Practical 시리즈는 AWS 환경 위에서 데이터 인프라를 구축하는데 참고할만한 내용들을 담고 있습니다. 이 글은 그 중 Practical Spark 의 한 챕터입니다. 이번 챕터에서는 Spark 를 이용해 데이터를 저장하기 위한 방법과 Parquet, Avro 같은 Columnar 및 Serialization 포맷을 다루고, JDBC Driver 를 통해 MySQL 등 RDB 에서 데이터를 읽고 쓸 때의 주의사항에 대해 알아봅니다.

Practical 시리즈는 AWS 환경 위에서 데이터 인프라를 구축하는데 참고할만한 내용들을 담고 있습니다. 아래의 내용들을 주로 다룹니다.
- Practical Spark
- Practical Kafka
- Practical Kubernetes
- Practical AWS
이 블로그에 작성된 내용은 위 시리즈 중 Gitbook 으로 작성된 Practical Spark 를 옮긴 것입니다. 원본 Gitbook 와 실습에 사용하는 코드는 아래의 링크에서 보실 수 있습니다.
- (Spark Batch) https://1ambda.gitbook.io/practical-data-pipeline/02-processing/2.2-batch
- (Spark Stream) https://1ambda.gitbook.io/practical-data-pipeline/02-processing/2.4-stream
- (Code) https://github.com/1ambda/practical-data-pipeline-code
Spark Persistence

지난 챕터에서는 Spark 는 다양한 형태의 파일을 읽어 DataFrame, 즉 테이블 형태의 논리적인 추상을 제공한다는 것을 익혔습니다.
- 사용자는 수 많은 파일들을 묶어, 하나의 테이블처럼 사용할수 있고
- 대규모 처리가 필요할 경우 원하는 수준으로 Partition 을 분할해 복수개의 Executor 에서 나누어 처리할 수 있습니다
- CSV 뿐만 아니라 JSON, Parquet, JDBC 등에서 데이터를 읽어 여러 DataFrame 을 만든뒤 Join 을 수행해 복합적인 데이터 가공 및 분석도 가능합니다
RDS / Aurora (MySQL 등) 에는 Snapshot Export 라는 기능이 있습니다. 이 기능을 이용하면 DB 의 특정 시점의 테이블들을 S3 에 Parquet 포맷으로 저장이 가능합니다.
서비스에 즉시 반영되어야 하는 Transaction 과는 상관없는 후처리 (분석 혹은 운영성 배치작업) 할 경우 S3 (또는 GCS 등) 에 저장되어 있는 Parquet 포맷을 읽어 데이터 가공을 진행한다면 RDB 에 부하를 주지 않으면서 저렴한 비용으로 (S3) 작업을 할 수 있습니다.
또한 RDB 에 있는 데이터가 뿐만 아니라 비즈니스 담당자가 구글 시트 등에서 관리하는 데이터도 CSV 로 만들어 S3 등에 올려둔다면 Join 후 가공하는 것도 가능합니다. Spark 가 빌트인으로 읽을 수 있는 파일 포맷은 Spark SQL Guide – Generic Load / Save 문서에서 확인할 수 있습니다.
이번 챕터에서는 위와 같이 Spark DataFrame 을 이용해 데이터를 메모리에 올려 가공하기 위해 다양한 포맷의 데이터를 읽고 저장하는 방법에 대해 배워보겠습니다.
이번시간에 사용할 데이터셋은 Kaggle – Denver AirBNB 입니다. 파일을 다운받은 후 다음과 같이 이름을 변경합니다.
| calendar.csv -> airbnb_calendar.csv | |
| listing.csv -> airbnb_listings.csv | |
| neighbourhoods.csv -> airbnb_neighbourhoods.csv | |
| reviews.csv -> airbnb_reviews.csv |
CSV & JSON
CSV 는 기존 챕터에서 사용하던 방식으로 읽을 수 있습니다. 다만 이번에는 데이터 내에 문자열 컬럼 (listing_description 등) 이 있고 여러 라인이 될 수 있기 때문에 옵션을 조금 조정합니다.옵션을 살펴보면 다음 옵션이 추가되었음을 알 수 있습니다.
- quote
- escape
- multiline
| from pyspark.sql.types import * | |
| from pyspark.sql.functions import * | |
| from pyspark.sql.window import Window | |
| dfListing = spark.read.load("./airbnb_listings.csv", | |
| format="csv", inferSchema=True, header=True, | |
| quote='"', escape='"', sep=',', multiline=True) | |
| dfListing.printSchema() | |
| dfListing.count() |
| root | |
| |-- id: integer (nullable = true) | |
| |-- listing_url: string (nullable = true) | |
| |-- scrape_id: long (nullable = true) | |
| |-- last_scraped: string (nullable = true) | |
| |-- name: string (nullable = true) | |
| |-- summary: string (nullable = true) | |
| |-- space: string (nullable = true) | |
| |-- description: string (nullable = true) | |
| |-- experiences_offered: string (nullable = true) | |
| |-- neighborhood_overview: string (nullable = true) | |
| |-- notes: string (nullable = true) | |
| ... | |
| |-- host_id: integer (nullable = true) | |
| |-- host_url: string (nullable = true) | |
| |-- host_name: string (nullable = true) | |
| |-- host_since: string (nullable = true) | |
| |-- host_location: string (nullable = true) | |
| |-- host_about: string (nullable = true) | |
| ... | |
| |-- city: string (nullable = true) | |
| |-- state: string (nullable = true) | |
| |-- zipcode: string (nullable = true) | |
| |-- market: string (nullable = true) | |
| |-- smart_location: string (nullable = true) | |
| |-- country_code: string (nullable = true) | |
| |-- country: string (nullable = true) | |
| |-- latitude: double (nullable = true) | |
| |-- longitude: double (nullable = true) | |
| |-- is_location_exact: string (nullable = true) | |
| |-- property_type: string (nullable = true) | |
| |-- room_type: string (nullable = true) | |
| |-- accommodates: integer (nullable = true) | |
| |-- bathrooms: double (nullable = true) | |
| |-- bedrooms: integer (nullable = true) | |
| |-- beds: integer (nullable = true) | |
| |-- bed_type: string (nullable = true) | |
| |-- amenities: string (nullable = true) | |
| |-- square_feet: integer (nullable = true) | |
| |-- price: string (nullable = true) | |
| |-- weekly_price: string (nullable = true) | |
| |-- monthly_price: string (nullable = true) | |
| |-- security_deposit: string (nullable = true) | |
| |-- cleaning_fee: string (nullable = true) | |
| |-- guests_included: integer (nullable = true) | |
| |-- extra_people: string (nullable = true) | |
| |-- minimum_nights: integer (nullable = true) | |
| |-- maximum_nights: integer (nullable = true) | |
| |-- minimum_minimum_nights: integer (nullable = true) | |
| |-- maximum_minimum_nights: integer (nullable = true) | |
| |-- minimum_maximum_nights: integer (nullable = true) | |
| |-- maximum_maximum_nights: integer (nullable = true) | |
| |-- minimum_nights_avg_ntm: double (nullable = true) | |
| |-- maximum_nights_avg_ntm: double (nullable = true) | |
| |-- calendar_updated: string (nullable = true) | |
| |-- has_availability: string (nullable = true) | |
| |-- availability_30: integer (nullable = true) | |
| |-- availability_60: integer (nullable = true) | |
| |-- availability_90: integer (nullable = true) | |
| |-- availability_365: integer (nullable = true) | |
| |-- calendar_last_scraped: string (nullable = true) | |
| |-- number_of_reviews: integer (nullable = true) | |
| |-- number_of_reviews_ltm: integer (nullable = true) | |
| |-- first_review: string (nullable = true) | |
| |-- last_review: string (nullable = true) | |
| |-- review_scores_rating: integer (nullable = true) | |
| |-- review_scores_accuracy: integer (nullable = true) | |
| |-- review_scores_cleanliness: integer (nullable = true) | |
| |-- review_scores_checkin: integer (nullable = true) | |
| |-- review_scores_communication: integer (nullable = true) | |
| |-- review_scores_location: integer (nullable = true) | |
| |-- review_scores_value: integer (nullable = true) | |
| ... | |
| ... | |
| 4865 |
listing 은 AirBNB 의 상품인 숙소 (Property) 입니다. listing 마다 id 값이 부여되며, 이 listing_id 값을 이용해 아래에서 airbnb_calendar.csv 내의 숙소마다의 일별 가격과 같이 데이터를 보도록 하겠습니다.
JSON 파일을 읽는 방법도 동일합니다. 다만 현재는 JSON 파일이 없으므로, 위에서 읽은 airbnb_listings.csv 를 JSON 으로 Write 해본 후 다시 읽어보겠습니다.
listing 의 id, url, name, summary, description 만 SELECT 후 JSON 으로 Write 를 해보면 아래와 같습니다.
| dfListingSelected = dfListing.selectExpr( | |
| "id as listing_id", | |
| "listing_url", | |
| "name as listing_name", | |
| "summary as listing_summary", | |
| "description as listing_desc" | |
| ) |
| # 2개의 Partition 으로 만든 뒤, JSON 포맷으로 GZIP 압축하여 | |
| # airbnb_listings 디렉토리에 (Jupyter Notebook 의 경우 현재 ipynb 노트북이 위치한 디렉토리) | |
| # Overwrite (덮어쓰기) 저장합니다 | |
| dfListingSelected\ | |
| .repartition(2)\ | |
| .write\ | |
| .mode("overwrite")\ | |
| .format("json")\ | |
| .option("compression", "gzip")\ | |
| .save("airbnb_listings") |
| ls -alh airbnb_listings/ | |
| total 1.9M | |
| part-00000-850995d8-9964-4f8c-919f-60abaa20d45b-c000.json.gz | |
| .part-00000-850995d8-9964-4f8c-919f-60abaa20d45b-c000.json.gz.crc | |
| part-00001-850995d8-9964-4f8c-919f-60abaa20d45b-c000.json.gz | |
| .part-00001-850995d8-9964-4f8c-919f-60abaa20d45b-c000.json.gz.crc | |
| _SUCCESS | |
| ._SUCCESS.crc |
Repartition 값을 2개로 지정해 2개의 파일이 생성된것을 볼 수 있습니다. 위의 예시에서는 파일이 너무 작아 사실 나눌 필요는 없으나, 예시를 위에서 Partition 값을 1보다 크게 만들어 파일을 나누었습니다.
- 파일의 경우 DataFrame.save 전에 repartition 된 숫자 만큼 파일이 생성됩니다.
- 개별 파일 사이즈가 너무 크다면 repartition 을 통해 파일 숫자를 늘리면, 파일 사이즈가 줄어듭니다.
- 개별 파일 사이즈가 너무 작다면 repartition 을 통해 파일 숫자를 줄이면, 파일 사이즈가 커집니다.
- 파일 사이즈가 너무 크다면 파일 하나를 읽는데도 메모리가 부족할 수 있습니다.
- 파일 숫자가 너무 많다면 전체 파일을 리스팅 하는 등 추가적인 부담이 들 수 있습니다.
Write / Read 시에 여러 옵션을 줄 수 있습니다. 파일 포맷 마다 지원되는 옵션은 다르며, 위의 코드에서는 예시를 위해 JSON Write 시에 gzip 압축 옵션을 넣었습니다.
Write 시에는 mode 옵션에 주의해야 합니다.
- “append” 는 기존 데이터에 덧붙입니다. File 의 경우에는 추가 파일이 만들어지므로, 의도하지 않았을 경우에는 중복이 발생합니다.
- “overwrite”: 는 기존 데이터를 삭제하고 새로 적재합니다. 데이터에 문제가 있거나 등의 이유로 재적재 하는 경우에만 이 옵션을 사용합니다. Default 로 지정해 놓을 경우 실수로 기존 데이터를 삭제할 수 있으니 주의해야 합니다.
- “error”: 데이터가 이미 존재할 경우 Error (Exception) 이 발생합이다. 대부분의 경우 기본 설정으로 이 값을 사용하는 편이 낫습니다.
Write 모드 중 Update / Upsert 는 존재하지 않습니다. 데이터를 업데이트하기 위해
- Iceberg (rewrite)
- Apache Hudi (Upsert) / Delta Lake / Hive ACID 등을 사용할 수 있습니다.
이제 만들어진 데이터를 읽어보겠습니다. spark.read.format("json") 을 통해 읽는 것이 가능합니다.
| # 디렉토리 내의 분할된 모든 JSON 파일을 다 읽습니다. | |
| dfListingJson = spark.read.format("json").load("./airbnb_listings") | |
| dfListingJson.count() | |
| dfListingJson.rdd.getNumPartitions() | |
| dfListingJson.printSchema(truncate=True) |
| 4865 # dfListingJson.count() | |
| 2 # dfListingJson.rdd.getNumPartitions() | |
| # dfListingJson.printSchema(truncate=True) | |
| +----------+--------------------+--------------------+--------------------+--------------------+ | |
| |listing_id| listing_url| listing_name| listing_summary| listing_desc| | |
| +----------+--------------------+--------------------+--------------------+--------------------+ | |
| | 360|https://www.airbn...|LoHi Secret garde...|Come enjoy our oa...|Come enjoy our oa...| | |
| | 590|https://www.airbn...|Comfortable - an...|Large guest room ...|Large guest room ...| | |
| | 592|https://www.airbn...| private|This room is in t...|This room is in t...| | |
| | 1940|https://www.airbn...|Baker Studio Clos...|Great place for a...|Great place for a...| | |
| | 2086|https://www.airbn...| Garden Level Condo|A furnished, gard...|A furnished, gard...| | |
| | 31503|https://www.airbn...|Highland Park Gue...| null|Highland Park Gue...| | |
| | 39405|https://www.airbn...|LoHi Secret garde...|Come enjoy our oa...|Come enjoy our oa...| | |
| | 56185|https://www.airbn...|charming home for...| null|Spend time in Den...| | |
| | 59631|https://www.airbn...|VICTORIAN TOWNHOM...|License #2017-BFN...|License #2017-BFN...| | |
| | 74125|https://www.airbn...|Spacious Cap Hill...|1000' entire-firs...|1000' entire-firs...| | |
| | 81540|https://www.airbn...|Affordable S. Den...|Bright, sunny 1 b...|Bright, sunny 1 b...| | |
| | 90307|https://www.airbn...|Comfy King Size R...| null|This private bedr...| | |
| | 98008|https://www.airbn...|Beautiful sun fil...|Locaton, location...|Locaton, location...| | |
| | 98014|https://www.airbn...|Beautiful single ...| null|Hi Folks! Welcom...| | |
| | 142683|https://www.airbn...|Historic Denver C...| null|One of three cond...| | |
| | 172196|https://www.airbn...|Luxury Wash Park ...|Remodeled wash pa...|Remodeled wash pa...| | |
| | 184529|https://www.airbn...|HIP SUITE IN WES...|Private SUIITE ...|Private SUIITE ...| | |
| | 192430|https://www.airbn...|TREETOP VIEW ROOM...|Located in the de...|Located in the de...| | |
| | 217996|https://www.airbn...| Highland Snug|Comfortable and c...|Comfortable and c...| | |
| | 236207|https://www.airbn...|Denver Penthouse ...|Important Note : ...|Important Note : ...| | |
| +----------+--------------------+--------------------+--------------------+--------------------+ |
데이터의 숫자도 Write 한 것과 동일하고, 컬럼이름도 올바른 것을 확인할 수 있습니다.
Spark 는 JSON 파일을 읽으면서 각 컬럼의 타입을 추론합니다. 컬럼 타입을 정하려면 각 컬럼별로 전체 값을 읽어야 합니다. 따라서 파일이 매우 크고 이미 타입을 알고 있다면 추론을 Spark 가 하는 대신 primitivesAsString 값을 이용해 String 으로 값을 세팅하고 cast() 등의 함수를 이용해 직접 타입을 지정하면 추론에 들어가는 시간을 줄일 수 있습니다.
CSV Write 또한 같은 방법으로 가능합니다. 이번에는 repartition(1) 을 지정하면 파일이 1개만 생성되고 압축을 하지 않았으므로 이전보다 사이즈가 커진것도 볼 수 있습니다 (1.9M -> 6.6M)
| dfListingSelected\ | |
| .repartition(1)\ | |
| .write\ | |
| .mode("overwrite")\ | |
| .format("csv")\ | |
| .option("header", "true")\ | |
| .save("airbnb_listings_selected") |
| $ ls -alh airbnb_listings_selected | |
| total 6.6M | |
| part-00000-965313d2-2a07-49e4-b7a1-9c7d9a43129d-c000.csv | |
| .part-00000-965313d2-2a07-49e4-b7a1-9c7d9a43129d-c000.csv.crc | |
| _SUCCESS |
일반적으로는 데이터를 로컬에 파일로 저장하지 않고 AWS S3, GCP GCS, HDFS 등에 저장합니다.이 때 시스템의 호환성 / 운영 용이성 등을 위해 데이터를 일별 /시간별로 나누어 다음과 같은 경로처럼 저장합니다.
- s3://udon-data-prod/db/udon-service/udon-order/2021/11/01
- s3://udon-data-prod/db/udon-service/udon-order/2021/11/02
- s3://udon-data-prod/log/udon-service/udon-client/2021/11/01/00
- s3://udon-data-prod/log/udon-service/udon-client/2021/11/01/01
1일치 데이터만 처리한다면 2021/11/01 경로의 데이터를 읽을 수 있습니다. 만약 2일치 데이터를 Spark 를 이용해 각 경로의 데이터를 범위로 있겠지만, 일별로 데이터를 읽는게 편하진 않습니다.테이블처럼 데이터를 쓸 수 있게 해주는 메타스토어는 다른 챕터에서 다시 논의해 보겠습니다.
Parquet – Columnar Format
데이터를 빠르게 가공하기 위해선 CPU, Memory 와 같은 리소스와 Spark 같은 분산 처리 프레임워크도 중요하지만 데이터가 어디에 어떻게 저장되어 있는지도 굉장히 중요한 요소입니다.
이 섹션에서는 Parquet, ORC 와 같은 Columnar Format 에 대해서 알아보겠습니다.

왜 Parquet, ORC 같은 Columnar Format 이 필요할까요? 2013년에 발표된 Parquet: Columnar Storage for The People 슬라이드에서는 Columnar Format 의 장점을 크게 4가지로 이야기 하고 있습니다.
- (Column Pruning) 대부분의 경우 데이터는 몇몇 Column 단위로 이용되므로 (SELECT b, d) Column 기준으로 데이터를 읽을 수 있다면 IO 등 물리 비용을 줄일 수 있습니다.
- (Column Encoding) Column 중심으로 데이터를 저장할 경우 타입에 특화된 인코딩을 통해 저장 공간을 줄일 수 있습니다
- 예를 들어 udon_department 란 컬럼이 있고 값으로 development / product_owner 와 같은 ENUM 값이 있다면 development = 1 로 저장하는 것이 가능합니다. (Parquet Encoding)
- (Predicate PushDown) 데이터를 Spark 로 가져오기 전 미리 필터링이 가능해 네트워크 비용을 포함한 데이터 가공 비용을 크게 줄일 수 있습니다.
- 마지막으로 컴퓨팅 프레임워크 구현에 따라 벡터화된 연산이 가능합니다.
- 예를 들어, 한 번에 한 Row 만 연산을 수행하는 것이 아니라 다수의 Row 를 묶어 덧셈을 수행하는 등 묶음 연산을 수행해 컴퓨팅 시간을 줄일 수 있습니다. Spark / Hive 에서는 Parquet 를 통한 벡터화 연산을 지원합니다.
- https://issues.apache.org/jira/browse/HIVE-4160
- https://issues.apache.org/jira/browse/SPARK-12854
아래 이미지는 인코딩을 이용한 사이즈 절감과 Vectorized Operation 을 그림을 통해 보여줍니다.
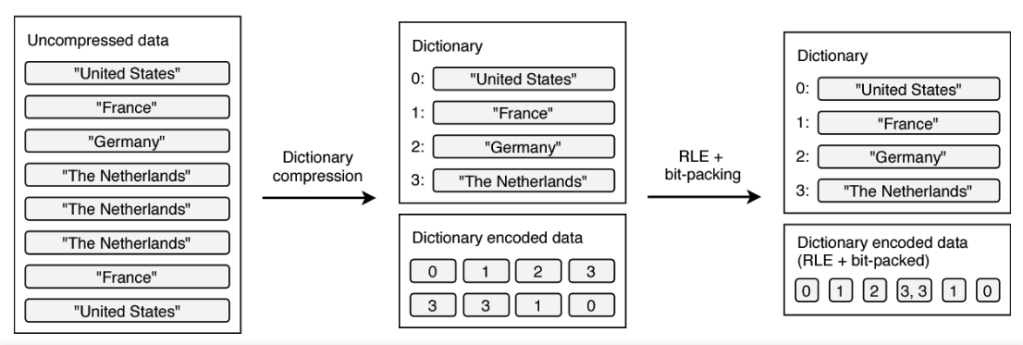



Parquet 파일 포맷으로 데이터를 저장하면, 내부적으로는 Row 를 묶어 Row Group 을 만들어 저장합니다. Row Group 내의 각 컬럼별로 통계치를 가질 수 있습니다.
- Column Pruning (혹은 Projection Pushdown) 을 이용해 필요한 컬럼 값만 뽑아내고
- Predicate Pushdown 을 이용해 Row 그룹 내 값을 미리 필터링 할 수 있습니다.
- 예를 들어, WHERE A < 2 라는 조건이 있다면, Row Group 2 번은 읽지 않을 수 있습니다.
아래 그림은 Projection 과 Predicate Pushdown 을 그림을 통해 보여줍니다.

위와 같은 Pruning 과 Pushdown 을 구현하기 위해서 Parquet 파일 포맷은 다음처럼 구성되어 있습니다.


하나의 Row Group 내에는 Column Chunk 가 여러개 존재하며, Column Chunk 는 다시 여러개의 Page 로 구성됩니다. Parquet 는 파일의 Footer Metadata 내에 Column 의 통계 정보를 가지고 있습니다.
Spark 에서 Parquet 사용법은 CSV / JSON 사용법과 동일합니다.
- Generic Read / Write 함수를 이용해 (Spark Docs – Generic Load / Save)
- Parquet-specific 한 옵션을 주는 것이 가능합니다 (Spark Docs – Parquet Files)
- ORC 도 크게 다르지 않습니다 (Spark Docs – ORC Files)
우선 Parquet 파일을 만들어 봅시다. DataFrame 을 Parquet Format 으로 Write 해보겠습니다.
| dfListingSelected\ | |
| .repartition(1)\ | |
| .write\ | |
| .mode("error")\ | |
| .format("parquet")\ | |
| .option("compression", "snappy")\ | |
| .save("airbnb_listings_parquet") | |
| dfListingParquet.rdd.getNumPartitions() | |
| dfListingParquet.printSchema() | |
| dfListingParquet.count() |
| #dfListingParquet.rdd.getNumPartitions() | |
| 1 | |
| # dfListingParquet.printSchema() | |
| root | |
| |-- listing_id: integer (nullable = true) | |
| |-- listing_url: string (nullable = true) | |
| |-- listing_name: string (nullable = true) | |
| |-- listing_summary: string (nullable = true) | |
| |-- listing_desc: string (nullable = true) | |
| # dfListingParquet.count() | |
| 7705 |
| ls -alh airbnb_listings_parquet | |
| total 3.5M | |
| drwxr-sr-x 2 jovyan users 4.0K Oct 31 19:35 . | |
| drwxrwsr-x 8 jovyan users 4.0K Oct 31 19:35 .. | |
| -rw-r--r-- 1 jovyan users 3.5M Oct 31 19:35 part-00000-83052369-7b26-494f-b223-91ae23970f8e-c000.snappy.parquet | |
| -rw-r--r-- 1 jovyan users 28K Oct 31 19:35 .part-00000-83052369-7b26-494f-b223-91ae23970f8e-c000.snappy.parquet.crc | |
| -rw-r--r-- 1 jovyan users 0 Oct 31 19:35 _SUCCESS | |
| -rw-r--r-- 1 jovyan users 8 Oct 31 19:35 ._SUCCESS.crc |
압축을 Snappy 로 한 것 이외에는 CSV, JSON 과 사용법이 동일합니다. 이제 만들어진 Parquet 파일을 읽어서 DataFrame 으로 만들어 보겠습니다.
| dfListingParquet = spark.read.format("parquet").load("./airbnb_listings_parquet") | |
| dfListingParquet.rdd.getNumPartitions() | |
| dfListingParquet.printSchema() | |
| dfListingParquet.count() |
| # dfListingParquet.rdd.getNumPartitions() | |
| 1 | |
| # dfListingParquet.printSchema() | |
| root | |
| |-- listing_id: integer (nullable = true) | |
| |-- listing_url: string (nullable = true) | |
| |-- listing_name: string (nullable = true) | |
| |-- listing_summary: string (nullable = true) | |
| |-- listing_desc: string (nullable = true) | |
| # dfListingParquet.count() | |
| 4865 |
파티션 값이 1임을 알 수 있습니다. spark.read 로 파일을 읽을 경우에는 파일 사이즈나 숫자에 의해 동적으로 Partition 숫자가 spark.default.parallelism (default = 200) 값에 따라 조절됩니다. 만약 파일 숫자가 늘어난다면 Partition 숫자도 늘어나지 않을까요?
| dfListingSelected\ | |
| .repartition(2000)\ | |
| .write\ | |
| .mode("overwrite")\ | |
| .format("parquet")\ | |
| .option("compression", "snappy")\ | |
| .save("airbnb_listings_parquet") | |
| dfListingParquet = spark.read.format("parquet").load("./airbnb_listings_parquet") | |
| dfListingParquet.rdd.getNumPartitions() | |
| dfListingParquet.select(spark_partition_id().alias("partitionId")).groupBy("partitionId").count().show() |
| # dfListingParquet.rdd.getNumPartitions() | |
| 197 | |
| # dfListingParquet.select(spark_partition_id().alias("partitionId")).groupBy("partitionId").count().show() | |
| +-----------+-----+ | |
| |partitionId|count| | |
| +-----------+-----+ | |
| | 148| 21| | |
| | 31| 29| | |
| | 85| 24| | |
| | 137| 21| | |
| | 65| 24| | |
| | 53| 24| | |
| | 133| 21| | |
| | 78| 23| | |
| | 108| 24| | |
| | 155| 24| | |
| | 34| 29| | |
| | 193| 22| | |
| | 101| 25| | |
| | 115| 22| | |
| | 126| 23| | |
| | 81| 22| | |
| | 28| 30| | |
| | 183| 25| | |
| | 76| 22| | |
| | 26| 30| | |
| +-----------+-----+ | |
| only showing top 20 rows |
만약 파일 숫자와 파티션 숫자가 다르다면 왜 다른걸까요?Spark 에서 DataFrame 으로 파일을 읽을 때 적용되는 옵션을 다음 문서에서 찾아봅시다.
- SQL Performance Tuning
- spark.sql.files.maxPartitionBytes
- spark.sql.files.openCostInBytes
- spark.sql.files.minPartitionNum
Parquet (또는 ORC 등) 와 같이 다양한 언어 (Java, Python) 및 프레임워크 (Spark, Dask) 를 지원하는 경우에는 호환성을 테스트 해보는 편이 좋습니다.
- 예를 들어 Parquet 로 데이터를 저장한다고 가정하면
- Scala Spark 에서 저장한 파일을 Hive, Presto, Dask 등에서 읽을 수 있는지
- 거꾸로 Python Dask 에서 저장한 파일을 반대로 Hive, Presto, Spark 등에서 읽을 수 있는지
- 사용하는 타입이 언어 및 프레임워크 별로 전부 호환이 되는지 확인해야 합니다.
이를 위해 포맷을 도입하기 전 사내에서 사용하는 도구에 대해 다양하게 테스트를 해보는 편이 낫습니다. Parquet 스펙이 지원한다 하더라도 언어나 실제 구현체에서 지원하지 않을 수 있기 때문입니다.이런 이유로 타입의 경우에는 데이터 사이즈에서 미미한 손해를 보더라도, 호환성을 위해 큰 타입을 사용하는 편이 낫습니다. (INT32 -> Long 등)
더 세밀하게 사용할수록, 더 많은 문제를 마주칠 확률이 높습니다. 이른 최적화는 약이 아니라 독일 가능성이 많습니다.
early optimization is the root of all evil
타입을 잘못 맞추면 고통을 겪을 수 있습니다.
예를 들어, Spark 2.4 이하와 Hive, Impala 등에서는 Parquet 파일 저장시 Timestamp 타입을 INT96 (12 bytes) 으로 지정합니다. 그러나 Parquet 에서는 INT96 은 공식적으로 지원하진 않습니다. 따라서 Spark 에서는 Parquet 의 INT96 을 읽을 때 Timestamp 타입으로 자동으로 전환하며 spark.sql.parquet.int96AsTimestamp 옵션을 통해 변환될 타입을 지정할 수 있습니다.
Spark 3.0 이상에서는 spark.sql.parquet.outputTimestampType 를 통해 Write 시 Timestamp 값을 위한 Parquet 타입값을 지정할 수 있으며 기본으로는 TIMESTAMP_MICROS (Parquet 의 INT64 타입) 형식으로 저장합니다.
Since Spark 3.0, parquet logical type TIMESTAMP_MICROS is used by default while saving TIMESTAMP columns. In Spark version 2.4 and earlier, TIMESTAMP columns are saved as INT96 in parquet files. To set INT96 to spark.sql.parquet.outputTimestampType restores the previous behavior.
https://spark.apache.org/docs/3.0.0-preview/sql-migration-guide.html
Avro – Data Serialization

Apache Avro 는 데이터 직렬화 도구입니다. Java, Pyton 은 물론 Ruby, C, C# 등 다양한 언어에서 활용할 수 있으며 주로 Kafka Schema Registry 에서 많이 활용되곤 합니다.
JSON 을 전송하고 받아서 사용하는것에 비해 Avro, Protobuf, Thrift 와 같은 언어 중립적인 데이터 직렬화 시스템을 사용하는데는 몇 가지 이유가 있습니다.
- 언어 중립적이므로 어떤 언어를 사용하는지 상관없이 직렬화 도구가 지원한다면 다양한 언어로 데이터를 읽고 쓸 수 있습니다. (e.g, Kafka Producer & Consumer)
- 스키마를 미리 정의하고 사용하므로 실수로 변경될 부분을 방지하고 미래의 변경도 기존 소비자 (Consumer 등) 를 위한 스키마 호환을 (Avro Schema Evoluation) 지원합니다.
- 타입이 정해져 있으므로 Encoding 을 통한 사이즈 축소 및 효율적인 조회 (Columnar 의 경우 Colume Pruning, Predicate Pushdown 등) 이 가능합니다.
- Thrift, ProtoBuf (gRPC) 와 같은 프레임워크는 RPC API 를 제공하기도 합니다.
파일을 별도의 포맷을 저장하는 이유는 다음과 같습니다.
많은 경우에 다음과 같이 사용합니다.
- S3, HDFS 등에 저장된 대규모의 / 읽기를 위한 데이터는 Parquet, ORC 등 읽기 및 압축 효율이 좋은 Columnar 포맷을 사용합니다. 읽기가 빈번하고 사이즈가 매우 커질 수 있기 때문입니다.
- Kafka / API 등 실시간으로 데이터를 주고 받는 경우에는 Avro 처럼 Schema 관리가 편리하거나 (Registry 등 도구 제공) Protobuf w/ gRPC 처럼 통신을 위한 라이브러리가 지원되는 포맷을 활용하는 경우가 많습니다.
물론 장점만 있지는 않습니다. 멀쩡한 데이터를 Header (Schema / Meta) + Payload (Data) 로 변경하고 인코딩을 수행해야 하므로 CPU 리소스를 태웁니다. 다만 사이즈는 작아질 수 있기에 네트워크 비용에서 이점을 볼 수 있습니다.
Avro 를 사용하기 위해서는
- Data Serialization 포맷은 IDL (Interface Definition Language) 이라 불리는 스키마 파일을 작성합니다
- Protobuf / Thrift / Avro 의 경우에는 IDL 을 바탕으로 코드를 생성할 수 있습니다.
아래는 Protobuf 의 IDL 샘플 입니다. Avro 도 비슷하게 스키마를 작성할 수 있습니다. 다만 지원되는 문법과 타입이 다를 수 있습니다.
| message SearchRequest { | |
| required string query = 1; | |
| optional int32 page_number = 2; | |
| optional int32 result_per_page = 3 [default = 10]; | |
| enum Corpus { | |
| UNIVERSAL = 0; | |
| WEB = 1; | |
| IMAGES = 2; | |
| LOCAL = 3; | |
| NEWS = 4; | |
| PRODUCTS = 5; | |
| VIDEO = 6; | |
| } | |
| optional Corpus corpus = 4 [default = UNIVERSAL]; | |
| } | |
| message SearchResponse { | |
| ... | |
| } |
Avro 의 경우에는 다른 프레임워크와 다르게, Data 자체에 Schema 를 포함합니다.
- 따라서 코드 생성을 통해 빌드 타임에 데이터 클래스를 생성할 수 있지만 (Avro SpecificRecord)
- 런타임에도 Deserialization 을 수행할 수 있습니다. 다만 런타임에 예외가 발생할 수 있습니다. (Avro GenericRecord)
- 피치 못한 경우가 아니라면 빌드 타임에 데이터 클래스를 생성해 사용하는 편이 낫습니다.
아래는 Avro 스키마 샘플입니다.
| # property.avsc | |
| { | |
| "namespace": "io.github.1ambda.avro", | |
| "type": "record", | |
| "name": "Property", | |
| "fields": [ | |
| { | |
| "name": "name", | |
| "type": "string" | |
| }, | |
| { | |
| "name": "description", | |
| "type": "string" | |
| }, | |
| { | |
| "name": "property_id", | |
| "type": "long" | |
| }, | |
| { | |
| "name": "price", | |
| "type": "double" | |
| } | |
| ] | |
| } |
Avro 는 주로 Kafka 와 함께 활용됩니다.
- Avro 로 Serialized 된 데이터를 Kafka Broker 로 직접 보내고 읽을 수 있습니다.
- 만약 Schema Registry 를 이용하면 업타임에 Producer / Consumer 에서 스키마를 등록하거나 받아올 수 있습니다.
- Confluent Schema Registry 의 경우 Avro 뿐만 아니라 Protobuf, JSON 형식의 스키마도 지원합니다.
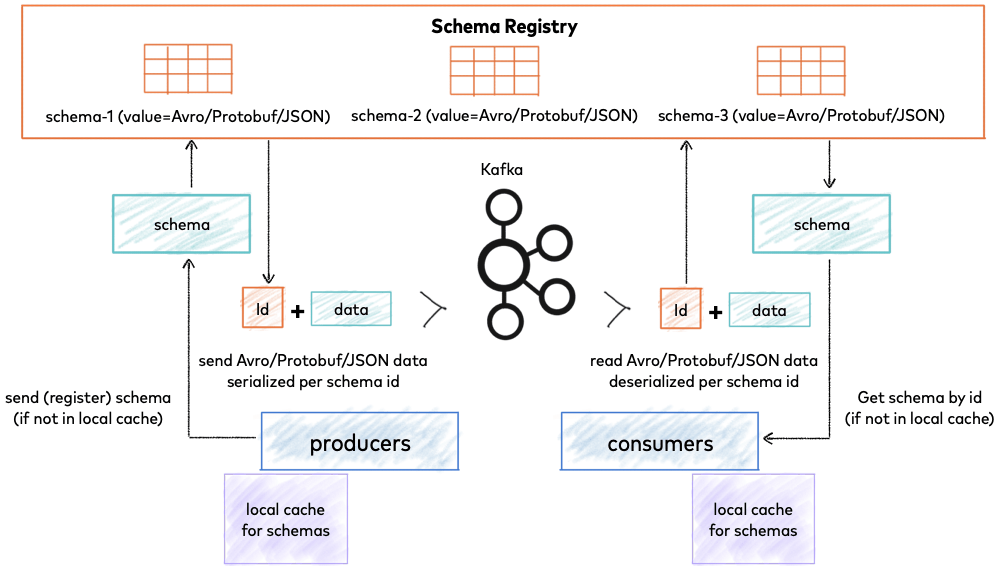
Avro 로 직렬화 해 Binary 로 직접 보내는것과 Schema Registry 를 이용해 직렬화 보내는것은 Broker 에 전송되는 내용물이 다르므로 호환되지 않습니다. 사용시 주의해야 합니다.
Avro 스키마는 일반적으로 Schema Registry 또는 .avsc (스키마 레지스트리 사용하지 않을 경우) 를 통해 포맷을 정한 후 Read / Write 를 수행합니다. 아래의 코드에서는, 예시를 위해 .avsc 파일이 있다고 가정하고 그 내용을 바탕으로 DataFrame Read / Write 를 수행합니다.
Scala Spark 에서는 abris 라이브러리를 통해 Registry / Raw Avro Format 섞어서 사용하고 DataFrame Schema 로 쉽게 전환할 수 있습니다.
이제 dfListings 에 맞추어 Avro 스키마를 만들고 Avro 파일을 저장해보겠습니다.
| # 일반적으로는 Schema Registry 또는 .avsc 파일을 읽어 스키마를 사용합니다. | |
| # 예시를 위해 String 으로 만든 Schema 를 사용합니다. | |
| schemaAvroListingV1 = """ | |
| { | |
| "type": "record", | |
| "name": "AirbnbListing", | |
| "namespace": "com.airbnb", | |
| "fields": [ | |
| {"name": "listing_id", "type": "int"}, | |
| {"name": "listing_url", "type": "string"}, | |
| {"name": "listing_name", "type": "string"}, | |
| {"name": "listing_summary", "type": ["string", "null"]}, | |
| {"name": "listing_desc", "type": ["string", "null"]} | |
| ] | |
| } | |
| """ | |
| # Avro 파일 포맷으로 저장할때 옵션을 통해 Schema 를 지정합니다. | |
| dfListingSelected\ | |
| .repartition(2)\ | |
| .write\ | |
| .mode("overwrite")\ | |
| .format("avro")\ | |
| .option("avroSchema", schemaAvroListingV1)\ | |
| .save("./airbnb_listings_avro") |

Avro 와 같은 Serialization Format 을 사용할 경우 일반적으로 Schema Evoluation 이라는 컨셉이 있습니다. 즉, 스키마가 변경될 경우 (필드 변경, 추가, 삭제) 를 어떻게 처리할 것인가를 정합니다.
직렬화 포맷이나 스키마 레지스트리 구현에 따라 지원되는 Schema Evolution 이나 용어가 다르지만 일반적으로는 크게 2가지로 나눌 수 있습니다. (X-2, X-1, X 순으로 스키마 버전이 업그레이드)
- BACKWARD: X 버전을 사용하는 컨슈머가 X-1 을 버전의 데이터 처리 가능 (신규 버전으로 읽어 들이는데, 과거 버전으로 생성된 데이터를 = 과거의 스키마)
- FORWARD: X-1 버전을 사용하는 컨슈머가 X 를 버전의 데이터 처리 가능 (과거 버전으로 읽어 들이는데, 신규 버전으로 생성된 데이터를 = 미래의 스키마)
이제 다른 버전의 스키마를 만들고 과거 버전의 Avro 를 읽어보겠습니다.
| # listing_name 이 삭제되었습니다. | |
| schemaAvroListingV2 = """ | |
| { | |
| "type": "record", | |
| "name": "AirbnbListing", | |
| "namespace": "com.airbnb", | |
| "fields": [ | |
| {"name": "listing_id", "type": "int"}, | |
| {"name": "listing_url", "type": "string"}, | |
| {"name": "listing_summary", "type": ["string", "null"]}, | |
| {"name": "listing_desc", "type": ["string", "null"]} | |
| ] | |
| } | |
| """ | |
| # 신규 버전의 스키마로 (v2) 과거 버전으로 쓰여진 (V1) 데이터를 읽습니다. | |
| dfListingAvroV2 = spark.read.format("avro")\ | |
| .option("avroSchema", schemaAvroListingV2)\ | |
| .load("/FileStore/raw/airbnb_listings_avro") | |
| dfListingAvroV2.printSchema() |
| root | |
| |-- listing_id: integer (nullable = true) | |
| |-- listing_url: string (nullable = true) | |
| |-- listing_summary: string (nullable = true) | |
| |-- listing_desc: string (nullable = true) |
Avro 파일 내에는 데이터가 여전히 존재하기 때문에 과거 버전의 스키마를 사용한다면 ‘listing_name” 을 읽어서 쓸 수 있습니다.
| # 과거 버전의 스키마로 (v1) 과거 버전으로 쓰여진 (V1) 데이터를 읽습니다. | |
| dfListingAvroV1 = spark.read.format("avro")\ | |
| .option("avroSchema", schemaAvroListingV1)\ | |
| .load("/FileStore/raw/airbnb_listings_avro") | |
| dfListingAvroV1.printSchema() |
| root | |
| |-- listing_id: integer (nullable = true) | |
| |-- listing_url: string (nullable = true) | |
| |-- listing_name: string (nullable = true) | |
| |-- listing_summary: string (nullable = true) | |
| |-- listing_desc: string (nullable = true) |
Apache Hudi 의 경우에는 Parquet 와 Avro 를 섞어 쓰는 경우가 있습니다. Hudi 를 이용해 Write 시에 Merge on Read 모드를 이용하면
- Avro File 을 Append 하고 추후에 많아진 Avro 파일을 Parquet 로 Compaction 합니다.
- Snapshot Query 로 읽을때는 Parquet + Avro 를 둘다 읽어, 실시간 데이터를 볼 수 있습니다.

JDBC (MySQL, Postgres 등)
Generic Load / Save 함수를 이용하면 JDBC 드라이버를 이용해 MySQL 과 같은 RDB 에 데이터를 넣을 수 있습니다.
RDB 는 Spark 사용할 수 있는 주요 데이터 저장소 중 하나입니다. 데이터를 가져오는 주된 Source, API 등에서 활용하기 위한 서비스 데이터의 Sink 로서도 활용합니다.추후 다른 실습 챕터에서 데이터를 활용해 통계 데이터를 만들어 보고, 이번 챕터에서는 기본적인 사용법과 주의사항에 대해 알아봅니다.
우선 두 가지를 준비해야 합니다. MySQL (혹은 MySQL-compatible Aurora)
- MySQL 내에 테이블을 만들어야 하고
- Spark 가 쓸 수 있도록 MySQL JDBC Driver 를 Spark Class Path 에 추가해주어야 합니다. (MySQL Driver, Kinesis 와 같이 특정 라이브러리들은 라이센스 및 의존성 확장 이슈로 포함되지 않는 경우가 종종 있습니다)
우선 MySQL JDBC Driver 를 Class Path 에 추가 해보겠습니다. 여러가지 방법이 있지만, 이 섹션에서는 –packages 옵션을 이용해 추가해보도록 하겠습니다.
- MySQL Driver 호환성 가이드 에 따라서 알맞은 버전을 –packages 옵션에 추가하면
- Maven MySQL Driver “mysql:mysql-connector-java:5.1.49”
Spark 에서는 --packages (Maven Pom) 을 이용해 의존성 Jar 전체를 (transitive dependency) 가져올 수 있습니다. 또는 Spark 가 실행되는 Class Path (SPARK_HOME/jars, 일반적으로는 커스텀 경로를 권장) 필요한 의존성 Jar 를 미리 다운받아 로딩할수 있습니다.
두 가지 로딩 방법의 차이점은 무엇일까요? 만약 의존성이 많을 경우를 가정하여 논의해 봅시다.
이제 JDBC 실습을 위해 MySQL 을 로컬에 Docker Compose 를 이용해 띄운 후 아래의 테이블을 생성합니다.
- https://github.com/1ambda/practical-data-pipeline-code/blob/master/docker-compose.storage.yml 의 Docker Compose 파일을 이용할 수 있습니다.
- DB 에 연결해 테이블을 생성하기 위해 https://www.jetbrains.com/datagrip/ 등의 도구를 사용할 수 있습니다.
| CREATE DATABASE pipeline; | |
| USE pipeline; | |
| -- 아래의 테이블은 이해를 돕기 위해 약식으로 생성되었습니다. | |
| -- Production 환경에서 테이블 생성시에는 성능과 스펙을 고려해 DDL 이 작성되며 DBA 의 검수를 거칩니다. | |
| CREATE TABLE `ListingMeta` | |
| ( | |
| -- primary key | |
| `listing_id` BIGINT UNSIGNED NOT NULL PRIMARY KEY, | |
| `listing_name` VARCHAR(200) NULL, | |
| `listing_desc` TEXT NULL, | |
| `listing_summary` TEXT NULL, | |
| `listing_url` TEXT NULL, | |
| -- FK columns | |
| -- common | |
| `created_at` datetime DEFAULT CURRENT_TIMESTAMP NOT NULL | |
| ) ENGINE = InnoDB | |
| DEFAULT CHARSET = utf8mb4 | |
| COLLATE = utf8mb4_unicode_ci; |
Spark 실행시 --packages 옵션을 통해 MySQL Driver 를 다운받았고 DDL 을 실행했다면 이제 다음의 코드를 실행해 봅시다. 실행하면 아래와 같은 오류를 볼 수 있습니다.
| dfListingSelected\ | |
| .repartition(2)\ | |
| .write\ | |
| .mode("append")\ | |
| .format("jdbc")\ | |
| .option("driver", "com.mysql.jdbc.Driver")\ | |
| .option("url", "jdbc:mysql://localhost:3306?useSSL=false")\ | |
| .option("dbtable", "pipeline.ListingMeta")\ | |
| .option("user", "root")\ | |
| .option("password", "root")\ | |
| .option("truncate", "true")\ | |
| .save() |
| Job aborted due to stage failure: Task 0 in stage 60.0 failed 1 times, most recent failure: Lost task 0.0 in stage 60.0 (TID 115) (jupyter executor driver): java.sql.BatchUpdateException: Data truncation: Data too long for column 'listing_name' at row 1 |
이는 위에서 만든 MySQL 테이블 pipeline.ListingMeta 의 listing_name 컬럼이 VARCHAR(200) 타입이고 실제 데이터는 이 타입에 들어갈 수 있는 제한 길이 보다 더 길기 때문입니다. 두 가지 방법으로 해결할 수 있습니다
- 1.RDB
listing_name컬럼을TEXT타입으로 변환합니다 (ALTER TABLE pipeline.ListingMeta MODIFY COLUMN listing_name TEXT;) - 2.Spark 의 DataFrame 의
listing_name컬럼 값의 길이를 자릅니다.
일반적으로 원본 데이터를 복원할 수 없도록 훼손하는 경우는 거의 없습니다. 다만 이 챕터에서는 Spark DataFrame 의 사용법을 익히는 것이 목적이므로 listing_name 컬럼 내 값을 잘라 적재하겠습니다.
| dfListingTruncated = dfListingSelected\ | |
| .withColumn("listing_name", substring(col("listing_name"), 1, 100))\ | |
| .withColumn("listing_name_len", length(col("listing_name"))) | |
| dfListingTruncated.agg(min(col("listing_name_len")), max(col("listing_name_len"))).show() |
| +---------------------+---------------------+ | |
| |min(listing_name_len)|max(listing_name_len)| | |
| +---------------------+---------------------+ | |
| | 4| 100| | |
| +---------------------+---------------------+ |
listing_name_len 컬럼은 저장하지 않으므로 제거하겠습니다.
| dfListingTruncated = dfListingTruncated.drop("listing_name_len") | |
| dfListingTruncated.printSchema() |
| root | |
| |-- listing_id: integer (nullable = true) | |
| |-- listing_url: string (nullable = true) | |
| |-- listing_name: string (nullable = true) | |
| |-- listing_summary: string (nullable = true) | |
| |-- listing_desc: string (nullable = true) |
이제 JDBC Driver 를 이용해 DataFrame 을 저장해보겠습니다.
| dfListingTruncated\ | |
| .repartition(3)\ | |
| .write\ | |
| .mode("append")\ | |
| .format("jdbc")\ | |
| .option("driver", "com.mysql.jdbc.Driver")\ | |
| .option("url", "jdbc:mysql://localhost:3306?useSSL=false")\ | |
| .option("dbtable", "pipeline.ListingMeta")\ | |
| .option("user", "root")\ | |
| .option("password", "root")\ | |
| .option("numPartitions", "2")\ | |
| .option("truncate", "true")\ | |
| .save() |
MySQL Client (mycli, DataGrip 등) 을 이용해 접속해서 데이터를 살펴보면, 잘 적재되었음을 알 수 있습니다.
| MySQL [pipeline]> SELECT listing_id FROM ListingMeta LIMIT 10; | |
| +------------+ | |
| | listing_id | | |
| +------------+ | |
| | 360 | | |
| | 590 | | |
| | 592 | | |
| | 1940 | | |
| | 2086 | | |
| | 31503 | | |
| | 39405 | | |
| | 56185 | | |
| | 59631 | | |
| | 74125 | | |
| +------------+ | |
| 10 rows in set (0.00 sec) |
여기서 꼭 집고 넘어가야 JDBC Write 설정이 있습니다.
- mode 는 기존에 File 을 Write 하는것과 매우 다르게 동작합니다. “overwrite” 를 사용하면 기본설정으로는 Table 을 Drop 하고 DataFrame 의 Schema 를 기반으로 테이블을 다시 생성합니다. 따라서 Index 등 중요한 설정 정보가 삭제될 수 있어서 매우 유의해 사용해야 합니다.
- truncate = True 로 설정시 mode = overwrite 라 하더라도 테이블은 삭제하지 않고 데이터만 삭제합니다. 그러나 여전히 데이터가 통채로 삭제될 수 있어 서비스 중인 DB 에서는 문제가 될 수 있습니다.
- numPartitions 값은 JDBC 커넥션 숫자입니다. 위의 예제에서는 repartition(3) 이고 numPartitions(2) 인 경우이므로, coalesce(2 = numPartitions) 를 통해서 파티션 숫자를 줄인 후 Executor 마다 JDBC Connection 1개씩을 할당해 Write 합니다.
일반적으로는 mode = append 를 이용하고 Update 나 Upsert 가 필요할 경우 다른 방식으로 구현합니다. (foreach 내 직접 Statement 실행 등)
또 한 가지 주의점은 만약 테이블 설계가 병렬 Insert 가 불가능한 경우 Deadlock 이 걸릴 수 있으므로, numPartitions 값을 조정하기 전에 병렬 적재가 가능하도록 테이블이 설계되었는지 확인해야 합니다. 또한 병렬 적재가 가능하도록 테이블 Key 와 Index 가 설계 되었다 하더라도 Repartition 을 해놓지 않거나, RDB Table Key 를 다른 파티션간에 흩어 놓았을 경우에 Deadlock 이 발생할 수 있습니다. 따라서 repartition(5, 'col') 과 같이 병렬 적재가 가능하도록 Key 에 속하는 컬럼을 단일 파티션으로 데이터를 몰아 놓아야 합니다.
이제 JDBC Driver 를 이용해 MySQL 로 적재한 데이터를 다시 읽어 보겠습니다.
| dfListingJdbc = spark\ | |
| .read\ | |
| .format("jdbc")\ | |
| .option("driver", "com.mysql.jdbc.Driver")\ | |
| .option("url", "jdbc:mysql://localhost:3306?useSSL=false")\ | |
| .option("dbtable", "pipeline.ListingMeta")\ | |
| .option("user", "root")\ | |
| .option("password", "root")\ | |
| .option("partitionColumn", "listing_id")\ | |
| .option("lowerBound", "0")\ | |
| .option("upperBound", "1000")\ | |
| .option("fetchsize", "200")\ | |
| .option("customSchema", "listing_id LONG")\ | |
| .option("numPartitions", "5")\ | |
| .load() | |
| dfListingJdbc.printSchema() |
| root | |
| |-- listing_id: long (nullable = true) | |
| |-- listing_name: string (nullable = true) | |
| |-- listing_desc: string (nullable = true) | |
| |-- listing_summary: string (nullable = true) | |
| |-- listing_url: string (nullable = true) | |
| |-- created_at: timestamp (nullable = true) |
JDBC Driver 를 이용한 READ 를 수행할 때 사용한 설정들을 알아봅시다.
- partitionColumn 에 명시된 컬럼을 이용해 numPartitions 숫자만큼 분산처리할 수 있습니다. lowerBound, upperBound 는 각 파티션당 얼마나 많은 데이터를 가져올지 분할량 (파티셔닝) 을 결정합니다.
- partitionColumn 컬럼 타입은 RA numeric (숫자), date, timestamp 값만 가능합니다.
- customSchema 를 이용하면 컬럼별 스키마를 지정할 수 있습니다. Spark 는 RDB 스키마를 Spark 호환 타입으로 변경하나, 일부 지원되지 않는 타입이나 잘못 변경될 경우 사용자는 customSchema 옵션을 이용하거나 직접 DataFrame 에서 cast() 함수를 사용할 수 있습니다.
- fetchsize 는 너무 작으면 여러번 네트워크 통신이 필요하고 너무 많으면 DB 에 부하가 갈 수 있습니다.
위의 코드에서는 전체 컬럼이 약 4800 개이고, 파티션당 최대 1000 이므로 (1000, 1000, 1000, 1000, 약 800개) 로 파티션 당 Row 가 위치하길 바라지만 lowerBound, upperBound 는 갯수가 아니라 값입니다. (중요!) 따라서 실제로 실행된 결과는 의도와는 다를 수 있습니다. 파티션별 Row 숫자를 살펴보면 아래와 같습니다.
| # dfListingJdbc\ | |
| .select(spark_partition_id().alias("partitionId"))\ | |
| .groupBy("partitionId")\ | |
| .count()\ | |
| .show() | |
| +-----------+-----+ | |
| |partitionId|count| | |
| +-----------+-----+ | |
| | 1| 1| | |
| | 4| 4862| | |
| | 2| 2| | |
| +-----------+-----+ |
Write 할 때 .option("upperBound", "10000000") 로 변경하면 다음과 같은 결과가 나옵니다.
| +-----------+-----+ | |
| |partitionId|count| | |
| +-----------+-----+ | |
| | 1| 96| | |
| | 3| 114| | |
| | 4| 4429| | |
| | 2| 113| | |
| | 0| 113| | |
| +-----------+-----+ |
이는 listing_id 값의 범위가, 우리가 지정한 lowerBound, upperBound 로는 해결할 수 없는 특정 구간에 몰려있기 때문입니다. listing_id 값의 범위를 다시 살펴보면 다음과 같습니다.
| # dfListingSelected.agg(min(col("listing_id")), max(col("listing_id"))).show() | |
| +---------------+---------------+ | |
| |min(listing_id)|max(listing_id)| | |
| +---------------+---------------+ | |
| | 360| 40454863| | |
| +---------------+---------------+ |
다음은 몇 가지 생각해볼 점입니다.
- 데이터 사이즈가 점점 늘어가는 테이블에서 고정된
upperBound로 인해 어떤 문제가 나중에 발생할까요? - Executor 의 수를 고정하고 만약 partitionColumn 의 count, min, max 값을 바탕으로 매일 lowerBound, upperBound 를 계산하려면 어떻게 하면 될까요?
- 만약 특정 partitionColumn 값 구간에 데이터가 몰린다면 어떻게 해야할까요?
DB 에 부하가 생기니 2021년 이후 데이터만 필터링 해서 로딩해주세요 등과 같은 요구사항이 있을 경우 WHERE 조건문을 이용해 추가적인 필터링이 필요할 수 있습니다. 다만 option 으로 지정하는 query 는 partitionColumn 과 같이 쓰일 수 없기 때문에 dbtable 옵션을 이용해 보겠습니다.
It is not allowed to specify
https://spark.apache.org/docs/latest/sql-data-sources-jdbc.htmlqueryandpartitionColumnoptions at the same time. When specifyingpartitionColumnoption is required, the subquery can be specified usingdbtableoption instead and partition columns can be qualified using the subquery alias provided as part ofdbtable.
| queryListingJdbc = """(SELECT * FROM pipeline.ListingMeta WHERE listing_id >= 100000) AS target""" | |
| dfListingJdbcFiltered = spark\ | |
| .read\ | |
| .format("jdbc")\ | |
| .option("driver", "com.mysql.jdbc.Driver")\ | |
| .option("url", "jdbc:mysql://localhost:3306?useSSL=false")\ | |
| .option("dbtable", queryListingJdbc)\ | |
| .option("user", "root")\ | |
| .option("password", "root")\ | |
| .option("partitionColumn", "listing_id")\ | |
| .option("lowerBound", "0")\ | |
| .option("upperBound", "1000")\ | |
| .option("customSchema", "listing_id LONG")\ | |
| .option("numPartitions", "5")\ | |
| .load() |
dfListingJdbc.count() 를 실행하면 기존보다 줄어든 4865 > 4851 개임을 알 수 있습니다.
아래의 옵션들도 정말 중요하니, Spark Docs – JDBC Data Source 문서에서 한번 꼭 읽어보시길 권장 드립니다.
- (READ, WRITE) queryTimeout
- (READ, WRITE) query
- (READ) fetchsize
- (READ) pushDownPredicate
- (READ) pushDownAggregate
- (WRITE) batchsize
- (WRITE) isolationLevel
Practice
실습 과제입니다.Airbnb 데이터 셋을 이용해 Spark 로 가공한 뒤 MySQL 에 적재합니다.
- airbnb_listings 데이터와 airbnb_reviews 데이터 를 합쳐 listing 별 리뷰 숫자 및 평균 평점을 가진 DataFrame 을 만들고, airbnb_stat_review 테이블에 적재합니다.
- airbnb_listings 데이터와 airbnb_calendar 데이터를 합쳐 listing 별 예약 숫자와 예약 금액 합 을 월별로 집계해 DataFrame 을 만들고 airbnb_stat_sales_month 테이블에 적재합니다.
컬럼 이름은 자유롭게 지어도 상관 없습니다.
- 단, DataFrame 컬럼 타입은 LONG, DOUBLE, STRING을 사용하며 (월은 ‘2021-11’ 과 같이 문자열로 표현합니다)
- MySQL DDL 에서는 대응되는 BIGINT UNSIGNED, DOUBLE(10, 5), VARCHAR(N) / TEXT 를 사용합니다.
만약 이 데이터를 Parquet 로 저장하거나 Hive Insert Into 를 통해 저장한다면 Hive 의 타입과 매칭이 됩니다. 아래 두가지 문서를 살펴보면서 어떤 타입으로 위 타입들이 매핑될지 고민해 봅시다.
- (Parquet Data Type) http://parquet.apache.org/documentation/latest/
- (Hive Data Type) https://cwiki.apache.org/confluence/display/hive/languagemanual+types
실습을 위해 아래의 환경을 로컬에 구축해 놓으면 편리합니다.
- Docker 를 이용해 MySQL 을 띄워 실행
- DataGrip (https://www.jetbrains.com/datagrip/) 과 같은 데이터 베이스 IDE
- Jupyter 세팅 및 PySpark 설정
- 데이터를 개발할때 빌드 없이 빠르게 Spark Shell 을 활용해 작업해볼 수 있습니다.
- Intellij (https://www.jetbrains.com/idea/) 내 Spark Gradle 프로젝트
- 실제 프로덕션 배포시 사용할 코드를 프로젝트 형식으로 개발할 수 있습니다.
- 완료되면 로컬에서 spark-submit 등의 커맨드를 이용해 Spark Local Mode 로 Jar 를 실행해볼 수 있습니다.
Summary
아래는 이번 챕터에서 다룬 핵심 키워드입니다.
- Save Mode
- Column Pruning
- Predicate Pushdown
- Snappy
- Serialization
- Schema Registry
- Schema Evoluation
- Avro SpecificRecord / GenericRecord
- (JDBC) numPartitions
- (JDBC) lowerBound, upperBound
