877462, 5847852, 5856193, 5830785, 5749199, 5848273, 5885593, 5861761, 5892337, 5884577, 5796103, 5877529, 5798933, 5825605, 5896187, 5759489, 5829359, 5823937, 5915788, 5884581, 5846774, 5753703, 5892335] | |
| # [category_code, category_id] | |
| [[furniture.bathroom.bath, 1487580011970953351], [furniture.living_room.cabinet, 2193074740619379535], [furniture.bathroom.bath, 2018287324474901238], [appliances.personal.hair_cutter, 1487580008070251489], [appliances.environment.vacuum, 1487580006350586771], [accessories.bag, 1487580010695884882], [accessories.cosmetic_bag, 1921723506584715388], [furniture.bathroom.bath, 2193074740686488401], [furniture.bathroom.bath, 1487580012147114126], [apparel.glove, 1487580012071616651], [apparel.glove, 2007399943458784057], [stationery.cartrige, 1487580013053083824]] |
일반적으로는 상품의 구매 이력 (트랜잭션 또는 이벤트) 상품의 정보 (Category 등 메타) 정보는 분리된 테이블로 존재합니다.
- 상품 메타 테이블에서 상품의 product_id 를 기반으로 category_id 와 category_code 를 가져오고
- 상품 구매 이력 테이블에서 어떤 user_id 가 어느 product_id 를 구매했는지를 파악한 뒤
- 두 가지 테이블을 조인해 분석할 수 있습니다.
다만 위의 예제에서는, array 함수의 연습을 위해 위와 같이 상품의 구매 이력과 상품의 메타 정보를 컬럼으로 동봉해 하나의 DataFrame (= Table, CSV File) 처럼 만들었습니다.
- 이 경우 장점은 하나의 파일에서 모든것을 해결할 수 있지만
- 단점으로는 이 데이터를 분석하는 사용자가 어떤 상품 목록이 있는지 (product_id), 어떤 카테고리가 있는지 (category_id, category_type) 컬럼을 풀어 헤쳐 전부 살펴봐야 한다는점에 있습니다.
실제로는 메타정보가 본인의 회사 내에 없는 경우 (외부 데이터 또는 이벤트만 받아 카테고리를 다시 빌드해야 하는) 많이 사용되는 패턴입니다.
Window 함수와 array_intersect 를 사용해서 일별로 beautix 에서 전날과 비교했을때 당일에 팔린 상품의 중복이 많았는지 살펴보려면 어떻게 해야할까요? SQL 함수를 이용해서 작성해봅시다. 아래는 몇 가지 힌트입니다.
- WHERE brand = “beautix”
- GROUP BY
- SELECT
- CAST(event_time AS DATE) as event_date
- collect_set(product_id) as products
- array_intersect(products_current, products_prev) as products_common
| spark.sql(""" | |
| WITH GROUPED as ( | |
| SELECT CAST(event_time AS DATE) as event_date, collect_set(product_id) as product_id_list | |
| FROM PURCHASE | |
| WHERE brand = "beautix" | |
| GROUP BY event_date | |
| ), | |
| WINDOWED as ( | |
| SELECT | |
| event_date, | |
| product_id_list as products_current, | |
| lag(product_id_list, 1) OVER (PARTITION BY 1 ORDER BY event_date ASC) as products_prev | |
| FROM GROUPED | |
| ), | |
| CALCULATED as ( | |
| SELECT | |
| event_date, | |
| products_current, | |
| products_prev, | |
| array_intersect(products_current, products_prev) as products_common, | |
| size(array_intersect(products_current, products_prev)) as products_common_size | |
| FROM WINDOWED | |
| ) | |
| SELECT * | |
| FROM CALCULATED | |
| ORDER BY event_date ASC | |
| """).show() |
| +----------+--------------------+--------------------+--------------------+--------------------+ | |
| |event_date| products_current| products_prev| products_common|products_common_size| | |
| +----------+--------------------+--------------------+--------------------+--------------------+ | |
| |2020-01-01|[5885135, 5842741...| null| null| -1| | |
| |2020-01-02|[5842741, 5706333...|[5885135, 5842741...|[5842741, 5706333...| 63| | |
| |2020-01-03|[5706333, 5733063...|[5842741, 5706333...|[5706333, 5733063...| 72| | |
| |2020-01-04|[5842741, 5842712...|[5706333, 5733063...|[5706333, 5733063...| 73| | |
| |2020-01-05|[5842712, 5862588...|[5842741, 5842712...|[5842712, 5862588...| 72| | |
| |2020-01-06|[5706114, 5885135...|[5842712, 5862588...|[5842712, 5714043...| 88| | |
| |2020-01-07|[5706114, 5842741...|[5706114, 5885135...|[5706114, 5733063...| 97| | |
| |2020-01-08|[5842741, 5842706...|[5706114, 5842741...|[5842741, 5842706...| 84| | |
| |2020-01-09|[5706114, 5885135...|[5842741, 5842706...|[5842706, 5912890...| 89| | |
| |2020-01-10|[5706114, 5862588...|[5706114, 5885135...|[5706114, 5714043...| 106| | |
| |2020-01-11|[5842741, 5862588...|[5706114, 5862588...|[5862588, 5714043...| 106| | |
| |2020-01-12|[5885135, 5842741...|[5842741, 5862588...|[5842741, 5862588...| 102| | |
| |2020-01-13|[5706114, 5842741...|[5885135, 5842741...|[5842741, 5862588...| 127| | |
| |2020-01-14|[5733067, 5862588...|[5706114, 5842741...|[5733067, 5862588...| 117| | |
| |2020-01-15|[5706114, 5842741...|[5733067, 5862588...|[5862588, 5714043...| 116| | |
| |2020-01-16|[5862588, 5706333...|[5706114, 5842741...|[5862588, 5706333...| 123| | |
| |2020-01-17|[5706114, 5862588...|[5862588, 5706333...|[5862588, 5842706...| 96| | |
| |2020-01-18|[5706114, 5885135...|[5706114, 5862588...|[5706114, 5862588...| 86| | |
| |2020-01-19|[5885135, 5842741...|[5706114, 5885135...|[5885135, 5842741...| 90| | |
| |2020-01-20|[5885135, 5862588...|[5885135, 5842741...|[5885135, 5862588...| 112| | |
| +----------+--------------------+--------------------+--------------------+--------------------+ |
이제 마지막으로 explode 함수에 대해서 알아봅시다. 이 함수는 배열 타입의 컬럼을 뻥튀기해 1 Row 를 N 개의 Row 로 만들 수 있습니다.
아까 만들어 두었던 브랜드별 상품 및 카테고리 메타 데이터를 별도 DataFrame 으로 저장하면 다음과 같습니다.
| dfRaw = df\ | |
| .selectExpr("CAST(event_time AS DATE) as event_date", "brand", "product_id", "ARRAY(category_code, category_id) as category")\ | |
| .where( | |
| col("brand").isNotNull() & | |
| ((col("category_code").isNotNull())) | |
| )\ | |
| .groupBy("event_date")\ | |
| .agg( | |
| collect_set("product_id").alias("product_id_set"), | |
| collect_set("category").alias("category_set") | |
| ) | |
| dfRaw.printSchema() |
| root | |
| |-- event_date: date (nullable = true) | |
| |-- product_id_set: array (nullable = false) | |
| | |-- element: integer (containsNull = false) | |
| |-- category_set: array (nullable = false) | |
| | |-- element: array (containsNull = false) | |
| | | |-- element: string (containsNull = true) |
Explode 시 배열 컬럼 내 순서를 보존하려면 어떻게 해야할까요?
- posexplode 함수를 살펴봅시다.
위에서 만든 결과 DataFrame 내에서 product_id, category_id, category_code 를 추출해 상품 정보 데이터를 만들어 보겠습니다.
| dfRaw\ | |
| .withColumn("product_id", explode(col("product_id_set")))\ | |
| .withColumn("category_element", explode(col("category_set")))\ | |
| .withColumn("category_code", element_at(col("category_element"), 1))\ | |
| .withColumn("category_id", element_at(col("category_element"), 2))\ | |
| .select("product_id", "category_code", "category_id")\ | |
| .show(truncate=False) |
| +----------+-------------------------------+-------------------+ | |
| |product_id|category_code |category_id | | |
| +----------+-------------------------------+-------------------+ | |
| |5911195 |furniture.bathroom.bath |1487580011970953351| | |
| |5911195 |furniture.living_room.cabinet |2193074740619379535| | |
| |5911195 |furniture.bathroom.bath |2018287324474901238| | |
| |5911195 |accessories.cosmetic_bag |1921723506584715388| | |
| |5911195 |appliances.environment.vacuum |1487580006350586771| | |
| |5911195 |accessories.bag |1487580010695884882| | |
| |5911195 |appliances.personal.hair_cutter|1487580008070251489| | |
| |5911195 |furniture.bathroom.bath |2193074740686488401| | |
| |5911195 |furniture.bathroom.bath |1487580012147114126| | |
| |5911195 |apparel.glove |1487580012071616651| | |
| |5911195 |apparel.glove |2007399943458784057| | |
| |5911195 |stationery.cartrige |1487580013053083824| | |
| |5901859 |furniture.bathroom.bath |1487580011970953351| | |
| |5901859 |furniture.living_room.cabinet |2193074740619379535| | |
| |5901859 |furniture.bathroom.bath |2018287324474901238| | |
| |5901859 |accessories.cosmetic_bag |1921723506584715388| | |
| |5901859 |appliances.environment.vacuum |1487580006350586771| | |
| |5901859 |accessories.bag |1487580010695884882| | |
| |5901859 |appliances.personal.hair_cutter|1487580008070251489| | |
| |5901859 |furniture.bathroom.bath |2193074740686488401| | |
| +----------+-------------------------------+-------------------+ |
이렇게 한 Row 를 뻥튀기해 여러 Row 로 만드는 것을 Unnest, Explode 라고 부릅니다. 쿼리 엔진마다 이름이 조금씩 다르긴 하나, 대부분의 데이터 처리 엔진이 Unnest 함수를 지원합니다.
왜 이러한 Unnest / Explode 함수가 필요할까요? 다음 경우를 생각해봅시다. 커머스 내에서 상품의 노출 / 클릭은 추천, 검색, 광고 등 성과에 중요한 지표입니다.
- 노출의 경우 스크롤을 조금만 해도 수십개의 Impression Event 가 발생할 수 있습니다
- 다만 Client (App / Web) 의 퍼포먼스를 위해서 수십개의 Impression Event 를 전송하기보다는,
- 다른 컬럼은 거의 동일하니 상품 번호만 다르게 해 서버로 또는 Kinesis 등으로 전송할 수 있습니다
(event_time, product_id_list, app_version, user_id) 이 때, product_id_list 값을 펼쳐 사용자가 사용하기 쉽게 만들려면 어떻게 해야할까요?
Json Function and Struct Type
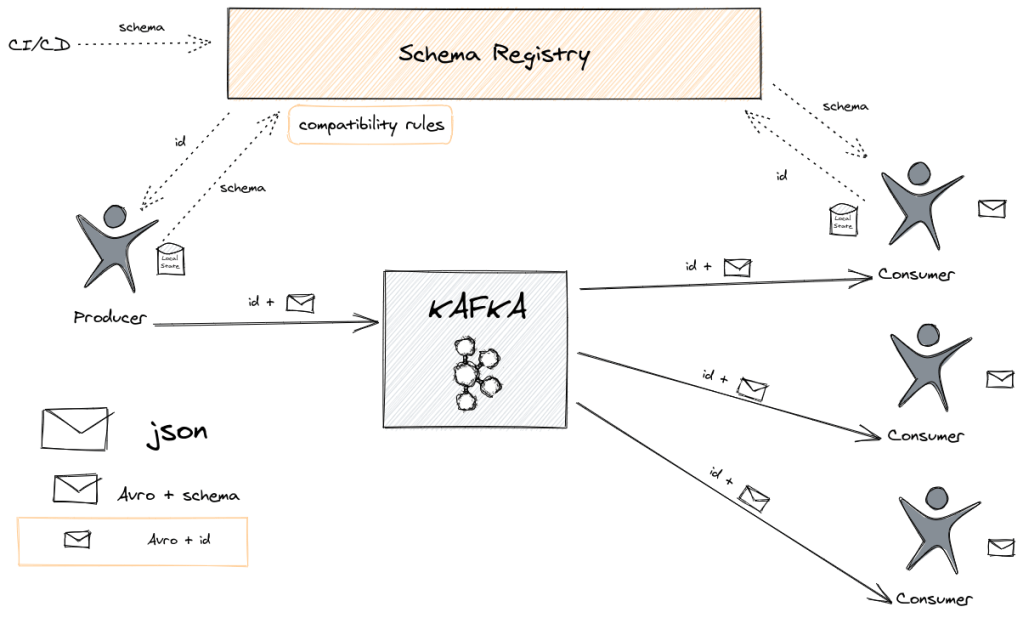
DB 를 다루는 경우에는 테이블 다루므로 대부분 정형화된 데이터입니다. 최근에는 RDB 에서 JSON 컬럼 타입도 지원하나, 일반적인 경우 서비스에서 자주 사용하진 않으므로 DB 데이터를 다루면서 JSON 타입을 만날 일은 적습니다.
그러나 Kafka 또는 Kinesis 로 전송되는 Client (App / Web) 또는 Server 이벤트의 경우 JSON 인 경우가 종종 있습니다.
- Kinesis 등 받아주는 Queue 시스템의 제한이나, 사용성등의 이유로 사이즈를 포기하고 JSON 으로 전송될 수 있습니다.
- 혹은 원본 포맷 자체는 ProtoBuf, Avro 등으로 관리된다 하더라도 Relay 시에 가공 용이성을 이유로 JSON 으로 다른 브로커로 데이터가 변경될 수 있습니다.
물론 당연히 ProtoBuf, Avro 등 포맷을 유지하는것이 Consumer 입장에서 일부 비용을 희생해 (CPU 등) 강한 타입, 메세지 호환성 등 많은 장점을 얻을 수 있습니다.다만 이 섹션에서는 JSON 으로 들어오는 경우를 가정해 Spark DataFrame 의 JSON 함수를 이용해 데이터를 다루어 봅니다.
JSON 의 장점은, 복잡한 Structure Type 을 생산자가 별 노동 없이 Write 하고, 소비자도 별 노동 없이 당장은 Read 수 있다는 장점이 있습니다.문제는 오늘 들어오는 데이터의 타입이 그렇다고 하더라도, 자유롭게 변하므로 미래에도 그럴지는 알 수 없는것입니다. JSON 함수를 사용해 데이터를 가공해 보겠습니다.
- from_json 함수는 문자열 컬럼과 타입을 파라미터로 받아, 데이터 값 내 JSON (문자열) 을 타입으로 변경합니다.
- to_json 함수는 컬럼을 받아, 타입이 있는 데이터 값을 JSON (문자열) 으로 변경합니다.
우선 현재 가진 데이터의 타입을 다시 살펴보고, to_json 을 JSON 컬럼으로 변경해보겠습니다.
| df.printSchema() | |
| root | |
| |-- event_time: string (nullable = true) | |
| |-- event_type: string (nullable = true) | |
| |-- product_id: integer (nullable = true) | |
| |-- category_id: long (nullable = true) | |
| |-- category_code: string (nullable = true) | |
| |-- brand: string (nullable = true) | |
| |-- price: double (nullable = true) | |
| |-- user_id: integer (nullable = true) | |
| |-- user_session: string (nullable = true) |
다른 값은 그대로 두고 brand, product_id, category_code, category_id 만 남겨 JSON 으로 변경 해보겠습니다. 단. 이 때 다른 컬럼이 없어지면 중복이 있을 수 있으므로 dropDuplicates() 를 통해 중복을 제거하겠습니다.
중복을 제거하는 과정을 떠올려보고, 얼마만큼의 메모리가 필요할지 한번 생각해 봅시다.
- 중복 제거는 분산처리를 할 수 있는 연산일까요?
- Unique Count 를 세는것과 중복을 제거하는 연산의 차이점을 이야기 해봅시다.
| dfPrepared = df\ | |
| .select("brand", "product_id", "category_code", "category_id")\ | |
| .dropDuplicates() | |
| dfPrepared.show() |
| +---------+----------+-------------+-------------------+ | |
| | brand|product_id|category_code| category_id| | |
| +---------+----------+-------------+-------------------+ | |
| | null| 5847345| null|1487580005092295511| | |
| | null| 5700094| null|1487580011652186237| | |
| | null| 5608703| null|1487580005553668971| | |
| | null| 5561084| null|1487580005595612013| | |
| | null| 5683960| null|1487580005268456287| | |
| | null| 5886759| null|1487580006317032337| | |
| | runail| 4958| null|1487580009471148064| | |
| | nagaraku| 5847810| null|1487580013522845895| | |
| | irisk| 5729898| null|1487580008145748965| | |
| | staleks| 5899158| null|1487580009286598681| | |
| | bluesky| 5804328| null|1487580005461394279| |
count() 함수를 이용해 DataFrame 의 Row 숫자를 세보면 중복이 제거되었음을 알 수 있습니다.
- dropDuplicates() 함수는 파라미터로 컬럼 이름을 받을 수 있습니다.
- 위의 예제에서는 컬럼이름이 없기 때문에 전체 컬럼을 대상으로 중복을 제거합니다.
이제 to_json 으로 DataFrame 내 JSON 컬럼을 추가해보겠습니다.
| dfJson = dfPrepared\ | |
| .where(col("category_code").isNotNull())\ | |
| .withColumn("category", to_json(struct(col("category_id"), col("category_code"))))\ | |
| dfJson.printSchema() | |
| dfJson.show(truncate=False) |
| root | |
| |-- brand: string (nullable = true) | |
| |-- product_id: integer (nullable = true) | |
| |-- category_code: string (nullable = true) | |
| |-- category_id: long (nullable = true) | |
| |-- category: string (nullable = true) | |
| +--------+----------+-------------------------------+-------------------+-------------------------------------------------------------------------------------+ | |
| |brand |product_id|category_code |category_id |category | | |
| +--------+----------+-------------------------------+-------------------+-------------------------------------------------------------------------------------+ | |
| |null |5902332 |apparel.glove |2007399943458784057|{"category_id":2007399943458784057,"category_code":"apparel.glove"} | | |
| |null |5571162 |furniture.bathroom.bath |1487580012147114126|{"category_id":1487580012147114126,"category_code":"furniture.bathroom.bath"} | | |
| |benovy |5911195 |apparel.glove |2007399943458784057|{"category_id":2007399943458784057,"category_code":"apparel.glove"} | | |
| |null |5756536 |apparel.glove |2007399943458784057|{"category_id":2007399943458784057,"category_code":"apparel.glove"} | | |
| |emil |5861764 |appliances.environment.vacuum |1487580006350586771|{"category_id":1487580006350586771,"category_code":"appliances.environment.vacuum"} | | |
| |shik |5914940 |accessories.cosmetic_bag |1921723506584715388|{"category_id":1921723506584715388,"category_code":"accessories.cosmetic_bag"} | | |
| |italwax |5775813 |stationery.cartrige |1487580013053083824|{"category_id":1487580013053083824,"category_code":"stationery.cartrige"} | | |
| |null |5923808 |appliances.personal.hair_cutter|1487580008070251489|{"category_id":1487580008070251489,"category_code":"appliances.personal.hair_cutter"}| | |
| |null |5856308 |furniture.living_room.chair |2022622168218599898|{"category_id":2022622168218599898,"category_code":"furniture.living_room.chair"} | | |
| |max |5855509 |appliances.environment.vacuum |1487580006350586771|{"category_id":1487580006350586771,"category_code":"appliances.environment.vacuum"} | | |
| |null |5813075 |furniture.bathroom.bath |1487580011970953351|{"category_id":1487580011970953351,"category_code":"furniture.bathroom.bath"} | | |
| |benovy |5901872 |apparel.glove |2007399943458784057|{"category_id":2007399943458784057,"category_code":"apparel.glove"} | | |
| |null |5912860 |furniture.bathroom.bath |2018287324474901238|{"category_id":2018287324474901238,"category_code":"furniture.bathroom.bath"} | | |
| |nitrile |5889686 |apparel.glove |2007399943458784057|{"category_id":2007399943458784057,"category_code":"apparel.glove"} | | |
| |null |5913116 |furniture.bathroom.bath |2018287324474901238|{"category_id":2018287324474901238,"category_code":"furniture.bathroom.bath"} | | |
| |null |5713291 |appliances.personal.hair_cutter|1487580008070251489|{"category_id":1487580008070251489,"category_code":"appliances.personal.hair_cutter"}| | |
| |null |5657896 |stationery.cartrige |1487580013053083824|{"category_id":1487580013053083824,"category_code":"stationery.cartrige"} | | |
| |jessnail|5877460 |appliances.environment.vacuum |1487580006350586771|{"category_id":1487580006350586771,"category_code":"appliances.environment.vacuum"} | | |
| |vosev |5904212 |accessories.bag |1487580010695884882|{"category_id":1487580010695884882,"category_code":"accessories.bag"} | | |
| |kinetics|5829359 |furniture.bathroom.bath |1487580011970953351|{"category_id":1487580011970953351,"category_code":"furniture.bathroom.bath"} | | |
| +--------+----------+-------------------------------+-------------------+-------------------------------------------------------------------------------------+ |
dfJson.printSchema() 에서 볼 수 있듯이 category 컬럼은 String 타입의 문자열이되, JSON 형식을 가지고 있습니다.이제 dfJson 에서 category_code, category_id 컬럼을 제거하고 category 컬럼을 바탕으로 JSON 함수를 이용해 category_code, category_id 값을 다시 만들어 봅시다.
| dfCategory = dfJson.select("brand", "product_id", "category") | |
| dfCategory.show(truncate=False) |
| +--------+----------+-------------------------------------------------------------------------------------+ | |
| |brand |product_id|category | | |
| +--------+----------+-------------------------------------------------------------------------------------+ | |
| |null |5902332 |{"category_id":2007399943458784057,"category_code":"apparel.glove"} | | |
| |null |5571162 |{"category_id":1487580012147114126,"category_code":"furniture.bathroom.bath"} | | |
| |benovy |5911195 |{"category_id":2007399943458784057,"category_code":"apparel.glove"} | | |
| |null |5756536 |{"category_id":2007399943458784057,"category_code":"apparel.glove"} | | |
| |emil |5861764 |{"category_id":1487580006350586771,"category_code":"appliances.environment.vacuum"} | | |
| |shik |5914940 |{"category_id":1921723506584715388,"category_code":"accessories.cosmetic_bag"} | | |
| |italwax |5775813 |{"category_id":1487580013053083824,"category_code":"stationery.cartrige"} | |
get_json_object 함수를 이용하면 JSON 형식의 문자열에서 원하는 내부 필드를 추출할 수 있습니다.
| dfRecovered = dfCategory\ | |
| .withColumn("category_id", get_json_object(col("category"), "$.category_id"))\ | |
| .withColumn("category_code", get_json_object(col("category"), "$.category_code")) | |
| dfRecovered.printSchema() | |
| dfRecovered.show(truncate=False) |
| root | |
| |-- brand: string (nullable = true) | |
| |-- product_id: integer (nullable = true) | |
| |-- category: string (nullable = true) | |
| |-- category_id: string (nullable = true) | |
| |-- category_code: string (nullable = true) | |
| +--------+----------+-------------------------------------------------------------------------------------+-------------------+-------------------------------+ | |
| |brand |product_id|category |category_id |category_code | | |
| +--------+----------+-------------------------------------------------------------------------------------+-------------------+-------------------------------+ | |
| |null |5902332 |{"category_id":2007399943458784057,"category_code":"apparel.glove"} |2007399943458784057|apparel.glove | | |
| |null |5571162 |{"category_id":1487580012147114126,"category_code":"furniture.bathroom.bath"} |1487580012147114126|furniture.bathroom.bath | | |
| |benovy |5911195 |{"category_id":2007399943458784057,"category_code":"apparel.glove"} |2007399943458784057|apparel.glove | | |
| |null |5756536 |{"category_id":2007399943458784057,"category_code":"apparel.glove"} |2007399943458784057|apparel.glove | | |
| |emil |5861764 |{"category_id":1487580006350586771,"category_code":"appliances.environment.vacuum"} |1487580006350586771|appliances.environment.vacuum | | |
| |shik |5914940 |{"category_id":1921723506584715388,"category_code":"accessories.cosmetic_bag"} |1921723506584715388|accessories.cosmetic_bag | | |
| |italwax |5775813 |{"category_id":1487580013053083824,"category_code":"stationery.cartrige"} |1487580013053083824|stationery.cartrige | | |
| |null |5923808 |{"category_id":1487580008070251489,"category_code":"appliances.personal.hair_cutter"}|1487580008070251489|appliances.personal.hair_cutter| | |
| |null |5856308 |{"category_id":2022622168218599898,"category_code":"furniture.living_room.chair"} |2022622168218599898|furniture.living_room.chair | | |
| |max |5855509 |{"category_id":1487580006350586771,"category_code":"appliances.environment.vacuum"} |1487580006350586771|appliances.environment.vacuum | | |
| |null |5813075 |{"category_id":1487580011970953351,"category_code":"furniture.bathroom.bath"} |1487580011970953351|furniture.bathroom.bath | | |
| |benovy |5901872 |{"category_id":2007399943458784057,"category_code":"apparel.glove"} |2007399943458784057|apparel.glove | | |
| |null |5912860 |{"category_id":2018287324474901238,"category_code":"furniture.bathroom.bath"} |2018287324474901238|furniture.bathroom.bath | | |
| |nitrile |5889686 |{"category_id":2007399943458784057,"category_code":"apparel.glove"} |2007399943458784057|apparel.glove | | |
| |null |5913116 |{"category_id":2018287324474901238,"category_code":"furniture.bathroom.bath"} |2018287324474901238|furniture.bathroom.bath | | |
| |null |5713291 |{"category_id":1487580008070251489,"category_code":"appliances.personal.hair_cutter"}|1487580008070251489|appliances.personal.hair_cutter| | |
| |null |5657896 |{"category_id":1487580013053083824,"category_code":"stationery.cartrige"} |1487580013053083824|stationery.cartrige | | |
| |jessnail|5877460 |{"category_id":1487580006350586771,"category_code":"appliances.environment.vacuum"} |1487580006350586771|appliances.environment.vacuum | | |
| |vosev |5904212 |{"category_id":1487580010695884882,"category_code":"accessories.bag"} |1487580010695884882|accessories.bag | | |
| |kinetics|5829359 |{"category_id":1487580011970953351,"category_code":"furniture.bathroom.bath"} |1487580011970953351|furniture.bathroom.bath | | |
| +--------+----------+-------------------------------------------------------------------------------------+-------------------+-------------------------------+ |
다만, 위에서 출력된 스키마에서 확인 수 있듯이 category_id 컬럼이 원본과는 다르게 string 타입입니다. cast() 를 사용할 해 다른 타입으로 변경할 수 있습니다.
| dfRecovered = dfCategory\ | |
| .withColumn("category_id", get_json_object(col("category"), "$.category_id").cast(LongType()))\ | |
| .withColumn("category_code", get_json_object(col("category"), "$.category_code")) | |
| dfRecovered.printSchema() | |
| root | |
| |-- brand: string (nullable = true) | |
| |-- product_id: integer (nullable = true) | |
| |-- category: string (nullable = true) | |
| |-- category_id: long (nullable = true) | |
| |-- category_code: string (nullable = true) |
만약 타입이 고정되어 있다면 StructType (구조체 타입) 을 이용해 Class 처럼 타입을 형식화 할 수 있습니다. category_parsed 컬럼이 struct 타입임을 볼 수 있습니다.
| structCategory = StructType( | |
| [ | |
| StructField("category_id", LongType(), True), | |
| StructField("category_code", StringType(), True), | |
| ] | |
| ) | |
| dfStructed = dfCategory\ | |
| .withColumn("category_parsed", from_json(col("category"), structCategory)) | |
| dfStructed.printSchema() | |
| dfStructed.show(truncate=False) |
| root | |
| |-- brand: string (nullable = true) | |
| |-- product_id: integer (nullable = true) | |
| |-- category: string (nullable = true) | |
| |-- category_parsed: struct (nullable = true) | |
| | |-- category_id: long (nullable = true) | |
| | |-- category_code: string (nullable = true) | |
| +--------+----------+-------------------------------------------------------------------------------------+------------------------------------------------------+ | |
| |brand |product_id|category |category_parsed | | |
| +--------+----------+-------------------------------------------------------------------------------------+------------------------------------------------------+ | |
| |null |5902332 |{"category_id":2007399943458784057,"category_code":"apparel.glove"} |{2007399943458784057, apparel.glove} | | |
| |null |5571162 |{"category_id":1487580012147114126,"category_code":"furniture.bathroom.bath"} |{1487580012147114126, furniture.bathroom.bath} | | |
| |benovy |5911195 |{"category_id":2007399943458784057,"category_code":"apparel.glove"} |{2007399943458784057, apparel.glove} | | |
| |null |5756536 |{"category_id":2007399943458784057,"category_code":"apparel.glove"} |{2007399943458784057, apparel.glove} | | |
| |emil |5861764 |{"category_id":1487580006350586771,"category_code":"appliances.environment.vacuum"} |{1487580006350586771, appliances.environment.vacuum} | | |
| |shik |5914940 |{"category_id":1921723506584715388,"category_code":"accessories.cosmetic_bag"} |{1921723506584715388, accessories.cosmetic_bag} | | |
| |italwax |5775813 |{"category_id":1487580013053083824,"category_code":"stationery.cartrige"} |{1487580013053083824, stationery.cartrige} | | |
| |null |5923808 |{"category_id":1487580008070251489,"category_code":"appliances.personal.hair_cutter"}|{1487580008070251489, appliances.personal.hair_cutter}| | |
| |null |5856308 |{"category_id":2022622168218599898,"category_code":"furniture.living_room.chair"} |{2022622168218599898, furniture.living_room.chair} | | |
| |max |5855509 |{"category_id":1487580006350586771,"category_code":"appliances.environment.vacuum"} |{1487580006350586771, appliances.environment.vacuum} | | |
| |null |5813075 |{"category_id":1487580011970953351,"category_code":"furniture.bathroom.bath"} |{1487580011970953351, furniture.bathroom.bath} | | |
| |benovy |5901872 |{"category_id":2007399943458784057,"category_code":"apparel.glove"} |{2007399943458784057, apparel.glove} | | |
| |null |5912860 |{"category_id":2018287324474901238,"category_code":"furniture.bathroom.bath"} |{2018287324474901238, furniture.bathroom.bath} | | |
| |nitrile |5889686 |{"category_id":2007399943458784057,"category_code":"apparel.glove"} |{2007399943458784057, apparel.glove} | | |
| |null |5913116 |{"category_id":2018287324474901238,"category_code":"furniture.bathroom.bath"} |{2018287324474901238, furniture.bathroom.bath} | | |
| |null |5713291 |{"category_id":1487580008070251489,"category_code":"appliances.personal.hair_cutter"}|{1487580008070251489, appliances.personal.hair_cutter}| | |
| |null |5657896 |{"category_id":1487580013053083824,"category_code":"stationery.cartrige"} |{1487580013053083824, stationery.cartrige} | | |
| |jessnail|5877460 |{"category_id":1487580006350586771,"category_code":"appliances.environment.vacuum"} |{1487580006350586771, appliances.environment.vacuum} | | |
| |vosev |5904212 |{"category_id":1487580010695884882,"category_code":"accessories.bag"} |{1487580010695884882, accessories.bag} | | |
| |kinetics|5829359 |{"category_id":1487580011970953351,"category_code":"furniture.bathroom.bath"} |{1487580011970953351, furniture.bathroom.bath} | | |
| +--------+----------+-------------------------------------------------------------------------------------+------------------------------------------------------+ |
AWS 에서는 ALB, CLB, CloudTrail 등의 로그가 S3 에 쌓입니다.이 데이터를 spark.read.json() 으로 읽어서 원하는 컬럼을 뽑아내는 연습을 해봅시다.
- CloudTrail 과 같은 경우에는 gzip 으로 압축된 JSON 포맷이며 특정 컬럼의 형식이 Event Type 에 따라 동적일 수 있습니다.
- 그렇다면 StructType 이 나을지, get_json_object 가 나을지도 논의해 봅시다.
다음은 CloudTrail 과 AWS LB 로그를 확인할 수 있는 사이트입니다.
Practice
실습 과제입니다.
- 본 챕터 내의 Window Function – Attribution 문제를 DataFrame 을 이용해 구해봅니다.
- 본 챕터 내의 Window Function – Session 문제를 DataFrame 을 이용해 구해봅니다.
- 본 챕터 내의
dfRaw를 DataFrame API 의 explode() 가 아니라 LATERAL VIEW 를 이용해서 풀어 헤쳐 봅니다. dfRaw 를 테이블로 등록하기 위해 다음 챕터에서 배울createOrReplaceTempView를 사용할 수 있습니다.
| dfRaw.createOrReplaceTempView("RAW") | |
| spark.sql(""" | |
| SELECT ... | |
| LATERAL VIEW ... | |
| """) |
Summary
아래는 이번 챕터에서 다룬 핵심 키워드입니다.
- Window Function
- JSON Function
- explode(), Unnest, LATERAL VIEW
- Attribution Model
- Session
