Practical 시리즈는 AWS 환경 위에서 데이터 인프라를 구축하는데 참고할만한 내용들을 담고 있습니다. 이 글은 그 중 Practical Spark 의 한 챕터입니다.이번 챕터에서는 Spark 를 이용해 데이터를 더 빠르게 처리하기 위해 캐싱하기 위한 방법과 Spark 내부의 메모리 구조에 대해 알아보며 Spark 의 리소스를 더 효율적으로 처리하기 위한 방법들을 익혀봅니다.

Practical 시리즈는 AWS 환경 위에서 데이터 인프라를 구축하는데 참고할만한 내용들을 담고 있습니다. 아래의 내용들을 주로 다룹니다.
- Practical Spark
- Practical Kafka
- Practical Kubernetes
- Practical AWS
이 블로그에 작성된 내용은 위 시리즈 중 Gitbook 으로 작성된 Practical Spark 를 옮긴 것입니다. 원본 Gitbook 와 실습에 사용하는 코드는 아래의 링크에서 보실 수 있습니다.
- (Spark Batch) https://1ambda.gitbook.io/practical-data-pipeline/02-processing/2.2-batch
- (Spark Stream) https://1ambda.gitbook.io/practical-data-pipeline/02-processing/2.4-stream
- (Code) https://github.com/1ambda/practical-data-pipeline-code
Spark Cache
이번 챕터에서는 Spark 데이터 가공을 빠르고 효율적으로 하기 위한 Cache 기능에 대해 사례를 통해 살펴봅니다.이번시간에 사용할 데이터셋은 Kaggle – Denver AirBNB 입니다.
파일을 다운받은 후 다음과 같이 이름을 변경합니다.
| calendar.csv -> airbnb_calendar.csv | |
| listing.csv -> airbnb_listings.csv | |
| neighbourhoods.csv -> airbnb_neighbourhoods.csv | |
| reviews.csv -> airbnb_reviews.csv |
Cache Usage
지난 챕터들에서 Spark 는 ‘논리적’ 인 수준에서 데이터를 파티션 단위로 나누어 처리한다고 이야기를 나누었습니다. 다시 그림으로 살펴보면 아래와 같습니다.

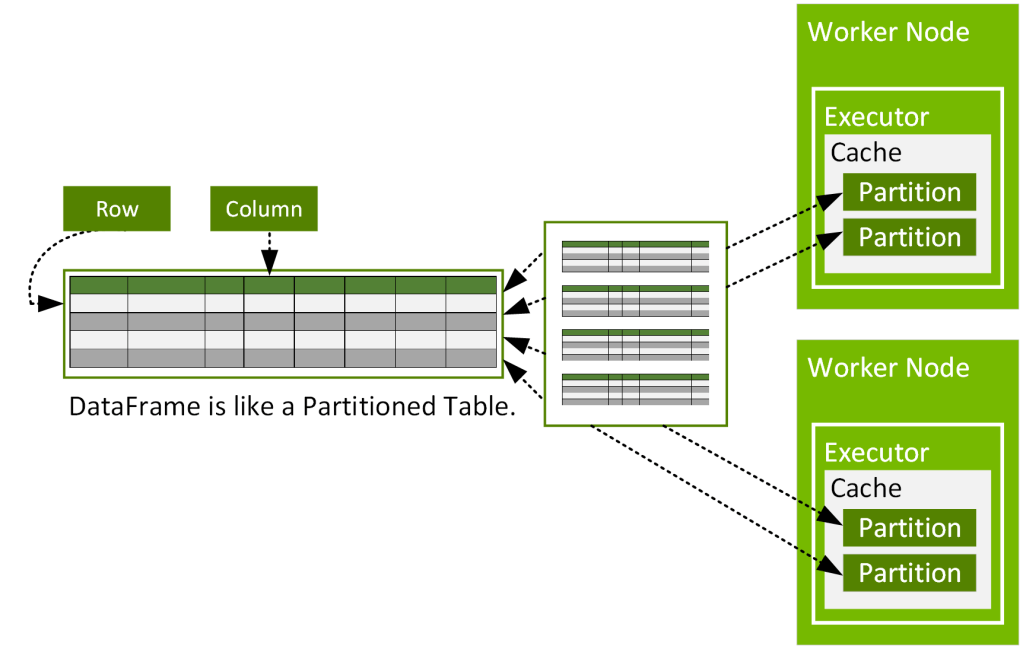
캐싱을 하지 않으면, Spark Executor 는 할당된 Partition 을 읽어 처리하고 메모리에서 데이터를 다 내리지만, 캐싱을 수행하면 두번째 그림과 같이 Executor 내의 메모리 영역중 캐싱을 위해 할당된 영역에 사용자가 요청한 데이터를 캐싱합니다. (용량이 허용하는 한도 내에서 해당 데이터를 메모리에 들고 있습니다.)
여기서 Worker Node 는 EC2 와 같은 개별 머신입니다. 하나의 EC2 에 여러개의 Executor (JVM) 을 실행할 수도 있습니다. 개별 Executor 내의 설정에 의해 허용된 메모리량 만큼 Partition 데이터를 캐싱하는것이 가능하며, BlockManager 에 의해 관리됩니다. 만약 데이터가 메모리에 들어가기 충분하지 않으면 Disk 를 사용할 수 있습니다.
지난시간에 만들었던 airbnb_listing_parquet (200개 파티션) 디렉토리를 읽어서 cache() 함수를 통해 메모리에 데이터를 올려보겠습니다.
만약 해당 디렉토리를 준비하지 않았다면, 다른 데이터를 이용해도 상관 없습니다. 다만 아래에서 실행할 explain() 으로 나오는 Plan 의 결과가 다를 수 있습니다.
| from pyspark.sql.types import * | |
| from pyspark.sql.functions import * | |
| from pyspark.sql.window import Window | |
| df = spark.read.format("parquet").load("./airbnb_listings_parquet") | |
| # Parquet 파일 대신 사용 | |
| df = spark.read.load("./airbnb_listings.csv", | |
| format="csv", inferSchema=True, header=True, | |
| quote='"', escape='"', sep=',', multiline=True) |
| # df.count() | |
| 4865 |
이제 cache() 함수를 사용해보겠습니다. 동일한 데이터에 대해 cache() 를 호출하면
- Spark Executor 내에 분산되어 DataFrame 이 저장됩니다.
- storageLevel 의 기본값은 MEMORY_AND_DISK 이므로 메모리가 부족할 경우 Disk 를 사용할 수 있습니다.
| dfCached = spark.read.format("parquet").load("./airbnb_listings_parquet").cache() | |
| dfCached.count() | |
| dfCached.rdd.getNumPartitions() |
| # dfCached.count() | |
| 4865 | |
| # dfCached.rdd.getNumPartitions() | |
| 197 |
cache() 함수는 persist(storageLevel = MEMORY_AND_DISK) 함수 와 동일합니다. 다른 Storage Level 은 무엇이 있나 찾아보고 논의해 봅시다.
Cache 를 위한 메모리가 부족할 경우 Spark 는 Disk 에 데이터를 저장할 수 있습니다. 이 경우 성능은 어떻게 될까요?
Spark UI 를 확인해보면 다음의 내용을 확인할 수 있습니다.
- Executors 탭에서는 cache() 를 호출하기 이전에 비해 Storage Memory 가 늘었습니다.
- Storage 탭에서는 197 개 만큼의 Cached Partitions 이 7.1 MiB 만큼 메모리에 존재합니다. (이 숫자는 파티션과 동일합니다)
- SQL 탭에서 나오는 두개의 count() Action 을 살펴보면 두번째
count()호출, 즉dfCached.count()에 InMemoryTableScan 이라는 단계가 추가된 것을 볼 수 있습니다.


아래 Spark SQL 내 Plan 을 보여진 Tree 형태의 스크린샷 2개를 비교해봅시다.
- (1번째 스크린샷) Details for Query 0 은
cache()를 호출하지 않은df.count()의 실행 계획입니다 - (2번째 스크린샷) Details for Query 1 은
cache()를 호출한dfCached()의 실행 계획입니다
- InMemoryTableScan 이라는 단계가 추가되었음을 알 수 있습니다
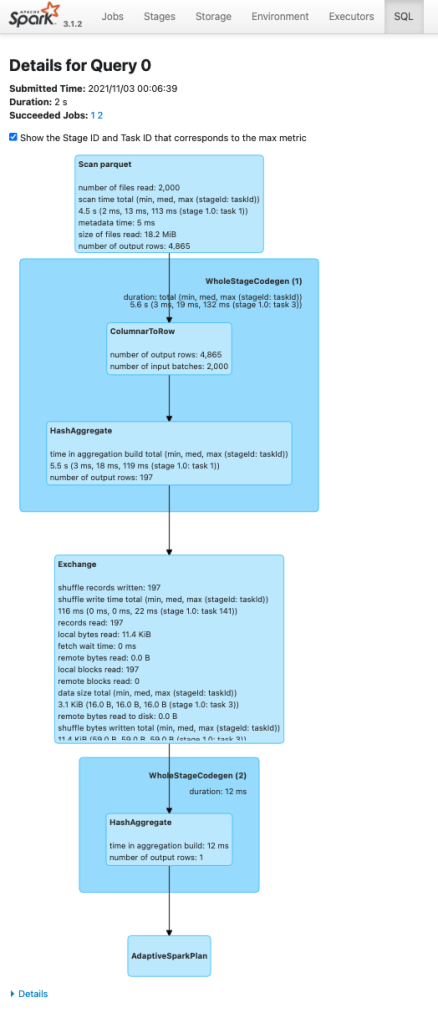
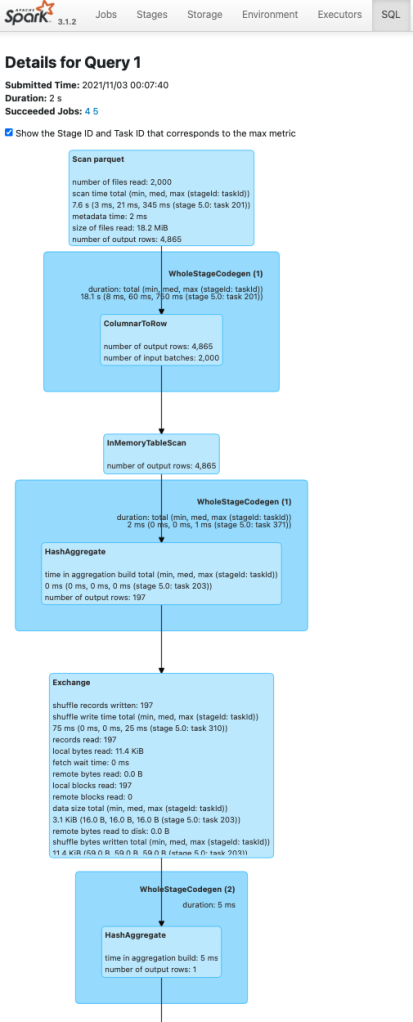
하단의 Details 버튼을 누르거나 explain("FORMATTED") 를 통해 살펴보면 텍스트로 된 실행 계획을 볼 수 있습니다. InMemoryTableScan 을 통해 데이터를 다시 Parquet 로 부터 읽지 않고 메모리에 캐싱된 영역에서 데이터를 읽어 집계합니다.
| == Physical Plan == | |
| InMemoryTableScan (1) | |
| +- InMemoryRelation (2) | |
| +- * ColumnarToRow (4) | |
| +- Scan parquet (3) | |
| (1) InMemoryTableScan | |
| Output [5]: [listing_id#20, listing_url#21, listing_name#22, listing_summary#23, listing_desc#24] | |
| Arguments: [listing_id#20, listing_url#21, listing_name#22, listing_summary#23, listing_desc#24] | |
| (2) InMemoryRelation | |
| Arguments: [listing_id#20, listing_url#21, listing_name#22, listing_summary#23, listing_desc#24], CachedRDDBuilder(org.apache.spark.sql.execution.columnar.DefaultCachedBatchSerializer@286e1e85,StorageLevel(disk, memory, deserialized, 1 replicas),*(1) ColumnarToRow | |
| +- FileScan parquet [listing_id#20,listing_url#21,listing_name#22,listing_summary#23,listing_desc#24] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex[file:/home/1ambda/airbnb_listings_parquet], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<listing_id:int,listing_url:string,listing_name:string,listing_summary:string,listing_desc:... | |
| ,None) | |
| (3) Scan parquet | |
| Output [5]: [listing_id#20, listing_url#21, listing_name#22, listing_summary#23, listing_desc#24] | |
| Batched: true | |
| Location: InMemoryFileIndex [file:/home/1ambda/airbnb_listings_parquet] | |
| ReadSchema: struct<listing_id:int,listing_url:string,listing_name:string,listing_summary:string,listing_desc:string> | |
| (4) ColumnarToRow [codegen id : 1] | |
| Input [5]: [listing_id#20, listing_url#21, listing_name#22, listing_summary#23, listing_desc#24] |
더이상 해당 데이터를 캐싱해서 사용하지 않는다면 unpersist() 함수를 통해 제거할 수 있습니다. 함수를 호출 후에 Spark UI 를 보면, Storage / Executors 탭에서 dfCached DataFrame 이 제거된 것을 볼 수 있습니다.
| dfCached.unpersist() |
하나의 배치 작업이 끝나면 JVM (Executor) 도 제거되므로 DataFrame 을 cache() 한 것도 사라지기 마련입니다. 그런데 왜 unpersist() 함수가 필요할까요? 하나의 배치 작업에서 사용 가능한 메모리가 작은경우와 Notebook 과 같이 오래 띄워놓고 사용하는 케이스를 가정하여 논의해 봅시다.
Cache Memory Configuration
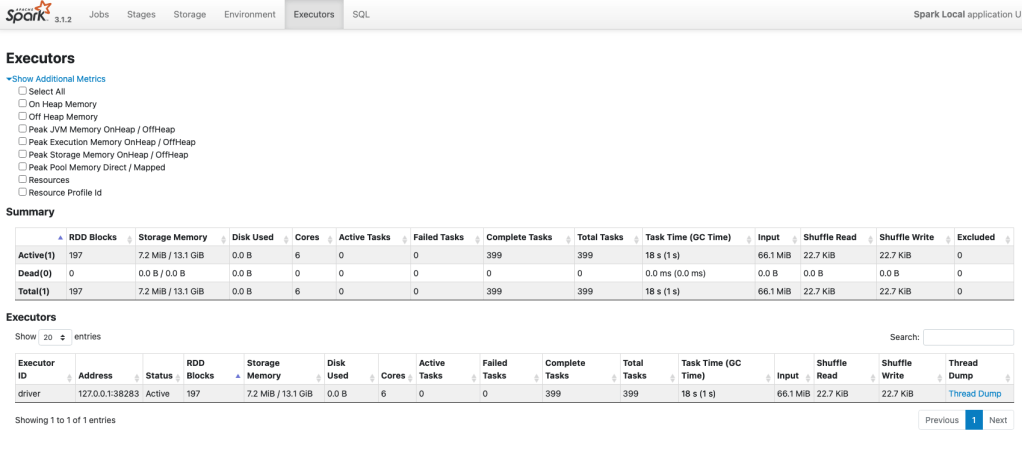
위 스크린샷 내에서 Executors 탭을 다시 보면, Driver 의 Storage 메모리가 13.1 GiB 임을 알 수 있습니다. 사용자가 Spark Driver Memory 를 20g (GiB) 로 지정한것은 알겠는데 어떻게 Storage 메모리로 13.1 GiB 만큼 사용이 가능한 걸까요?
Spark 는 여러 옵션들로 메모리를 조정합니다. 추후에 Spark Memory 챕터에서 더 자세히 살펴 보겠지만 우선 필요한 부분만 알아보도록 하겠습니다.

Spark UI 의 Environment 탭을 살펴보면 다음처럼 메모리 설정을 볼 수 있습니다.
spark.memory.fraction 은 0.6 이 Default 지만, 현재는 0.75 가 세팅되어 있습니다
- spark.memory.fraction 은 Spark 가 집계 (Execution) 및 저장 (Storage) 를 위해 사용할 수 있는 메모리 양을 지정합니다.
spark.memory.storageFraction 은 0.5 가 Default 지만, 현재는 0.2 가 세팅되어 있습니다.
- spark.memory.storageFraction 은 spark.memory.fraction 영역 중에서 저장 (Stroage) 에 사용할 메모리 양을 지정합니다
- 다만 Spark 1.6+ 부터 Unified Memory Management 가 구현되었기에 (SPARK-10000) 엄밀하게 Execution / Storage 로 딱 잘리진 않습니다. 그림에서 화살표가 양방향으로 표기된 것도 위와 같은 이유입니다.
Spark 의 메모리 관련 설정 전체 목록은 다음 링크에서 볼 수 있습니다.
Memory usage in Spark largely falls under one of two categories: execution and storage. Execution memory refers to that used for computation in shuffles, joins, sorts and aggregations, while storage memory refers to that used for caching and propagating internal data across the cluster. In Spark, execution and storage share a unified region (M).
When no execution memory is used, storage can acquire all the available memory and vice versa. Execution may evict storage if necessary, but only until total storage memory usage falls under a certain threshold (R).
In other words, R describes a subregion within M where cached blocks are never evicted. Storage may not evict execution due to complexities in implementation.
https://spark.apache.org/docs/latest/tuning.html#memory-management-overview
문서에 나와있는대로 Driver JVM Heap (20GiB) 에서 300 MiB 만큼을 제외하고 spark.memory.fraction 을 곱해보면 다음과 같이 수식이 나옵니다.
- (전체 JVM 메모리 2048 – Reserved Memory 300) * spark.memory.fraction 0.75 = 1,311
- 약 13.1 GiB 입니다. 이게 바로 Spark UI 에서 보이는 Storage 13.1 GiB 의 값입니다.
Spark 의 spark.memory.fraction 값에 대해서 생각해 봅시다
- spark.memory.fraction 값이 너무 높으면 무슨 일이 발생할까요?
- spark.memory.fraction 값이 너무 낮으면 무슨 일이 발생할까요?
Caching DataFrame
Spark DataFarme 의 cache() 함수를 사용하는 방법과 관련된 설정을 간단히 알아봤습니다.
cache() 는 위에서 소개한 것처럼 읽은 후 캐싱하기만 하는 용도가 아니라 Transformation 이 적용된 경우에도 당연히 사용이 가능합니다. DataFrame 이 제공하는 함수이기 때문입니다. 그러나 이 때는 조금 고려해야 할 부분이 있습니다. 예제를 통해 살펴봅시다.
| # dfCached.printSchema() | |
| root | |
| |-- listing_id: integer (nullable = true) | |
| |-- listing_url: string (nullable = true) | |
| |-- listing_name: string (nullable = true) | |
| |-- listing_summary: string (nullable = true) | |
| |-- listing_desc: string (nullable = true) |
| dfTransformed = dfCached\ | |
| .selectExpr("listing_id", "listing_name")\ | |
| .where(col("listing_id") >= 10000000)\ | |
| .cache() | |
| dfTransformed.count() |
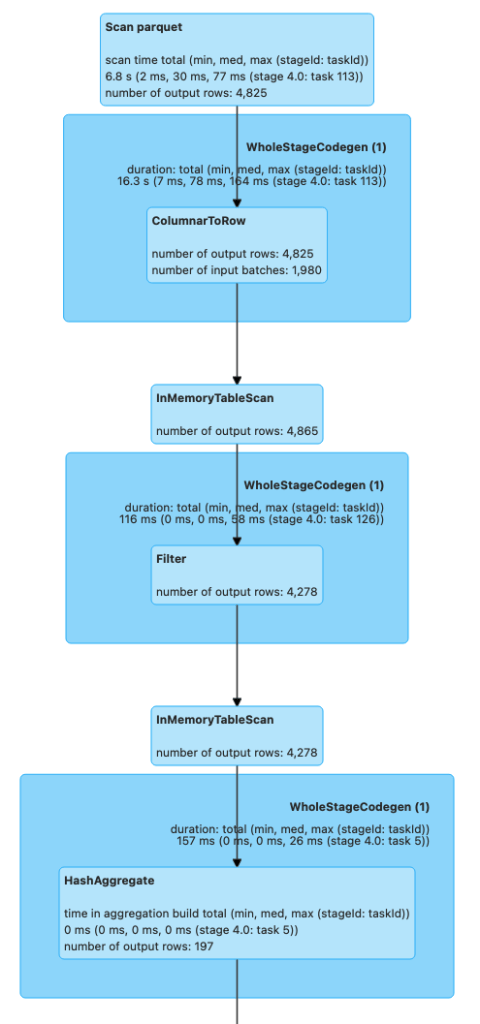
count() 실행 후 Spark UI 의 SQL 탭에서 Plan 을 보면 아래와 같습니다.
| == Physical Plan == | |
| AdaptiveSparkPlan (6) | |
| +- == Final Plan == | |
| * HashAggregate (5) | |
| +- ShuffleQueryStage (4) | |
| +- Exchange (3) | |
| +- * HashAggregate (2) | |
| +- InMemoryTableScan (1) | |
| +- InMemoryRelation (2) | |
| +- * Filter (4) | |
| +- InMemoryTableScan (3) | |
| +- InMemoryRelation (4) | |
| +- * ColumnarToRow (6) | |
| +- Scan parquet (5) | |
| +- == Initial Plan == | |
| HashAggregate (unknown) | |
| +- Exchange (unknown) | |
| +- HashAggregate (unknown) | |
| +- InMemoryTableScan (1) | |
| +- InMemoryRelation (2) | |
| +- * Filter (4) | |
| +- InMemoryTableScan (3) | |
| +- InMemoryRelation (4) | |
| +- * ColumnarToRow (6) | |
| +- Scan parquet (5) | |
| (1) InMemoryTableScan | |
| Output: [] | |
| (2) InMemoryRelation | |
| Arguments: [listing_id#10, listing_name#12], CachedRDDBuilder(org.apache.spark.sql.execution.columnar.DefaultCachedBatchSerializer@df15d03,StorageLevel(disk, memory, deserialized, 1 replicas),*(1) Filter (isnotnull(listing_id#10) AND (listing_id#10 >= 10000000)) | |
| +- InMemoryTableScan [listing_id#10, listing_name#12], [isnotnull(listing_id#10), (listing_id#10 >= 10000000)] | |
| +- InMemoryRelation [listing_id#10, listing_url#11, listing_name#12, listing_summary#13, listing_desc#14], StorageLevel(disk, memory, deserialized, 1 replicas) | |
| +- *(1) ColumnarToRow | |
| +- FileScan parquet [listing_id#10,listing_url#11,listing_name#12,listing_summary#13,listing_desc#14] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex[file:/home/1ambda/airbnb_listings_parquet], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<listing_id:int,listing_url:string,listing_name:string,listing_summary:string,listing_desc:... | |
| ,None) | |
| (3) InMemoryTableScan | |
| Output [2]: [listing_id#10, listing_name#12] | |
| Arguments: [listing_id#10, listing_name#12], [isnotnull(listing_id#10), (listing_id#10 >= 10000000)] | |
| (4) InMemoryRelation | |
| Arguments: [listing_id#10, listing_url#11, listing_name#12, listing_summary#13, listing_desc#14], CachedRDDBuilder(org.apache.spark.sql.execution.columnar.DefaultCachedBatchSerializer@df15d03,StorageLevel(disk, memory, deserialized, 1 replicas),*(1) ColumnarToRow | |
| +- FileScan parquet [listing_id#10,listing_url#11,listing_name#12,listing_summary#13,listing_desc#14] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex[file:/home/1ambda/airbnb_listings_parquet], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<listing_id:int,listing_url:string,listing_name:string,listing_summary:string,listing_desc:... | |
| ,None) |
dfTransformed.explain("FORMATTED") 로 Plan 을 보면 위와 같이
dfCached로 InMemoryRelation (4) 이 만들어지고dfTransformation으로 InMemoryRelation (2) 가 만들어집니다.
dfTransformation 을 이용해보면, InMemoryTableScan (1) 이 dfTransformation 즉, InMemoryRelation(2) 에서 필요한 Select 만 수행하는 것을 볼 수 있습니다. (InMemoryRelation 은 메모리에 캐싱되어 있는 DataFrame 을 지칭한다고 이해하셔도 당장은 무방합니다)
| dfTransformed.select("listing_id").explain("FORMATTED") | |
| == Physical Plan == | |
| InMemoryTableScan (1) | |
| +- InMemoryRelation (2) | |
| +- * Filter (4) | |
| +- InMemoryTableScan (3) | |
| +- InMemoryRelation (4) | |
| +- * ColumnarToRow (6) | |
| +- Scan parquet (5) | |
| (1) InMemoryTableScan | |
| Output [1]: [listing_id#10] | |
| Arguments: [listing_id#10] |
예제를 조금 변경해서 listing_id >= 30000000 인 경우에 대해 cache() 를 호출해보겠습니다. 그리고 변수를 저장하지 않고 사용해보겠습니다.
| dfCached.selectExpr("listing_id", "listing_name").where(col("listing_id") >= 30000000).cache() | |
| dfCached.selectExpr("listing_id", "listing_name").where(col("listing_id") >= 30000000).select("listing_id").explain("FORMATTED") |
| == Physical Plan == | |
| InMemoryTableScan (1) | |
| +- InMemoryRelation (2) | |
| +- * Filter (4) | |
| +- InMemoryTableScan (3) | |
| +- InMemoryRelation (4) | |
| +- * ColumnarToRow (6) | |
| +- Scan parquet (5) | |
| (1) InMemoryTableScan | |
| Output [1]: [listing_id#10] | |
| Arguments: [listing_id#10] | |
| (2) InMemoryRelation | |
| Arguments: [listing_id#10, listing_name#12], CachedRDDBuilder(org.apache.spark.sql.execution.columnar.DefaultCachedBatchSerializer@df15d03,StorageLevel(disk, memory, deserialized, 1 replicas),*(1) Filter (isnotnull(listing_id#10) AND (listing_id#10 >= 30000000)) | |
| +- InMemoryTableScan [listing_id#10, listing_name#12], [isnotnull(listing_id#10), (listing_id#10 >= 30000000)] | |
| +- InMemoryRelation [listing_id#10, listing_url#11, listing_name#12, listing_summary#13, listing_desc#14], StorageLevel(disk, memory, deserialized, 1 replicas) | |
| +- *(1) ColumnarToRow | |
| +- FileScan parquet [listing_id#10,listing_url#11,listing_name#12,listing_summary#13,listing_desc#14] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex[file:/home/1ambda/airbnb_listings_parquet], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<listing_id:int,listing_url:string,listing_name:string,listing_summary:string,listing_desc:... | |
| ,None) |
Plan 을 자세히 보면
dfCached.selectExpr("listing_id", "listing_name").where(col("listing_id") >= 30000000).cache()의 결과를- DataFrame 으로 저장하지 않아도 캐싱이 (예정) 된 것을 볼 수 있습니다. 다만 Storage 탭을 보면 아직 저장된 RDD 가 없습니다. 이는 캐싱이 실제 수행되지 않은 상황인데 Action 을 호출하지 않았기 때문입니다.
다음 코드를 실행해보면 Stroage 탭에 DataFrame 이 등록되는 것을 볼 수 있습니다.
| dfCached\ | |
| .selectExpr("listing_id", "listing_name")\ | |
| .where(col("listing_id") >= 30000000)\ | |
| .select("listing_id")\ | |
| .count() |
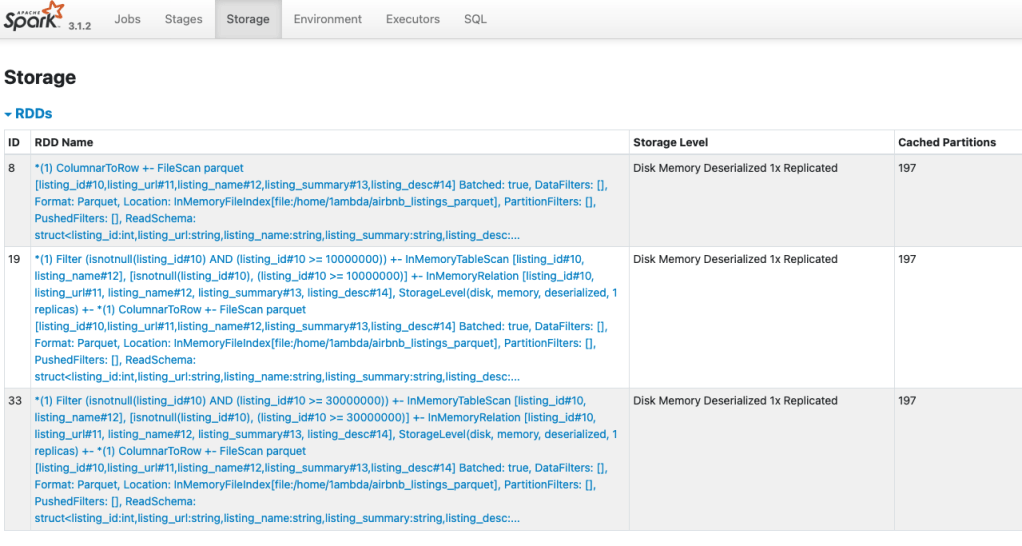
여기서 알 수 있는 사실은 cache() 를 호출하는것 만으로도 현재까지의 Transformation 이 적용된 DataFrame 이 캐싱된다는 것입니다. 그렇다면 아래의 코드를 실행하면 캐싱이 적용될까요?
| dfCached\ | |
| .selectExpr("listing_id")\ | |
| .where(col("listing_id") >= 40000000\ | |
| .select("listing_id")\ | |
| .explain("FORMATTED") |
| == Physical Plan == | |
| * Filter (2) | |
| +- InMemoryTableScan (1) | |
| +- InMemoryRelation (2) | |
| +- * ColumnarToRow (4) | |
| +- Scan parquet (3) | |
| (1) InMemoryTableScan | |
| Output [1]: [listing_id#10] | |
| Arguments: [listing_id#10], [isnotnull(listing_id#10), (listing_id#10 >= 20000000)] | |
| (2) InMemoryRelation | |
| Arguments: [listing_id#10, listing_url#11, listing_name#12, listing_summary#13, listing_desc#14], CachedRDDBuilder(org.apache.spark.sql.execution.columnar.DefaultCachedBatchSerializer@df15d03,StorageLevel(disk, memory, deserialized, 1 replicas),*(1) ColumnarToRow | |
| +- FileScan parquet [listing_id#10,listing_url#11,listing_name#12,listing_summary#13,listing_desc#14] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex[file:/home/1ambda/airbnb_listings_parquet], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<listing_id:int,listing_url:string,listing_name:string,listing_summary:string,listing_desc:... | |
| ,None) |
Plan 을 보면 기존에 캐싱해 두었던 2 개의 DataFrame 이 전혀 사용되지 않은 것을 볼 수 있습니다.
| dfTransformed = dfCached\ | |
| .selectExpr("listing_id", "listing_name")\ | |
| .where(col("listing_id") >= 10000000).cache() | |
| dfCached\ | |
| .selectExpr("listing_id", "listing_name")\ | |
| .where(col("listing_id") >= 30000000).cache() |
얼핏 생각하면 listing_id >= 10000000 인 경우인 집합이 listing_id >= 30000000 인 집합을 포함하므로, 캐싱된 dfTransformed 을 충분히 이용할 것 같지만 실제로는 그렇지 않습니다.
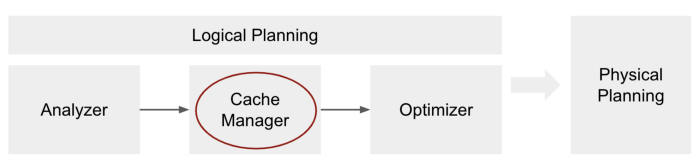
Spark 실행 계획중 논리 실행 계획이 만들어지는 단계에서 Optimizer (최적화 단계) 보다 Cache Manager 가 더 먼저 동작하기 때문입니다. Spark 는 최적화된 Transformation 을 이용해 Cache 를 어떻게 사용할지를 결정하는것이 아니라 Cache 를 사용한 그 이후에 최적화 한다고 볼 수 있습니다.
따라서 캐싱을 사용하려면 cache() 를 호출한 결과 DataFrame 을 변수에 저장해 사용하는 편이 위와 같은 실수를 방지할 수 있습니다.
Spark SQL and Cache
DataFrame 의 createOrReplaceTempView() 를 이용하면 DataFrame 을 View 로 등록하고 spark.sql API 에서 테이블과 같이 FROM 구문에 사용할 수 있습니다.
이렇게 등록된 View 또한 DataFrame 과 동일하게 캐싱할 수 있습니다.
| df.createOrReplaceTempView("RAW") | |
| spark.sql("SELECT * FROM RAW LIMIT 10").show() |
| +----------+--------------------+--------------------+--------------------+--------------------+ | |
| |listing_id| listing_url| listing_name| listing_summary| listing_desc| | |
| +----------+--------------------+--------------------+--------------------+--------------------+ | |
| | 12276698|https://www.airbn...|Downtown Casa in ...|Built in (Phone n...|Built in (Phone n...| | |
| | 39589825|https://www.airbn...|Comfy Stapleton c...| null| null| | |
| | 16676955|https://www.airbn...|Adorable Row Home...|Updated Spanish s...|Updated Spanish s...| | |
| | 38638676|https://www.airbn...|Amenity Rich LUX ...| null| null| | |
| | 33396764|https://www.airbn...|NE Dnvr Home 3br/...| null| null| | |
| | 9842499|https://www.airbn...|Lg Light Bsmnt in...|Dbl BR and den w/...|Dbl BR and den w/...| | |
| | 39150452|https://www.airbn...|Modern Chic Apart...| null| null| | |
| | 39175439|https://www.airbn...|The Highlands Ret...|I live in a very ...|I live in a very ...| | |
| | 35226322|https://www.airbn...|Mountain Views in...|Located in RiNO, ...|Located in RiNO, ...| | |
| | 32902010|https://www.airbn...|Bright Cozy Room ...| null| null| | |
| +----------+--------------------+--------------------+--------------------+--------------------+ |
CACHE TABLE 을 이용하면, DataFrame.cache() 와는 다르게 즉시 캐싱됩니다. Spark UI 의 Storage 탭에서 확인할 수 있습니다. 복잡한 Transformation 식 대신 View 이름으로 (RAW_CACHED) 나오는것도 차이점입니다.
| spark.sql(""" | |
| CACHE TABLE RAW_CACHED AS SELECT * FROM RAW | |
| """) |

CACHE LAZY TABLE 구문을 이용하면 즉시 캐싱하지 않고 Action 이 수행될때 스토리지에 DataFrame 의 데이터를 저장할 수 있습니다.
| spark.sql(""" | |
| CACHE LAZY TABLE RAW_CACHED_LAZY AS SELECT * FROM RAW WHERE listing_id >= 20000000 | |
| """) | |
| spark.sql("SELECT * FROM RAW_CACHED_LAZY").explain("FORMATTED") |
| == Physical Plan == | |
| Scan In-memory table RAW_CACHED_LAZY (1) | |
| +- InMemoryRelation (2) | |
| +- * Filter (4) | |
| +- InMemoryTableScan (3) | |
| +- InMemoryRelation (4) | |
| +- * ColumnarToRow (6) | |
| +- Scan parquet (5) | |
| (1) Scan In-memory table RAW_CACHED_LAZY | |
| Output [5]: [listing_id#1349, listing_url#1350, listing_name#1351, listing_summary#1352, listing_desc#1353] | |
| Arguments: [listing_id#1349, listing_url#1350, listing_name#1351, listing_summary#1352, listing_desc#1353] | |
| (2) InMemoryRelation | |
| Arguments: [listing_id#1349, listing_url#1350, listing_name#1351, listing_summary#1352, listing_desc#1353], CachedRDDBuilder(org.apache.spark.sql.execution.columnar.DefaultCachedBatchSerializer@df15d03,StorageLevel(disk, memory, deserialized, 1 replicas),*(1) Filter (isnotnull(listing_id#0) AND (listing_id#0 >= 20000000)) | |
| +- InMemoryTableScan [listing_id#0, listing_url#1, listing_name#2, listing_summary#3, listing_desc#4], [isnotnull(listing_id#0), (listing_id#0 >= 20000000)] | |
| +- InMemoryRelation [listing_id#0, listing_url#1, listing_name#2, listing_summary#3, listing_desc#4], StorageLevel(disk, memory, deserialized, 1 replicas) | |
| +- *(1) ColumnarToRow | |
| +- FileScan parquet [listing_id#10,listing_url#11,listing_name#12,listing_summary#13,listing_desc#14] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex[file:/home/1ambda/airbnb_listings_parquet], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<listing_id:int,listing_url:string,listing_name:string,listing_summary:string,listing_desc:... | |
| ,Some(RAW_CACHED_LAZY)) |
UNCACHE TABLE 구문을 이용하면 위에서 맏는 View 에 대한 캐싱을 제거할 수 있습니다. 만약 캐싱된 데이터 전체를 삭제하고 싶다면 CLEAR CACHE 구문을 이용하면 됩니다. CLEAR CACHE 구문은 DataFrame.cache() 로 등록된 내용도 같이 제거합니다.
| spark.sql(""" | |
| UNCACHE TABLE IF EXISTS RAW_CACHED | |
| """) | |
| spark.sql(""" | |
| CLEAR CACHE | |
| """) | |
| # 뷰 제거 | |
| spark.catalog.dropTempView("RAW") |
캐싱을 수행하면 Executor 내 Partition 이 Executor 의 메모리에 올라갑니다. 따라서 데이터 사이즈만큼 메모리가 필요합니다. 일반적으로 어떤 경우에 캐싱을 사용할까요? 다음 두 가지 경우를 고려해봅시다.
- 데이터가 크고 Cadinality 가 높은 사용자 이벤트 (ecommerce_event.csv)
- 데이터가 상대적으로 작고 메타 데이터인 Property 정보 테이블 (airbnb_listings.csv)
Practice
실습 과제입니다.
Spark Memory Implementation 리서치
- Unified Memory Management (SPARK-10000) PDF 를 읽어보며 Spark 1.6 이전과 이후에 Memory 영역이 어떻게 바뀌었는지 알아봅시다.
- Storage 영역과 Execution 영역이 회수될때는 각각 어떤 제한점이 존재하는지도 이야기 해 봅시다.
Summary
아래는 이번 챕터에서 다룬 핵심 키워드입니다.
- Storage Level
- persist(), cache()
- Execution Memory, Storage Memory
- spark.memory.fraction
- spark.memory.storageFraction
- JVM: Heap, Off-heap
- Spark Cache Manager
- Table vs View
