Practical 시리즈는 AWS 환경 위에서 데이터 인프라를 구축하는데 참고할만한 내용들을 담고 있습니다. 이 글은 그 중 Practical Spark 의 한 챕터입니다. 이번 챕터에서는 Spark SQL 을 이용해 데이터를 가공하는 방법과 Table 을 만들기 위한 기반 기술들인 Partition 과 Metastore 대해 이야기를 나누어봅니다. Table 생성시 Spark DataSource Format, Hive Data Format 에 대한 차이에 대해 알아보고…

Practical 시리즈는 AWS 환경 위에서 데이터 인프라를 구축하는데 참고할만한 내용들을 담고 있습니다. 아래의 내용들을 주로 다룹니다.
- Practical Spark
- Practical Kafka
- Practical Kubernetes
- Practical AWS
이 블로그에 작성된 내용은 위 시리즈 중 Gitbook 으로 작성된 Practical Spark 를 옮긴 것입니다. 원본 Gitbook 와 실습에 사용하는 코드는 아래의 링크에서 보실 수 있습니다.
- (Spark Batch) https://1ambda.gitbook.io/practical-data-pipeline/02-processing/2.2-batch
- (Spark Stream) https://1ambda.gitbook.io/practical-data-pipeline/02-processing/2.4-stream
- (Code) https://github.com/1ambda/practical-data-pipeline-code
Spark SQL & Table
Spark SQL 로 테이블을 다루기 위한 Hive Metastore / Partition 등의 개념과 API 에 대해 알아봅니다.사용할 데이터는 AirBnB Denver 데이터셋 중 airbnb_calendar.csv 와 airbnb_listings.csv 입니다.
airbnb_listings.csv는 AirBnB 숙소의 메타 정보를 담고 있습니다airbnb_calendar.csv는 AirBnB 숙소의 특정 일자별 가격과 투숙일 정보를 담고 있습니다
| from pyspark.sql.types import * | |
| from pyspark.sql.functions import * | |
| from pyspark.sql.window import Window | |
| dfCalendar = spark.read.load("./airbnb_calendar.csv", | |
| format="csv", inferSchema=True, header=True, | |
| quote='"', escape='"', sep=',', multiline=True) | |
| dfListing = spark.read.load("./airbnb_listings.csv", | |
| format="csv", inferSchema=True, header=True, | |
| quote='"', escape='"', sep=',', multiline=True) | |
| dfCalendar = dfCalendar.cache() | |
| dfListing = dfListing.cache() | |
| dfCalendar.printSchema() | |
| dfCalendar.show() | |
| dfListing.printSchema() | |
| dfListing\ | |
| .select("id", "listing_url", "name", "description", "property_type", "city", "review_scores_rating", "price")\ | |
| .show() |
dfCalendar 와 dfListing 의 스키마와 샘플 데이터를 살펴보겠습니다.
| # dfCalendar.printSchema() | |
| root | |
| |-- listing_id: integer (nullable = true) | |
| |-- date: string (nullable = true) | |
| |-- available: string (nullable = true) | |
| |-- price: string (nullable = true) | |
| |-- adjusted_price: string (nullable = true) | |
| |-- minimum_nights: integer (nullable = true) | |
| |-- maximum_nights: integer (nullable = true) | |
| dfCalendar.show() | |
| +----------+----------+---------+-------+--------------+--------------+--------------+ | |
| |listing_id| date|available| price|adjusted_price|minimum_nights|maximum_nights| | |
| +----------+----------+---------+-------+--------------+--------------+--------------+ | |
| | 1153002|2019-11-29| f|$145.00| $145.00| 30| 60| | |
| | 3138055|2019-11-29| f|$130.00| $130.00| 2| 1125| | |
| | 3138055|2019-11-30| f|$130.00| $130.00| 2| 1125| | |
| | 3138055|2019-12-01| t|$130.00| $130.00| 2| 1125| | |
| | 3138055|2019-12-02| f|$130.00| $130.00| 2| 1125| | |
| | 3138055|2019-12-03| f|$130.00| $130.00| 2| 1125| | |
| | 3138055|2019-12-04| f|$130.00| $130.00| 2| 1125| | |
| | 3138055|2019-12-05| f|$130.00| $130.00| 2| 1125| | |
| | 3138055|2019-12-06| f|$130.00| $130.00| 2| 1125| | |
| | 3138055|2019-12-07| f|$130.00| $130.00| 2| 1125| | |
| | 3138055|2019-12-08| f|$130.00| $130.00| 2| 1125| | |
| | 3138055|2019-12-09| f|$130.00| $130.00| 2| 1125| | |
| | 3138055|2019-12-10| f|$130.00| $130.00| 2| 1125| | |
| | 3138055|2019-12-11| f|$130.00| $130.00| 2| 1125| | |
| | 3138055|2019-12-12| f|$130.00| $130.00| 2| 1125| | |
| | 3138055|2019-12-13| t|$130.00| $130.00| 2| 1125| | |
| | 3138055|2019-12-14| t|$130.00| $130.00| 2| 1125| | |
| | 3138055|2019-12-15| t|$130.00| $130.00| 2| 1125| | |
| | 3138055|2019-12-16| f|$130.00| $130.00| 2| 1125| | |
| | 3138055|2019-12-17| f|$130.00| $130.00| 2| 1125| | |
| +----------+----------+---------+-------+--------------+--------------+--------------+ |
| # dfListing.printSchema() | |
| root | |
| |-- id: integer (nullable = true) | |
| |-- listing_url: string (nullable = true) | |
| |-- scrape_id: long (nullable = true) | |
| |-- last_scraped: string (nullable = true) | |
| |-- name: string (nullable = true) | |
| |-- summary: string (nullable = true) | |
| |-- space: string (nullable = true) | |
| |-- description: string (nullable = true) | |
| |-- experiences_offered: string (nullable = true) | |
| |-- neighborhood_overview: string (nullable = true) | |
| |-- notes: string (nullable = true) | |
| |-- transit: string (nullable = true) | |
| |-- access: string (nullable = true) | |
| |-- interaction: string (nullable = true) | |
| |-- house_rules: string (nullable = true) | |
| |-- thumbnail_url: string (nullable = true) | |
| |-- medium_url: string (nullable = true) | |
| |-- picture_url: string (nullable = true) | |
| |-- xl_picture_url: string (nullable = true) | |
| |-- host_id: integer (nullable = true) | |
| |-- host_url: string (nullable = true) | |
| |-- host_name: string (nullable = true) | |
| ... | |
| # dfListing\ | |
| # .select("id", "listing_url", "name", "description", "property_type", "city", "review_scores_rating", "price")\ | |
| # .show() | |
| +------+--------------------+--------------------+--------------------+-------------+---------+--------------------+-------+ | |
| | id| listing_url| name| description|property_type| city|review_scores_rating| price| | |
| +------+--------------------+--------------------+--------------------+-------------+---------+--------------------+-------+ | |
| | 360|https://www.airbn...|LoHi Secret garde...|Come enjoy our oa...| Guesthouse| Denver| 100|$140.00| | |
| | 590|https://www.airbn...|Comfortable - an...|Large guest room ...| House| Denver| 97| $61.00| | |
| | 592|https://www.airbn...| private|This room is in t...| House| Denver| 97| $44.00| | |
| | 1940|https://www.airbn...|Baker Studio Clos...|Great place for a...| Guesthouse| Denver| 99| $95.00| | |
| | 2086|https://www.airbn...| Garden Level Condo|A furnished, gard...| Apartment| Denver| 96| $76.00| | |
| | 31503|https://www.airbn...|Highland Park Gue...|Highland Park Gue...| Guest suite| Denver| 98|$110.00| | |
| | 39405|https://www.airbn...|LoHi Secret garde...|Come enjoy our oa...| Cottage| Denver| 98|$111.00| | |
| | 56185|https://www.airbn...|charming home for...|Spend time in Den...| House| Denver| 98|$300.00| | |
| | 59631|https://www.airbn...|VICTORIAN TOWNHOM...|License #2017-BFN...| Townhouse| Denver| 96|$179.00| | |
| | 74125|https://www.airbn...|Spacious Cap Hill...|1000' entire-firs...| Apartment| Denver| 94|$130.00| | |
| | 81540|https://www.airbn...|Affordable S. Den...|Bright, sunny 1 b...| Guesthouse|Englewood| 98| $75.00| | |
| | 90307|https://www.airbn...|Comfy King Size R...|This private bedr...| House| Denver| 98| $90.00| | |
| | 98008|https://www.airbn...|Beautiful sun fil...|Locaton, location...| House| Denver| 99| $70.00| | |
| | 98014|https://www.airbn...|Beautiful single ...|Hi Folks! Welcom...| House| Denver| 98| $60.00| | |
| |142683|https://www.airbn...|Historic Denver C...|One of three cond...| House| Denver| 94|$125.00| | |
| |172196|https://www.airbn...|Luxury Wash Park ...|Remodeled wash pa...| House| Denver| 99|$411.00| | |
| |184529|https://www.airbn...|HIP SUITE IN WES...|Private SUIITE ...| Guest suite| Denver| 97| $35.00| | |
| |192430|https://www.airbn...|TREETOP VIEW ROOM...|Located in the de...| Condominium| Denver| 94| $32.00| | |
| |217996|https://www.airbn...| Highland Snug|Comfortable and c...| Condominium| Denver| 100| $66.00| | |
| |236207|https://www.airbn...|Denver Penthouse ...|Important Note : ...| Loft| Denver| 99|$235.00| | |
| +------+--------------------+--------------------+--------------------+-------------+---------+--------------------+-------+ |
SQL and Table API
지난 챕터에서 언급한바와 같이 Spark DataFrame API 는 Spark SQL 을 통해서도 사용 가능합니다.
- createOrReplaceTempView 를 통해 DataFrame 을 View 로 등록해 SQL 구문에서 사용할 수 있고 (spark.catalog.DropView 를 통해 제거)
- 일반적인 연산을 위한 SQL Function 이나 Window Function 은 물론 Array, Map, JSON 과 같은 다양한 타입과 그를 위한 함수들도 제공합니다.
- 필요하다면 사용자 정의 함수 (User Defined Function, UDF) 를 등록해 SQL 구문 내에서 사용하는 것이 가능하며
- DataFrame.cache() 와 같은 인프라 수준의 기능도 CACHE TABLE 구문을 통해 지원합니다.
Spark SQL 을 실습해보며 기본적인 사용법을 익혀보겠습니다. DataFrame.createOrReplaceTempView() 함수를 통해 DataFrame 을 View 로 등록해 SQL 내에서 테이블처럼 사용할 수 있습니다.
- 더 엄밀히는, DataFrame 에 대한 in-memory Reference 를 만듭니다
- 즉, 테이블을 생성하는 것이 아니라 View (테이블처럼 보이지만 실제로는 연산이 필요한) 를 만듭니다
| dfListing.createOrReplaceTempView("LISTING_META") | |
| dfCalendar.createOrReplaceTempView("LISTING_CALENDAR") | |
| spark.sql(""" | |
| SELECT id, listing_url, name, property_type | |
| FROM LISTING_META | |
| LIMIT 10 | |
| """).show() | |
| spark.sql(""" | |
| SELECT * | |
| FROM LISTING_CALENDAR | |
| LIMIT 10 | |
| """).show() |
| +-----+--------------------+--------------------+-------------+ | |
| | id| listing_url| name|property_type| | |
| +-----+--------------------+--------------------+-------------+ | |
| | 360|https://www.airbn...|LoHi Secret garde...| Guesthouse| | |
| | 590|https://www.airbn...|Comfortable - an...| House| | |
| | 592|https://www.airbn...| private| House| | |
| | 1940|https://www.airbn...|Baker Studio Clos...| Guesthouse| | |
| | 2086|https://www.airbn...| Garden Level Condo| Apartment| | |
| |31503|https://www.airbn...|Highland Park Gue...| Guest suite| | |
| |39405|https://www.airbn...|LoHi Secret garde...| Cottage| | |
| |56185|https://www.airbn...|charming home for...| House| | |
| |59631|https://www.airbn...|VICTORIAN TOWNHOM...| Townhouse| | |
| |74125|https://www.airbn...|Spacious Cap Hill...| Apartment| | |
| +-----+--------------------+--------------------+-------------+ | |
| +----------+----------+---------+-------+--------------+--------------+--------------+ | |
| |listing_id| date|available| price|adjusted_price|minimum_nights|maximum_nights| | |
| +----------+----------+---------+-------+--------------+--------------+--------------+ | |
| | 1153002|2019-11-29| f|$145.00| $145.00| 30| 60| | |
| | 3138055|2019-11-29| f|$130.00| $130.00| 2| 1125| | |
| | 3138055|2019-11-30| f|$130.00| $130.00| 2| 1125| | |
| | 3138055|2019-12-01| t|$130.00| $130.00| 2| 1125| | |
| | 3138055|2019-12-02| f|$130.00| $130.00| 2| 1125| | |
| | 3138055|2019-12-03| f|$130.00| $130.00| 2| 1125| | |
| | 3138055|2019-12-04| f|$130.00| $130.00| 2| 1125| | |
| | 3138055|2019-12-05| f|$130.00| $130.00| 2| 1125| | |
| | 3138055|2019-12-06| f|$130.00| $130.00| 2| 1125| | |
| | 3138055|2019-12-07| f|$130.00| $130.00| 2| 1125| | |
| +----------+----------+---------+-------+--------------+--------------+--------------+ |
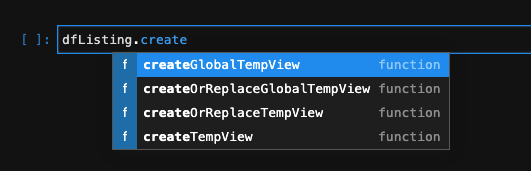
Jupyter 에서 자동완성을 통해 DataFrame 이 지원하는 함수를 보면 ‘GlobalTempView‘ 라는것이 보입니다.
- createTempView, createOrReplaceTempView 를 통해 만든 View 는 해당 Spark Session 내에서 사용이 가능합니다
- 하지만 Global 로 만들면 서로 다른 Spark Session 간 공유가 가능합니다.
SubQuery 이용하면 SELECT * FROM (SELECT ..) 와 같이 중첩되어 가독성이 떨어지고 유지보수가 힘듭니다. 아래 예제에서는 WITH 구문을 이용해 SubQuery 에 이름을 붙여 편리하고 읽기 쉽게 사용할 수 있습니다.대부분의 SQL 에서 WITH 구문을 지원합니다. Spark SQL 은 Hive 와 호환되므로 Spark SQL 에서도 당연히 WITH 구문을 이용할 수 있습니다.
| propertyTypeHouse = 'House' | |
| dfListingHouseAvailable = spark.sql(f""" | |
| WITH | |
| LISTING_HOUSE AS ( | |
| SELECT id as listing_id, listing_url, name | |
| FROM LISTING_META | |
| WHERE property_type = '{propertyTypeHouse}' | |
| ) | |
| SELECT | |
| LISTING_CALENDAR.listing_id, | |
| listing_url, | |
| name as listing_name, | |
| date, | |
| available, | |
| price | |
| FROM LISTING_CALENDAR | |
| INNER JOIN LISTING_HOUSE | |
| ON LISTING_CALENDAR.listing_id = LISTING_HOUSE.listing_id | |
| WHERE LISTING_CALENDAR.available = 't' | |
| """) |
| # dfListingHouseAvailable.show() | |
| +----------+--------------------+--------------------+----------+---------+-------+ | |
| |listing_id| listing_url| listing_name| date|available| price| | |
| +----------+--------------------+--------------------+----------+---------+-------+ | |
| | 3138055|https://www.airbn...|Classic Home on C...|2019-12-01| t|$130.00| | |
| | 3138055|https://www.airbn...|Classic Home on C...|2019-12-13| t|$130.00| | |
| | 3138055|https://www.airbn...|Classic Home on C...|2019-12-14| t|$130.00| | |
| | 3138055|https://www.airbn...|Classic Home on C...|2019-12-15| t|$130.00| | |
| | 3138055|https://www.airbn...|Classic Home on C...|2019-12-21| t|$130.00| | |
| | 3138055|https://www.airbn...|Classic Home on C...|2019-12-22| t|$130.00| | |
| | 3138055|https://www.airbn...|Classic Home on C...|2019-12-26| t|$130.00| | |
| | 3138055|https://www.airbn...|Classic Home on C...|2019-12-27| t|$130.00| | |
| | 3138055|https://www.airbn...|Classic Home on C...|2019-12-28| t|$130.00| | |
| | 3138055|https://www.airbn...|Classic Home on C...|2019-12-29| t|$130.00| | |
| | 3138055|https://www.airbn...|Classic Home on C...|2020-01-03| t|$130.00| | |
| | 3138055|https://www.airbn...|Classic Home on C...|2020-01-04| t|$130.00| | |
| | 3138055|https://www.airbn...|Classic Home on C...|2020-01-05| t|$130.00| | |
| | 3138055|https://www.airbn...|Classic Home on C...|2020-01-10| t|$130.00| | |
| | 3138055|https://www.airbn...|Classic Home on C...|2020-01-11| t|$130.00| | |
| | 3138055|https://www.airbn...|Classic Home on C...|2020-01-12| t|$130.00| | |
| | 3138055|https://www.airbn...|Classic Home on C...|2020-01-17| t|$130.00| | |
| | 3138055|https://www.airbn...|Classic Home on C...|2020-01-18| t|$130.00| | |
| | 3138055|https://www.airbn...|Classic Home on C...|2020-01-19| t|$130.00| | |
| | 3138055|https://www.airbn...|Classic Home on C...|2020-01-24| t|$130.00| | |
| +----------+--------------------+--------------------+----------+---------+-------+ |
위에서 사용한 쿼리 예제에서는 LISTING_META (Product Meta) 와 LISTING_CALENDAR (Product Meta) 테이블을 조인했습니다.
Product Meta + Product Event (Transaction, Calendar, Activity) 조합은 앞으로 여러분들이 굉장히 많이 사용할 데이터 결합 패턴입니다.
- 상품의 속성은 일반적으로 별도 테이블로 존재하고 상품 이벤트에 비해 비교적 적은 Row 로 구성되어 있습니다
- 상품의 이벤트는 일반적으로 상품 메타에 비해 데이터 사이즈가 매우 큽니다
- 예를 들어, 상품은 1개여도 해당 상품에 대한 주문은 여러번 발생할 수 있습니다
- 도메인에 따라 상품 메타가 더 자세히 나뉘기도 합니다
- 커머스의 경우에는 상품 > 상품 옵션일수도 있습니다
- 여행의 경우에는 호텔 > 룸 > 레이트 플랜 (룸 + 옵션) > 날짜 와 같이 더 복잡한 형태로 구성되기도 합니다
위와 같이 상품 이벤트에 대해 상품 메타를 붙이는 경우도 있지만 많은 경우에 상품 메타를 축으로 잡고 집계 연산을 수행할 수 있습니다. (e.g, 통계 데이터 등)
| dfListingAvailability = spark.sql(""" | |
| WITH LISTING_GROUPED AS ( | |
| SELECT | |
| listing_id, | |
| count(CASE WHEN available = 't' THEN 1 END) as count_date_available, | |
| count(CASE WHEN available <> 't' THEN 1 END) as count_date_unavailable | |
| FROM LISTING_CALENDAR | |
| GROUP BY listing_id | |
| ) | |
| SELECT | |
| LISTING_META.id as listing_id, | |
| LISTING_META.listing_url as listing_url, | |
| LISTING_META.name as listing_name, | |
| LISTING_META.review_scores_rating as review_scores_rating, | |
| LISTING_META.price as listing_price_basic, | |
| coalesce(LISTING_GROUPED.count_date_available, 0) as count_date_available, | |
| coalesce(LISTING_GROUPED.count_date_unavailable, 0) as count_date_unavailable | |
| FROM LISTING_META | |
| LEFT JOIN LISTING_GROUPED | |
| ON LISTING_META.id = LISTING_GROUPED.listing_id | |
| """) |
| # dfListingAvailability.orderBy(desc("count_date_unavailable")).show() | |
| +----------+--------------------+--------------------+--------------------+-------------------+--------------------+----------------------+ | |
| |listing_id| listing_url| listing_name|review_scores_rating|listing_price_basic|count_date_available|count_date_unavailable| | |
| +----------+--------------------+--------------------+--------------------+-------------------+--------------------+----------------------+ | |
| | 19699920|https://www.airbn...|One bedroom in an...| 97| $80.00| 0| 366| | |
| | 23418604|https://www.airbn...|Bright & Cozy Apt...| 100| $115.00| 0| 366| | |
| | 24306031|https://www.airbn...|Historic Duplex L...| null| $88.00| 0| 366| | |
| | 37912396|https://www.airbn...|Happy Travelers W...| 100| $75.00| 0| 366| | |
| | 19154631|https://www.airbn...|Newly Remodeled H...| 100| $175.00| 0| 366| | |
| | 11533087|https://www.airbn...|Beautiful Home by...| 96| $225.00| 0| 366| | |
| | 18503556|https://www.airbn...|Spacious Studio i...| 100| $119.00| 0| 366| | |
| | 20425070|https://www.airbn...|Location, locatio...| 91| $150.00| 0| 366| | |
| | 39309393|https://www.airbn...|Guest suite Denve...| null| $80.00| 0| 366| | |
| | 14154970|https://www.airbn...|Best Location! Gr...| 99| $229.00| 0| 366| | |
| | 27332948|https://www.airbn...|Cozy Modern Bedro...| 100| $48.00| 0| 366| | |
| | 12172692|https://www.airbn...|Open, bright, mou...| 93| $145.00| 0| 366| | |
| | 32017055|https://www.airbn...|⭐️ Private & Cent...| 99| $49.00| 0| 366| | |
| | 27422441|https://www.airbn...|Friendliest Place...| 100| $101.00| 0| 365| | |
| | 27759634|https://www.airbn...|Cozy Room in Down...| 100| $55.00| 0| 365| | |
| | 19752351|https://www.airbn...|Beautiful townhom...| null| $150.00| 0| 365| | |
| | 27259874|https://www.airbn...|Shared Denver Hou...| 87| $77.00| 0| 365| | |
| | 36149907|https://www.airbn...| The Nest 2.0| 100| $90.00| 0| 365| | |
| | 11509014|https://www.airbn...|Garden Suite - Bo...| 100| $80.00| 0| 365| | |
| | 21781844|https://www.airbn...| Beats Motel| null| $30.00| 0| 365| | |
| +----------+--------------------+--------------------+--------------------+-------------------+--------------------+----------------------+ |
상품 메타 (LISTING_META) 가 기준이 되는 테이블이고, 상품 이벤트 (LISTING_CALENDAR) 를 요약해서 LEFT JOIN 을 수행했습니다.
- 다만 이 때, 상품 이벤트가 존재하지 않을 수 있으므로 (주문이 없거나 누락 등) coalesce 함수를 이용해서 NULL 값이 나오지 않도록 합니다
- 위의 예제와 같이 만약 0 값이 비즈니스적으로 어떤 의미를 가진다면 coalesce 를 사용하지 않고 0 대신 NULL 을 사용할수도 있습니다
- LISTING_CALENDAR 는 listing_id 당 중복되는 ‘date’ 가 없다고 가정합니다. 만약 중복이 있다면 distinct 를 사용하거나 중복이 없는 상품 메타 단위로 더 세분화 해 집계할 수 있습니다
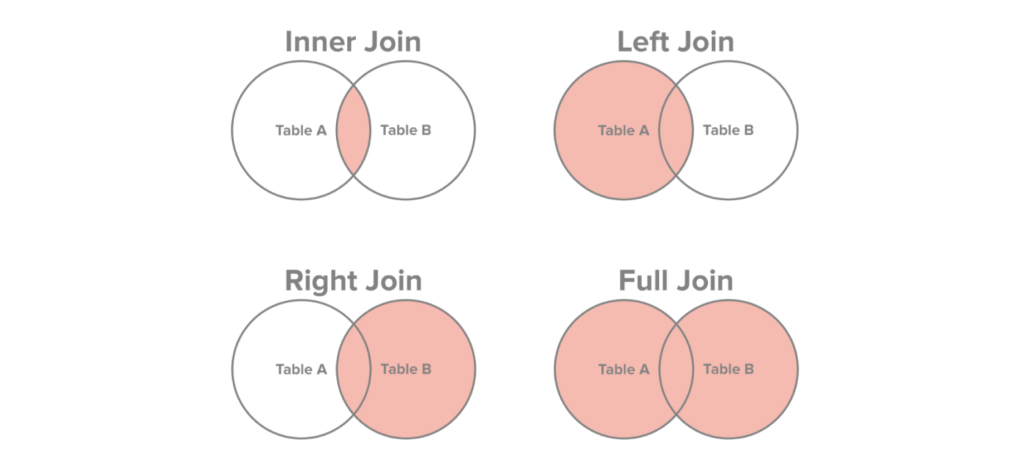
통계 등을 위한 조인 및 집계 관련해서는 추후에 다른 챕터에서 더 설명하도록 하겠습니다. 아래 그림을 통해 JOIN 종류에 따른 결과를 시각적으로 볼 수 있습니다.
이제 LISTING_AVAILABILITY 를 View 로 등록하고 review_scores_rating > 0 인 경우에만 LISTING_STAT View 로 만든 뒤 CACHE TABLE 구문을 이용해 캐싱해보겠습니다.
| spark.sql(""" | |
| CACHE TABLE LISTING_STAT AS ( | |
| SELECT * | |
| FROM LISTING_AVAILABILITY | |
| WHERE review_scores_rating IS NOT NULL | |
| ) | |
| """) | |
| spark.sql("SHOW TABLES").show() |
| +--------+--------------------+-----------+ | |
| |database| tableName|isTemporary| | |
| +--------+--------------------+-----------+ | |
| | |listing_availability| true| | |
| | | listing_calendar| true| | |
| | | listing_meta| true| | |
| | | listing_stat| true| | |
| +--------+--------------------+-----------+ |
위의 예제에서는 spark.sql 을 이용해 현재 생성된 View (임시 테이블) 을 목록을 확인했습니다. Spark Catalog API 를 이용해서도 가능합니다. Catalog API 는 테이블 생성 / 조회 등 Metastore 관련된 함수들을 제공합니다.
| # spark.catalog.listTables().show() | |
| [Table(name='listing_availability', database=None, description=None, tableType='TEMPORARY', isTemporary=True), | |
| Table(name='listing_calendar', database=None, description=None, tableType='TEMPORARY', isTemporary=True), | |
| Table(name='listing_meta', database=None, description=None, tableType='TEMPORARY', isTemporary=True), | |
| Table(name='listing_stat', database=None, description=None, tableType='TEMPORARY', isTemporary=True)] |
지금까지의 예제에서는 DataFrame.createOrReplaceTempVeiw() 를 사용해서 View 를 만들었지만 CREATE VIEW 구문을 이용하면 위의 CACHE TABLE AS (…) 과 같이 SQL 쿼리를 이용해서 View 를 생성하는것도 가능합니다.
Spark SQL 과 Spark DataFrame API 는 많은 경우에 혼용이 가능합니다. 그렇다면 언제 어떤 API 를 사용하는 것이 맞을까요? 다음의 경우를 생각해 봅시다.
- SQL 에 익숙한 분석가가 Spark 를 사용하는 경우
- 클래스와 함수를 사용하는데 익숙한 엔지니어가 Spark 를 사용하는 경우
그리고, 다루는 사람의 역할이 아니라 생산성과 사용성 관점에서 Spark SQL 과 DataFrame API 가 가지는 장점에 대해서도 이야기 해봅시다.
- 만약 둘 다 섞어서 사용한다면, 어느 부분에 어떤 API 를 사용하는것이 이점이 있을까요?
Metastore Concept
Spark 는 Metastore 와 같이 사용하는 경우가 많습니다. 이번 섹션에서는 Metastore 의 기본적인 개념에 대해 알아봅니다.
Metastore 의 종류와 다양한 기능에 대해서는 추후에 Case Study 챕터에서 알아보겠습니다.Metastore 를 통해 사용자는 데이터의 구체적인 위치를 몰라도 ‘Table’ 명을 이용해 데이터를 사용할 수 있습니다.
만약 데이터를 사용하기 위해 데이터의 물리적인 위치를 알아야 한다면 어떨까요? SELECT * FROM ODON_META 처럼 테이블의 ‘이름’ 만 지정하면 되는 것이 아니라 위치를 지정해야 합니다.
spark.read.parquet("s3://udon-data-lake/db/udon_meta/2021/11/15")- 이 때 만약 위치가 변경되면 어떻게 할까요?, 기존에 존재하던 모든 사용자의 코드를 변경해야 할까요?
- 아니면 PROPERTY_META 의 위치를 알려주는 라이브러리나 API 를 만들고 모든 사용자가 그 규약을 따르도록 강제해야 할까요?
해당 데이터가 일별로 ‘전체’ 적재가되면 (Snapshot Table)
spark.read.parquet("s3://udon-data-lake/db/udon_topping_sales/2021/11/15")spark.where(col("created_at") > ...)조건으로 필터링 할 수 있습니다.
그러나 만약 일별 생성된 Row 만 가져온다거나 CDC 처럼 ‘부분’ 만 적재가 되면 (Delta Table) 범위를 읽어야 합니다.
prefix = "s3://udon-data-lake/db/udon_topping_sales"files = [ f"{prefix}/2021/10/16", ... f"{prefix}/2021/11/15", ]spark.read.parquet(files)
만약 ‘누군가’가
- 2021년 10월 16일의 해당 테이블 데이터는 s3://udon-data-lake/db/udon_topping_sales/2021/10/16″ 위치에 있고
- 미래에 그 위치가 변해도 “내가 알려줄거야” 라고 말한다면 어떨까요?
그 시스템이 바로 메타스토어 입니다. (메타 정보를 저장하고 있는 시스템)
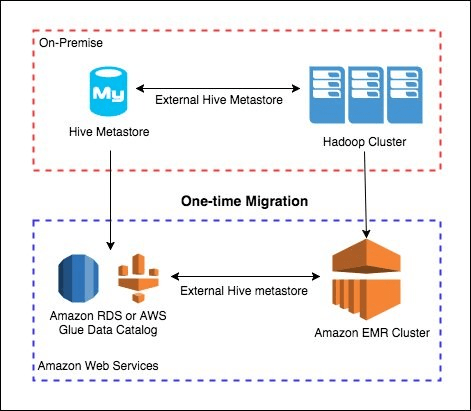
Hive Metastore 는 Spark 와 자주 같이 쓰이곤 합니다. 아래 스크린샷은 Spark 에서 Hive Metastore 를 통해 RDS (MySQL 등) 에 있는 Table 및 Partition 의 정보를 읽어 S3 의 위치를 찾아 낸 뒤 Spark 를 통해 읽는 경우를 보여줍니다. 즉, Metastore 는 테이블의 실제 데이터인 ‘파일’ 이 어디에 있는지만 저장하지 파일을 저장하진 않습니다.

아래 그림에서는 On-Prem 에서 Hadoop / Hive Metastore 에 대응되는 AWS 의 서비스를 보여줍니다.
- Hadoop Cluster 는 Computing (Yarn) + Storage (HDFS) 으로 구성되는데
- AWS 사용시 Storage (HDFS) 는 S3 로 대체하거나 EMR 내의 Core 노드로 HDFS 를 운영이 가능합니다
- AWS 사용시 Computing 은 EMR 의 Core (AM) + Task 노드로 대체가 가능합니다
- AWS 사용시 Metastore 는 EMR 에서 Hive 를 선택해 이용하거나 아니면 AWS Glue Catalog 를 이용할 수도 있습니다.
- AWS Glue Catalog 는 Hive Metastore 와 비슷한 관리형 메타스토어 서비스입니다.
Metastore 서비스에 Database, Table, Partition 에 대한 정보를 넣게 되면 수 많은 시스템에서 데이터를 조회하는데 사용할 수 있습니다. 아래 그림은 Hive Metastore 를 통해 Presto, Spark SQL 등에서 S3 는 물론 다양한 Storage 로 접근하는 사례를 보여줍니다.
- Hive JDBC Storage Handler (STORED BY ‘org.apache.hive.storage.jdbc.JdbcStorageHandler’)
- Hive ElasticSearch Storage Handler (STORED BY ‘org.elasticsearch.hadoop.hive.EsStorageHandler’)
- Hive DynamoDB Storage Handler (STORED BY ‘org.apache.hadoop.hive.dynamodb.DynamoDBStorageHandler’)

모든것을 Hive Metastore 에 등록할 필요는 없습니다.
- 모든 시스템이 Hive Metastore 와 통합되는것은 아니며
- 필요할 경우 Retool / Redash 등 UI 도구에서 저장소를 직접 등록해 조회할 수 있습니다.
- Presto 와 같은 범용 쿼리 엔진은 다양한 Connector 를 통해 여러 저장소를 직접 조회할 수 있습니다.
그러나 일반적으로 SQL 을 사용하는 컴퓨팅 엔진들 (Spark, Flink, Presto 등) 은 Hive Metastore 에 붙어 Metastore 의 서비스 이점을 누릴 수 있도록 지원합니다.
Metastore 의 Provisioning 은 AWS / GCP 와 같은 클라우드를 쓴다면 어렵지 않습니다.
- AWS 에서는 EMR 을 통해 Hive Metastore 서비스를 쉽게 띄울 수 있고 RDB 로 RDS 나 Aurora 를 사용할 수 있습니다.
- AWS EMR 내의 Hive Metastore 대신 AWS 관리형 메타스토어인 AWS Glue Catalog 를 사용할 수 있습니다.
- GCP 를 사용한다면 Serverless Hive Metastore 인 Dataproc Metastore 를 이용할 수 있습니다
대부분의 기업들은 Spark 이외에도 Presto 와 같은 범용 쿼리 엔진을 운영합니다. 모든 사용자가 Spark 를 사용할 수 있는것은 아니기 때문입니다. 따라서 Hive Metastore 도 같이 운용되고 있습니다.

Hive Metastore 부분을 조금 더 살펴보면, 위 스크린샷과 같이 크게 3가지 운영 형태로 나눌 수 있습니다
- Spark 는 아무런 설정을 하지 않을 경우 Embedded Metastore 로 동작합니다.
- 노트북 등에서 로컬 환경 테스팅용으로 사용할 수 있습니다.
- 만약 외부에 HMS 가 없고, Spark 에서 Embded Metastore 모드를 이용하되 RDB 만 외부 것을 이용하고 싶다면 Local Metastore 모드로 사용할 수 있습니다
- 공유되는 HMS 가 없어 운영 등 노동 투입의 여지가 적으나, Production 에는 권장되지 않습니다.
- EMR 등에 이미 떠 있는 HMS (Hive Metastore Service) 값을 spark/conf/hive-site.xml 내에
hive.metastore.uris프로퍼티로 세팅하면 Remote Metastore 모드로 동작합니다.- 대부분의 Production 환경에서는 Remote Metastore 형태로 사용합니다. HMS 를 별도로 운영하고, Spark Client 들이 접속해 사용합니다.
| # spark/conf/hive-site.xml | |
| # Remote Hive Metastore 연결을 위한 Spark 설정 | |
| <configuration> | |
| <property> | |
| <name>hive.metastore.uris</name> | |
| <value>thrift://hive-metastore-prod.udon.io:9083</value> | |
| <description>JDBC connect string for a JDBC metastore</description> | |
| </property> | |
| </configuration> |
| # spark/conf/hive-site.xml | |
| # Local Hive Metastore 사용을 위한 외부 RDB 연결 설정 | |
| <configuration> | |
| <property> | |
| <name>javax.jdo.option.ConnectionURL</name> | |
| <value>jdbc:mysql://localhost/metastore_db?createDatabaseIfNotExist=true</value> | |
| <description>metadata is stored in a MySQL server</description> | |
| </property> | |
| <property> | |
| <name>javax.jdo.option.ConnectionDriverName</name> | |
| <value>com.mysql.jdbc.Driver</value> | |
| <description>MySQL JDBC driver class</description> | |
| </property> | |
| <property> | |
| <name>javax.jdo.option.ConnectionUserName</name> | |
| <value>USER</value> | |
| <description>user name for connecting to mysql server </description> | |
| </property> | |
| <property> | |
| <name>javax.jdo.option.ConnectionPassword</name> | |
| <value>PASSWORD</value> | |
| <description>password for connecting to mysql server </description> | |
| </property> | |
| </configuration> |
만약 Hive Metastore 대신 Glue Catalog 를 Spark 의 Metastore 로 사용한다면, 다음 문서의 가이드를 따라 각종 컴퓨팅 프레임워크의 메타스토어로 Glue 를 설정할 수 있습니다.
- EMR Spark SQL 의 Metastore 로 Glue 사용하기
- EMR Presto 의 Metastore 로 Glue 사용하기
- Iceberg 의 Catalog 로 Glue 사용하기
Table in Hive Metastore
이제 Metastore 에 대해 알아보았으니, Metastore 에 저장될 테이블을 생성해보겠습니다. 이 섹션에서는 Hive Metastore 를 사용합니다. 사용자 실습 환경에 따라 EMR 처럼 Remote External Hive Metatore 거나 로컬 내의 Embedded 된 HMS 일 수 있습니다. 시작 전에 한가지 이야기 하고 넘어가야 할 것은 지금까지 createOrReplaceTempView() 함수를 통해 생성했던 (Temporary) View 는 Table 이 아닙니다.
- View 는 논리적인 구조로서, 물리적으로 저장되어 있지 않아 사용할 때마다 쿼리나 Transformation 을 실행해 사용해야 합니다.
- 반면 Table 의 데이터는 CSV, JSON, Parquet 등 물리적으로 존재하는 데이터로서 읽어서 바로 사용할 수 있습니다.
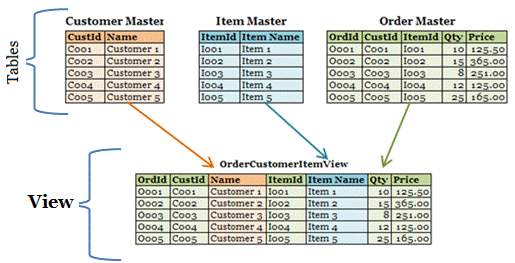
Spark 는 다음의 Table / View 를 지원합니다. 전역 여부 및 관리 여부에 따라 구분되는데, 각각은 어떻게 다를까요?
- Session-local Temporary View (Temporary Table)
- Global Temporary View (CREATE GLOBAL TEMPORARY VIEW)
- Global Permanent View (CREATE GLOBAL VIEW)
- Global Managed Table
- Global External (Unmanaged) Table
Hive 에서 Table 은 크게 2가지 종류로 나눌 수 있습니다. Hive 이야기를 하는 이유는, Spark 가 Hive Metastore 를 사용해 테이블을 생성하고 읽기 때문입니다.
- Managed Table 은 Hive 테이블과 데이터가 같이 관리됩니다. 즉 테이블을 삭제하면 데이터도 같이 삭제됩니다.
- External (Unmanaged) Table 은 테이블과 데이터의 Life-cycle 이 분리되어 있습니다. 테이블을 삭제하면, ‘스키마’ 인 테이블만 삭제되며 데이터는 그대로 존재합니다.
만약 여러분이 사용하는 Spark Session 이 Hive Metastore 에 연결되어있다면 SPARK SQL 의 DESCRIBE FORMATTED {TABLE} 쿼리를 통해 테이블의 타입을 볼 수 있습니다.
| spark.sql("DESCRIBE TABLE FORMATTED UDON_TOPPING_SALES")\ | |
| .where(col("col_name") == "Type").show() | |
| +--------+---------+-------+ | |
| |col_name|data_type|comment| | |
| +--------+---------+-------+ | |
| | Type| EXTERNAL| | | |
| +--------+---------+-------+ |
Managed / External 테이블별로 Hive 가 지원하는 기능이 조금은 다릅니다. Hive Confluence 에서 자세히 살펴 볼 수 있습니다.
일반적으로는 Hive External 테이블을 다음의 이유로 많이 사용합니다.
- External 테이블을 사용하면 실수로 사용자가 테이블 삭제시에도 데이터가 보존되며
- 많은 경우에 테이블과 데이터의 Life-cycle 은 다르기 때문에 같이 삭제할 필요가 없기 때문입니다
만약 데이터를 더이상 사용하지 않는다면, External 테이블의 ‘스키마’ 만 삭제하고 데이터는 보관처리 할 수 있습니다.
- S3 를 이용한다면 S3 Storage Class 를 이용해 테이블은 삭제하고 데이터 전체를 살려둔 채 저비용 스토리지로 내려 보관처리 하거나
- 아니면 테이블은 그대로 살려두고 특정 기간동안의 데이터 (2020.01.01 ~ 2020.12.31 등 잘 사용되지 않는 과거 파티션) 만 저비용 스토리지로 내릴 수 있습니다.
S3 의 데이터를 Glacier 등 저비용 스토리지 클래스로 변경 및 복원시에는 일부 시간이 소요될 수 있습니다. 따라서 당장 복구해야 하는 경우가 생길 수 있다면, Glacier 보다는 높은 비용의 스토리지 클래스 사용이 권장됩니다.
Hive Managed Table 사용시 데이터는 외부에 테이블 스키마와 별도로 존재하는 것이 아니라 테이블과 같이 ‘관리’ 됩니다. Hive 옵션인 (hive-site.xml) hive.metastore.warehouse.dir 위치에 데이터가 존재하게 됩니다.
- 만약 Spark 2.0+ 를 사용한다면, 이 옵션은 deprecated 되었고 대신 spark.sql.warehouse.dir 을 사용합니다.
아래의 두 가지 경우 모두 AWS EMR 을 이용한다면 Core 노드의 HDFS 에 기본으로 저장됩니다.
- spark.sql.warehouse.dir (Spark 에서 Hive Metastore 를 이용해 Managed 테이블 생성시)
- hive.metastore.warehouse.dir (Hive CLI 등 Hive 에서 직접 Managed 테이블 생성시)
그러나 EMR 종료시 HDFS 의 데이터는 전부 날아가므로 주의가 필요합니다. AWS 환경에서는 EMR 을 사용하더라도 HDFS 대신 S3 를 사용하는 편입니다.
Spark and Hive Tables
Spark SQL 는 크게 3가지 방법으로 ‘CREATE TABLE’ 을 이용해 테이블을 생성할 수 있습니다
테이블을 생성하기 위해 Catalog API 를 사용한다면 createTable() 을 이용할 수 있습니다.
- 만약 DataFrame API 를 사용한다면 saveAsTable() 을 사용해 테이블을 만들 수 있습니다. (테이블이 없는 경우)
- saveAsTable() 은 mode = Overwrite 의 경우에는 현재 스키마를 무시합니다.
- Catalog.createTable(), DataFrame.saveAsTable() 모두 파일의 경로 (LOCATION) 가 없을때는 Managed 테이블이 생성됩니다 (spark.sql.warehouse.dir)
- DataFrame.insertInto() 는 DataFrame.saveAsTable 과는 달리 컬럼의 이름이 아니라 포지션을 이용해 데이터를 적재하므로, 사용하지 않는 편이 낫습니다.
참고로 Data Source 를 이용한 테이블 생성은 Spark 2.1 미만에서는 Hive 테이블 생성과는 다르게 동작할 수 있습니다.
From Spark 2.1, Datasource tables now store partition metadata in the Hive metastore. This means that Hive DDLs such as ALTER TABLE PARTITION … SET LOCATION are now available for tables created with the Datasource API.
또한 Spark 2.0+ 부터는 에서 LOCATION 을 지정해 테이블을 생성하는 모든 경우에는 EXTERNAL 테이블을 생성합니다. Spark 에서는 LOCATION 을 지정해서 Managed Table 을 생성할 수 없습니다.
From Spark 2.0, CREATE TABLE … LOCATION is equivalent to CREATE EXTERNAL TABLE … LOCATION in order to prevent accidental dropping the existing data in the user-provided locations. That means, a Hive table created in Spark SQL with the user-specified location is always a Hive external table. Dropping external tables will not remove the data. Users are not allowed to specify the location for Hive managed tables. Note that this is different from the Hive behavior.
마지막으로 CREATE TABLE (HIVE FORMAT) 이용해서 생성시 테이블에 TBLPROPERTIES ('spark.sql.sources.provider' = 'PARQUET') 들어가지 않아, S3 Path 오류가 발생할 수 있습니다. (Spark 에서는 spark.sql 로 시작하는 TBLPROPERTIES 를 사용자가 직접 세팅 불가)
위에서서 살펴 보았듯이 테이블을 생성하기 위한 다양한 방법이 존재합니다. 또한 API 마다의 특징과 Spark, Hadoop 버전에 따른 호환성 및 각종 이슈가 존재하므로 이 섹션에서는 범용적인 방법에 대해서 다룹니다.
어떤 방법을 이용해 Hive Table 을 생성하는 편이 나을까요? Catalog API 나 DataFrame API 를 이용할 수도 있겠지만, Spark 를 이용해 만든 Hive Metastore 의 테이블이 Presto 등 다양한 곳에서 읽힐 수 있다는 점을 고려해보면,
- Spark DataFrame 에서 자동 변환되는 타입이 아니라 사용자가 정의한 타입이 명시된 Hive DDL 을 실행하는 편이 더 나을 수 있습니다
- 테이블은 Spark Batch Job 이 아니라 외부에서 DDL 등을 이용해 직접 생성하고, Batch Job 은 데이터만 적재하는 경우도 많습니다
만약 문제 발생시 DDL 을 다시 실행해야 할때, 데이터 적재가 포함된 Spark Batch Job (Application) 을 별도로 실행해야 한다는건 부담스럽습니다.DDL 을 별도로 관리하고 있다면, Jupyter 에서 Spark SQL 로 혹은 Hive CLI 에서 DDL 을 바로 실행할 수 있습니다.
CREATE DATABASE 구문과 CREATE TABLE (Hive Format) 구문을 이용해 데이터베이스와 External 테이블을 생성해보겠습니다. 아래는 몇 가지 주의사항입니다.
- Hive Data Types 문서에서 Hive 가 지원하는 타입에 대해 볼 수 있습니다.
- 만약 Hive 테이블을 Parquet 포맷으로 Spark 로 만들되, Presto 등 다른 엔진에서 사용한다면 Presto Data Types 등 해당 엔진에서 지원하는 타입과도 호환되는지 확인이 필요합니다.
- Parquet Supported Data Types
실행 전 해당 S3 버켓이 존재하는지, 그리고 해당 버켓에 권한이 있는지 확인한 후 아래의 코드를 실행합니다.
| spark.sql(""" | |
| CREATE DATABASE IF NOT EXISTS udon_db | |
| COMMENT 'Udon DB' LOCATION 's3://udon-data-lake/db' | |
| """) | |
| spark.sql(""" | |
| CREATE TABLE IF NOT EXISTS udon_db.udon_topping_sales ( | |
| udon_topping_id BIGINT, | |
| udon_topping_name STRING, | |
| sales_price DOUBLE, | |
| shipping_date DATE, | |
| created_at TIMESTAMP | |
| ) | |
| USING PARQUET | |
| LOCATION 's3://udon-data-lake/db/udon_topping_sales' | |
| COMMENT 'Udon Topping Sales' | |
| """) |
| # DESCRIBE DATABASE udon_db; | |
| +----------+----------+-------------------------------+-------------+-------------+-------------+ | |
| | db_name | comment | location | owner_name | owner_type | parameters | | |
| +----------+----------+-------------------------------+-------------+-------------+-------------+ | |
| | udon_db | Udon DB | s3://udon-data-lake/db | hadoop | USER | | | |
| +----------+----------+-------------------------------+-------------+-------------+-------------+ | |
| # USE udon_db; | |
| # SHOW TABLES; | |
| +---------------------+ | |
| | tab_name | | |
| +---------------------+ | |
| | udon_topping_sales | | |
| +---------------------+ | |
| # DESCRIBE FORMATTED udon_topping_sales; | |
| +-------------------------------+----------------------------------------------------+----------------------------------------------------+ | |
| | col_name | data_type | comment | | |
| +-------------------------------+----------------------------------------------------+----------------------------------------------------+ | |
| | # col_name | data_type | comment | | |
| | | NULL | NULL | | |
| | udon_topping_id | bigint | | | |
| | udon_topping_name | string | | | |
| | sales_price | double | | | |
| | shipping_date | date | | | |
| | created_at | timestamp | | | |
| | | NULL | NULL | | |
| | # Detailed Table Information | NULL | NULL | | |
| | Database: | udon_db | NULL | | |
| | Owner: | hadoop | NULL | | |
| | CreateTime: | Sat Sep 06 09:00:00 KST 2021 | NULL | | |
| | LastAccessTime: | UNKNOWN | NULL | | |
| | Retention: | 0 | NULL | | |
| | Location: | s3://udon-data-lake/db/udon_topping_sales | NULL | | |
| | Table Type: | EXTERNAL_TABLE | NULL | | |
| | Table Parameters: | NULL | NULL | | |
| | | EXTERNAL | TRUE | | |
| | | comment | Udon Topping Sales | | |
| | | spark.sql.create.version | 3.1.2 | | |
| | | spark.sql.sources.provider | PARQUET | | |
| | | spark.sql.sources.schema.numParts | 1 | | |
| | | spark.sql.sources.schema.part.0 | {\"type\":\"struct\",\"fields\":[{\"name\":\"udon_topping_id\",\"type\":\"long\",\"nullable\":true,\"metadata\":{}},{\"name\":\"udon_topping_name\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"sales_price\",\"type\":\"double\",\"nullable\":true,\"metadata\":{}},{\"name\":\"shipping_date\",\"type\":\"date\",\"nullable\":true,\"metadata\":{}},{\"name\":\"created_at\",\"type\":\"timestamp\",\"nullable\":true,\"metadata\":{}}]} | | |
| | | transient_lastDdlTime | 1636125473 | | |
| | | NULL | NULL | | |
| | # Storage Information | NULL | NULL | | |
| | SerDe Library: | org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe | NULL | | |
| | InputFormat: | org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat | NULL | | |
| | OutputFormat: | org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat | NULL | | |
| | Compressed: | No | NULL | | |
| | Num Buckets: | -1 | NULL | | |
| | Bucket Columns: | [] | NULL | | |
| | Sort Columns: | [] | NULL | | |
| | Storage Desc Params: | NULL | NULL | | |
| | | path | s3://udon-data-lake/db/udon_topping_sales | | |
| | | serialization.format | 1 | | |
| +-------------------------------+----------------------------------------------------+----------------------------------------------------+ |
위의 CREATE TABLE (Data Source) DDL 예제에서는 저장 형식으로 많이 사용되는 Columnar Format 인 Parquet 를 사용했습니다. 그런데 Spark 에서 Parquet 파일을 Hive 테이블로 만들때 주의사항이 몇 가지 있습니다.
- Hive Metastore 에서 Parquet 포맷의 테이블을 읽거나, 파티션이 없는 Hive Metastore Parquet 테이블을 Write 할때
- Hive SerDe 대신 Spark 자체의 Parquet 포맷 변환 기능을 사용합니다.
- spark.sql.hive.convertMetastoreParquet 옵션을 통해 조절할 수 있습니다 (default = true)
- EMRFS S3-optimized Commiter 의 경우에도 spark.sql.hive.convertMetastoreParquet 옵션이 활성화 되어 있어야 합니다.
- Hive 는 테이블과 컬럼에 소문자만 허용하지만, Parquet 는 대소문자를 모두 허용하되 구분 합니다.
- spark.sql.hive.caseSensitiveInferenceMode 옵션을 통해 조절할 수 있습니다 (default = INFER_AND_SAVE)
- Hive 는 모든 컬럼에 NULL 을 허용하지만 (구분 안함), Parquet 는 nullable / non-nullable 구분이 중요합니다.
- 만약 Parquet 에만 존재하는 컬럼이 있다면 삭제 되고 / Hive 에만 있는 컬럼이 있다면 nullable 컬럼으로 유지 됩니다. 여기서 삭제 및 유지의 의미는 Spark SQL 을 이용해 처리할때를 말합니다. (Reconcil)
따라서
- Spark, Hive, Parquet 및 사내에서 사용하는 범용 쿼리 엔진 (Presto 등) 을 모두 고려해 타입과 컬럼이름을 맞추고
- Parquet 저장시에는 각 타입이 nullable 되도록 허용하는 편이 호환성 측면에서 다루기 편합니다
Database 와 Table 을 만드는 방법을 알아보았으니, 아까 작업했던 dfListingAvailability 를 위한 테이블을 만들고 적재해보겠습니다. 우선 그 전에 테이블에 맞추어 DataFrame 가공을 조금해보겠습니다.
| dfListingAvailabilityFinal = dfListingAvailability\ | |
| .withColumn("listing_id", col("listing_id").cast(LongType()))\ | |
| .withColumn("review_scores_rating", col("review_scores_rating").cast(LongType()))\ | |
| .withColumn("listing_price_basic", regexp_extract(col("listing_price_basic"), "[0-9]+.[0-9]+", 0).cast(DoubleType())) | |
| dfListingAvailabilityFinal.printSchema() | |
| dfListingAvailabilityFinal.show() | |
| dfListingAvailabilityFinal.printSchema() | |
| dfListingAvailabilityFinal.show() |
| root | |
| |-- listing_id: long (nullable = true) | |
| |-- listing_url: string (nullable = true) | |
| |-- listing_name: string (nullable = true) | |
| |-- review_scores_rating: long (nullable = true) | |
| |-- listing_price_basic: double (nullable = true) | |
| |-- count_date_available: long (nullable = false) | |
| |-- count_date_unavailable: long (nullable = false) | |
| +----------+--------------------+--------------------+--------------------+-------------------+--------------------+----------------------+ | |
| |listing_id| listing_url| listing_name|review_scores_rating|listing_price_basic|count_date_available|count_date_unavailable| | |
| +----------+--------------------+--------------------+--------------------+-------------------+--------------------+----------------------+ | |
| | 678602|https://www.airbn...|Great space and c...| 98| 98.0| 65| 300| | |
| | 7359292|https://www.airbn...|Downtown, Mt. Vie...| 95| 100.0| 62| 303| | |
| | 7637902|https://www.airbn...|Newly built townh...| 97| 110.0| 0| 365| | |
| | 8650761|https://www.airbn...|Family friendly h...| 100| 225.0| 7| 358| | |
| | 12336225|https://www.airbn...| JC Quarters| 98| 135.0| 239| 126| | |
| | 12871019|https://www.airbn...|Colorful Capitol ...| 97| 150.0| 0| 365| | |
| | 13041992|https://www.airbn...|Quiet, Spacious a...| 99| 75.0| 139| 226| | |
| | 13656193|https://www.airbn...|A Clean Room for ...| 99| 56.0| 67| 298| | |
| | 14672294|https://www.airbn...|Modern Space Walk...| 92| 79.0| 28| 338| | |
| | 15805779|https://www.airbn...|Sophisticated Con...| 99| 310.0| 197| 168| | |
| | 20183056|https://www.airbn...|Remodeled Home - ...| 96| 193.0| 151| 214| | |
| | 21946032|https://www.airbn...|Charming 1904 Vic...| 100| 225.0| 176| 189| | |
| | 22796161|https://www.airbn...|Sleeps 14 NEW Mod...| 95| 220.0| 291| 74| | |
| | 23006749|https://www.airbn...|North Highlands 1...| 99| 61.0| 21| 344| | |
| | 23060656|https://www.airbn...|Stylish modern ro...| 98| 51.0| 42| 323| | |
| | 24015212|https://www.airbn...|Victorian Retreat...| 100| 225.0| 142| 223| | |
| | 26326009|https://www.airbn...|2018 Luxury 3500 ...| 98| 250.0| 284| 81| | |
| | 27259874|https://www.airbn...|Shared Denver Hou...| 87| 77.0| 0| 365| | |
| | 27759634|https://www.airbn...|Cozy Room in Down...| 100| 55.0| 0| 365| | |
| | 28392632|https://www.airbn...| Lowry getaway| 98| 100.0| 147| 218| | |
| +----------+--------------------+--------------------+--------------------+-------------------+--------------------+----------------------+ |
이제 위 데이터를 위한 Table 을 만들어보겠습니다.
| spark.sql(""" | |
| CREATE TABLE IF NOT EXISTS airbnb_db.listing_availability ( | |
| listing_id BIGINT, | |
| listing_name STRING, | |
| listing_url STRING, | |
| review_scores_rating BIGINT, | |
| listing_price_basic DOUBLE, | |
| count_date_available BIGINT, | |
| count_date_unavailable BIGINT | |
| ) | |
| USING PARQUET | |
| LOCATION 's3://airbnb-data-lake/db/listing_availability'; | |
| COMMENT 'Listing Availability' | |
| """) |
데이터를 적재하기 위해 Parquet Format 으로 DataFrame.write 를 호출합니다. 아래 섹션에서 이야기 하겠지만 현재 만드는 테이블은
- 파티션이 없는
- External 테이블입니다.
| dfListingAvailabilityFinal\ | |
| .repartition(2)\ | |
| .write\ | |
| .format("parquet")\ | |
| .mode("overwrite")\ | |
| .save("s3://airbnb-data-lake/db/listing_availability") | |
| # Spark Session 시작 후 스키마가 변경될 경우 REFRESH TABLE 을 이용해 테이블 정보를 다시 받아올 수 있습니다 | |
| # spark.catalog.refreshTable("airbnb_db.listing_availability") 와 동일 | |
| spark.sql("REFRESH TABLE airbnb_db.listing_availability") | |
| spark.sql(""" | |
| SELECT * | |
| FROM airbnb_db.listing_availability | |
| """).show() |
| +----------+--------------------+--------------------+--------------------+-------------------+--------------------+----------------------+ | |
| |listing_id| listing_name| listing_url|review_scores_rating|listing_price_basic|count_date_available|count_date_unavailable| | |
| +----------+--------------------+--------------------+--------------------+-------------------+--------------------+----------------------+ | |
| | 34148056|Cute guest suite ...|https://www.airbn...| 94| 85.0| 81| 284| | |
| | 23060656|Stylish modern ro...|https://www.airbn...| 98| 51.0| 42| 323| | |
| | 29231716| Clayton House|https://www.airbn...| 100| 225.0| 334| 31| | |
| | 13041992|Quiet, Spacious a...|https://www.airbn...| 99| 75.0| 139| 226| | |
| | 32357307|Central 1 br apt+...|https://www.airbn...| null| 139.0| 67| 298| | |
| | 31057360|Brick Home in the...|https://www.airbn...| 99| 149.0| 73| 292| | |
| | 32966685|Private bedroom i...|https://www.airbn...| 100| 74.0| 72| 293| | |
| | 27759634|Cozy Room in Down...|https://www.airbn...| 100| 55.0| 0| 365| | |
| | 27259874|Shared Denver Hou...|https://www.airbn...| 87| 77.0| 0| 365| | |
| | 7637902|Newly built townh...|https://www.airbn...| 97| 110.0| 0| 365| | |
| | 28392632| Lowry getaway|https://www.airbn...| 98| 100.0| 147| 218| | |
| | 36728065|Trendy loft-style...|https://www.airbn...| 100| 115.0| 92| 273| | |
| | 39389949|Sonder | Universi...|https://www.airbn...| 100| 103.0| 297| 68| | |
| | 678602|Great space and c...|https://www.airbn...| 98| 98.0| 65| 300| | |
| | 12871019|Colorful Capitol ...|https://www.airbn...| 97| 150.0| 0| 365| | |
| | 22796161|Sleeps 14 NEW Mod...|https://www.airbn...| 95| 220.0| 291| 74| | |
| | 20183056|Remodeled Home - ...|https://www.airbn...| 96| 193.0| 151| 214| | |
| | 7600940|Bring the Whole G...|https://www.airbn...| 99| 550.0| 277| 88| | |
| | 39059472|$$University hill...|https://www.airbn...| 20| 500.0| 365| 0| | |
| | 38801773|Private Bedroom i...|https://www.airbn...| null| 79.0| 0| 365| | |
| +----------+--------------------+--------------------+--------------------+-------------------+--------------------+----------------------+ |
만약 Parquet 와 Hive 타입간 불일치로 인한 오류가 생긴다면 다음처럼 Parquet 파일만 직접 읽어 스키마를 확인해 볼 수 있습니다.
| spark.read.format("parquet")\2 .load("s3://airbnb-data-lake/db/listing_availability")\3 .printSchema() |
위에서 지정한 S3 경로 내 생성된 파일 목록을 살펴보면, repartition(2) 로 인해 2개의 Parquet 파일이 생성된 것을 볼 수 있습니다.
| aws s3 ls s3://airbnb-data-lake/db/listing_availability/ | |
| part-00000-df4761db-25ba-46e3-8d66-3d2527057e78-c000.snappy.parquet | |
| part-00001-df4761db-25ba-46e3-8d66-3d2527057e78-c000.snappy.parquet |
Partitioned Table
위에서 생성한 udon_db.udon_topping_sales 과 airbnb_db.listing_availability 의 경우 파티션이 없는 테이블입니다. 파티션을 이용해 사용자는 데이터를 논리적으로 나누고, 데이터의 조회 범위를 줄일 수 있습니다. (지금 이야기 하는 파티션은 Hive 테이블의 파티션으로, Spark 의 repartition(2) 등에서 사용하는 파티션과는 다릅니다)

파티션은 일종의 디렉토리로 생각해도 좋습니다. 데이터의 구획을 나누는 역할을 합니다. 파티션 값을 쿼리에 지정함으로써 대량의 데이터가 존재하는 테이블에서 필요한 부분만 (= 요청한 구획, 즉 요청한 파티션만) 탐색할 수 있습니다. 반대로 파티션이 없다면 원하는 데이터를 찾기 위해 전체 구획내 데이터를 하나씩 다 읽어봐야 할 수 있습니다 (= FULL SCAN)
Partitioned tables can be created using the PARTITIONED BY clause. A table can have one or more partition columns and a separate data directory is created for each distinct value combination in the partition columns. Further, tables or partitions can be bucketed using CLUSTERED BY columns, and data can be sorted within that bucket via SORT BY columns. This can improve performance on certain kinds of queries.
https://cwiki.apache.org/confluence/display/hive/languagemanual+ddl#LanguageManualDDL-PartitionedTables
아래와 같이 udon_topping_sales 라는 일별로 주문된 내역을 저장하고 있는 테이블이 있다고 가정해봅시다.
- 만약 파티션 컬럼 (
dt) 없이 일반 컬럼created_dt(Date 타입) 으로만 데이터를 탐색해야 한다면, “전체” 데이터를 다 읽으면서created_dt값을 이용해 필터링을 진행합니다. - 반면 파티션 컬럼 (
dt) 를 사용한다면, 디렉토리 (또는 Object Path in case of S3) 내의 데이터를 전혀 읽지 않아도 되므로 속도가 훨씬 빠릅니다.
| SELECT * | |
| FROM udon_db.udon_topping_sales | |
| WHERE | |
| dt BETWEEN '20211001' AND '20211031' -- Partition 필터링 (데이터를 읽지 않고 스킵) | |
| AND (created_dt >= DATE('20211001') AND created_dt <= DATE('20211031')) -- Row 필터링 (데이터를 읽어서 판별) |
파티션이 없는 테이블은 데이터 적재 관점에서도 어려움을 만듭니다.
- 만약 스냅샷 데이터 (e.g., 누적된 전체 주문건) 을 매일매일 적재해야 한다면 새로운 S3 경로에 쌓고 DDL 을 통해 Table 의 LOCATION 을 변경해야 할까요?
- 과거 시점의 스냅샷 데이터를 읽고싶다면 어떻게 해야할까요?
- 만약 Delta 데이터 (e.g., 당일 생성 주문건) 을 매일 추가로 만들어서 같은 테이블 내에서 쓰게 해야한다면 Append 해야할까요?
- File 이 temp 에 써진 후 작업 종료 이후에 대상 S3 버켓으로 옮겨지는 순간에는 데이터를 읽을 수 있을까요?
최근에는 이런 Versioning 및 Update 및 문제를 해결하기 위한 별도의 Table Format (Apache Iceberg) 이나 시스템 (Apache Hudi) 가 나오고 있습니다. Hive ACID 도 이러한 문제를 해결하는데 도움이 될 수 있지만, Limitation 이 많고 Hive (or Spark Hive Data Source) 를 통해 직접 데이터를 읽는 경우가 적습니다.

Hive 테이블의 파티션은 2 가지로 나눌 수 있습니다
- Dynamic Partition: 데이터를 보고 어떤 파티션인지 (어디에 위치할지를) 결정합니다
- 데이터를 하나씩 보면서 파티션을 결정해야 하므로 속도가 느릴 수 있습니다.
- Static Partition: 데이터를 보지 않고, 사용자가 어떤 파티션인지 (어디에 위치할지를) 직접 지정합니다.
- 일반적으로 Static Partition 을 사용합니다. 데이터를 가공하는 시점에 대부분 파티션을 알고 있기 때문입니다.
- 데이터를 보고 결정하지 않아도 되므로 Partition 값을 위한 데이터 컬럼이 필요하지 않습니다.
- “Note that you do not need to add an input column for the static partition column because its value is already known in the PARTITION clause.”
Static / Partition 관련해서는 다음의 Hive Confluence 문서를 추가적으로 참조할 수 있습니다
- https://cwiki.apache.org/confluence/display/hive/tutorial
- https://cwiki.apache.org/confluence/display/hive/dynamicpartitions
Spark 에서는 다음의 옵션을 통해 Hive 의 Dynamic Partition 을 활성화 할 수 있습니다.
| # spark-default.conf 에서 전역으로 설정하거나 | |
| # spark session 내에서 세션 범위로 설정 | |
| spark.conf.set("hive.exec.dynamic.partition", "true") | |
| spark.conf.set("hive.exec.dynamic.partition.mode", "nonstrict") |
이제 이전 섹션에서 만들어 두었던 listing_meta, listing_calendar 를 위한 Partition 테이블을 생성해보겠습니다.
| spark.sql(""" | |
| CREATE TABLE IF NOT EXISTS airbnb_db.listing_meta ( | |
| listing_id BIGINT, | |
| listing_name STRING, | |
| listing_url STRING, | |
| property_type STRING, | |
| country STRING, | |
| state STRING, | |
| city STRING, | |
| description STRING, | |
| dt STRING | |
| ) | |
| USING PARQUET | |
| PARTITIONED BY (dt) | |
| LOCATION 's3://airbnb-data-lake/db/listing_meta' | |
| COMMENT 'Airbnb Listing Meta' | |
| """) |
실행 후에 Hive CLI 나 spark.sql 로 테이블을 확인해 보면 다음과 같습니다. (Spark 버전 차이로 인해 일부 값이 다를 수 있습니다.)
| $ SHOW CREATE TABLE airbnb_db.listing_meta; | |
| +----------------------------------------------------+ | |
| | createtab_stmt | | |
| +----------------------------------------------------+ | |
| | CREATE EXTERNAL TABLE `airbnb_db.listing_meta`( | | |
| | `listing_id` bigint, | | |
| | `listing_name` string, | | |
| | `listing_url` string, | | |
| | `property_type` string, | | |
| | `country` string, | | |
| | `state` string, | | |
| | `city` string, | | |
| | `description` string) | | |
| | COMMENT 'Airbnb Listing Meta' | | |
| | PARTITIONED BY ( | | |
| | `dt` string) | | |
| | ROW FORMAT SERDE | | |
| | 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' | | |
| | WITH SERDEPROPERTIES ( | | |
| | 'path'='s3://airbnb-data-lake/db/listing_meta') | | |
| | STORED AS INPUTFORMAT | | |
| | 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat' | | |
| | OUTPUTFORMAT | | |
| | 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat' | | |
| | LOCATION | | |
| | 's3://airbnb-data-lake/db/listing_meta' | | |
| | TBLPROPERTIES ( | | |
| | 'spark.sql.create.version'='3.1.2', | | |
| | 'spark.sql.partitionProvider'='catalog', | | |
| | 'spark.sql.sources.provider'='PARQUET', | | |
| | 'spark.sql.sources.schema.numPartCols'='1', | | |
| | 'spark.sql.sources.schema.numParts'='1', | | |
| | 'spark.sql.sources.schema.part.0'='{"type":"struct","fields":[{"name":"listing_id","type":"long","nullable":true,"metadata":{}},{"name":"listing_name","type":"string","nullable":true,"metadata":{}},{"name":"listing_url","type":"string","nullable":true,"metadata":{}},{"name":"property_type","type":"string","nullable":true,"metadata":{}},{"name":"country","type":"string","nullable":true,"metadata":{}},{"name":"state","type":"string","nullable":true,"metadata":{}},{"name":"city","type":"string","nullable":true,"metadata":{}},{"name":"description","type":"string","nullable":true,"metadata":{}},{"name":"dt","type":"string","nullable":true,"metadata":{}}]}', | | |
| | 'spark.sql.sources.schema.partCol.0'='dt', | | |
| | 'transient_lastDdlTime'='1636168577') | | |
| +----------------------------------------------------+ |
airbnb_db.listing_meta 테이블에 DDL 을 이용해 파티션을 추가해보겠습니다.
| spark.sql(""" | |
| ALTER TABLE airbnb.listing_meta ADD IF NOT EXISTS PARTITION ( | |
| dt = '20211101' | |
| ) | |
| LOCATION 's3://airbnb-data-lake/db/listing_meta/dt=20211101'; | |
| """) |
만약 테이블 내의 Partition 을 보고 싶다면 SHOW PARTITIONS {TABLE} 쿼리를 통해 확인할 수 있습니다.
| $ SHOW PARTITIONS airbnb_db.listing_meta; | |
| +--------------+ | |
| | partition | | |
| +--------------+ | |
| | dt=20211101 | | |
| +--------------+ |
이제 데이터를 S3 에 Parquet 포맷으로 적재할텐데, 2가지 방법으로 나누어 진행해보겠습니다.
- listing_meta 는 SQL 의 INSERT INTO OVERWRITE 를 이용해서 데이터를 저장하고
- 만약 Overwrite 가 아니라 Append 하고 싶다면 INSERT INTO 를 사용할 수 있습니다.
PARTITION (dt = '{partitionListingMeta}')으로 직접 파티션을 지정하는 Static Partitioning 을 사용합니다.- Static Partitioning 의 경우 ‘데이터’ 를 보지 않고 사용자가 직접 파티션을 지정하므로 DataFrame 또는 입력하는 SQL 데이터 내 파티션 컬럼이 없어도 됩니다. (=
dt)
- listing_calendar 는 DataFrame 의 partitionBy() 와 saveAsTable 을 이용해서 데이터를 저장해 보겠습니다.
partitionBy로 Spark 내 DataFrame 컬럼값을 이용해 잗오으로 파티션을 지정하는 Dynamic Partitioning 을 사용합니다.- Dynamic Partitioning 의 경우 Spark 또는 Hive 가 데이터를 기반으로 파티션을 판단하므로 DataFrame 또는 SQL 데이터 내 파티션 컬럼이 존재해야 합니다 (=
dt)
| partitionListingMeta = '20211101' | |
| spark.sql(f""" | |
| INSERT OVERWRITE airbnb_db.listing_meta | |
| PARTITION (dt = '{partitionListingMeta}') | |
| SELECT | |
| CAST(id AS BIGINT) as listing_id, | |
| name as listing_name, | |
| listing_url, | |
| property_type, | |
| country, | |
| state, | |
| city, | |
| description | |
| FROM LISTING_META -- 이전 섹션에서 만든 Temporary View 입니다 | |
| """) |
이제 만든 테이블 내의 데이터를 SELECT 해 DataFrame 으로 만들고 실행 계획과 데이터를 확인해보겠습니다. PartitionFilter 를 통해 지정된 Location 의 데이터만 탐색했음을 알 수 있습니다.
| dfTableListingMeta = spark.sql(""" | |
| SELECT * | |
| FROM airbnb_db.listing_meta | |
| WHERE dt = '20211101' | |
| """) | |
| dfTableListingMeta.explain("FORMATTED") | |
| dfTableListingMeta.show() |
| == Physical Plan == | |
| * ColumnarToRow (2) | |
| +- Scan parquet airbnb_db.listing_meta (1) | |
| (1) Scan parquet airbnb_db.listing_meta | |
| Output [9]: [listing_id#110445L, listing_name#110446, listing_url#110447, property_type#110448, country#110449, state#110450, city#110451, description#110452, dt#110453] | |
| Batched: true | |
| Location: InMemoryFileIndex [s3://airbnb-data-lake/db/listing_meta/dt=20211101] | |
| PartitionFilters: [isnotnull(dt#110453), (dt#110453 = 20211101)] | |
| ReadSchema: struct<listing_id:bigint,listing_name:string,listing_url:string,property_type:string,country:string,state:string,city:string,description:string> | |
| (2) ColumnarToRow [codegen id : 1] | |
| Input [9]: [listing_id#110445L, listing_name#110446, listing_url#110447, property_type#110448, country#110449, state#110450, city#110451, description#110452, dt#110453] | |
| +----------+--------------------+--------------------+-------------+-------------+-----+---------+--------------------+--------+ | |
| |listing_id| listing_name| listing_url|property_type| country|state| city| description| dt| | |
| +----------+--------------------+--------------------+-------------+-------------+-----+---------+--------------------+--------+ | |
| | 360|LoHi Secret garde...|https://www.airbn...| Guesthouse|United States| CO| Denver|Come enjoy our oa...|20211101| | |
| | 590|Comfortable - an...|https://www.airbn...| House|United States| CO| Denver|Large guest room ...|20211101| | |
| | 592| private|https://www.airbn...| House|United States| CO| Denver|This room is in t...|20211101| | |
| | 1940|Baker Studio Clos...|https://www.airbn...| Guesthouse|United States| CO| Denver|Great place for a...|20211101| | |
| | 2086| Garden Level Condo|https://www.airbn...| Apartment|United States| CO| Denver|A furnished, gard...|20211101| | |
| | 31503|Highland Park Gue...|https://www.airbn...| Guest suite|United States| CO| Denver|Highland Park Gue...|20211101| | |
| | 39405|LoHi Secret garde...|https://www.airbn...| Cottage|United States| CO| Denver|Come enjoy our oa...|20211101| | |
| | 56185|charming home for...|https://www.airbn...| House|United States| CO| Denver|Spend time in Den...|20211101| | |
| | 59631|VICTORIAN TOWNHOM...|https://www.airbn...| Townhouse|United States| CO| Denver|License #2017-BFN...|20211101| | |
| | 74125|Spacious Cap Hill...|https://www.airbn...| Apartment|United States| CO| Denver|1000' entire-firs...|20211101| | |
| | 81540|Affordable S. Den...|https://www.airbn...| Guesthouse|United States| CO|Englewood|Bright, sunny 1 b...|20211101| | |
| | 90307|Comfy King Size R...|https://www.airbn...| House|United States| CO| Denver|This private bedr...|20211101| | |
| | 98008|Beautiful sun fil...|https://www.airbn...| House|United States| CO| Denver|Locaton, location...|20211101| | |
| | 98014|Beautiful single ...|https://www.airbn...| House|United States| CO| Denver|Hi Folks! Welcom...|20211101| | |
| | 142683|Historic Denver C...|https://www.airbn...| House|United States| CO| Denver|One of three cond...|20211101| | |
| | 172196|Luxury Wash Park ...|https://www.airbn...| House|United States| CO| Denver|Remodeled wash pa...|20211101| | |
| | 184529|HIP SUITE IN WES...|https://www.airbn...| Guest suite|United States| CO| Denver|Private SUIITE ...|20211101| | |
| | 192430|TREETOP VIEW ROOM...|https://www.airbn...| Condominium|United States| CO| Denver|Located in the de...|20211101| | |
| | 217996| Highland Snug|https://www.airbn...| Condominium|United States| CO| Denver|Comfortable and c...|20211101| | |
| | 236207|Denver Penthouse ...|https://www.airbn...| Loft|United States| CO| Denver|Important Note : ...|20211101| | |
| +----------+--------------------+--------------------+-------------+-------------+-----+---------+--------------------+--------+ |
이제 Dynamic Partition 을 이용해 listing_calendar 적재를 위해 DataFrame 의 partitionBy() 를 이용해 보겠습니다. Spark 문서에서 Generic Load / Save 함수와 Parquet 의 partition 부분을 읽어보면 사용법에 대해 쉽게 파악할 수 있습니다.
- https://spark.apache.org/docs/latest/sql-data-sources-load-save-functions.html#bucketing-sorting-and-partitioning
- https://spark.apache.org/docs/latest/sql-data-sources-parquet.html#partition-discovery
listing_calendar 테이블을 만들어 보겠습니다.
| spark.sql(""" | |
| CREATE TABLE IF NOT EXISTS airbnb_db.listing_calendar ( | |
| listing_id BIGINT, | |
| date DATE, | |
| available STRING, | |
| price DOUBLE, | |
| adjusted_price DOUBLE, | |
| minimum_nights BIGINT, | |
| maximum_nights BIGINT, | |
| dt STRING | |
| ) | |
| USING PARQUET | |
| PARTITIONED BY (dt) | |
| LOCATION 's3://airbnb-data-lake/db/airbnb_listing_calendar' | |
| COMMENT 'Airbnb Listing Calendar' | |
| """) |
그리고 Dynamic Partitioning 을 이용해 데이터를 적재 해보겠습니다. 아래 코드와 같이 사용자가 직접 어떤 파티션 값인지 (dt = 20211201) 지정하지 않고 dt 컬럼을 기반으로 자동으로 파티션을 결정합니다.
| dfListingCalendarFiltered\ | |
| .repartition(1)\ | |
| .write\ | |
| .mode("overwrite")\ | |
| .format("parquet")\ | |
| .partitionBy("dt")\ | |
| .option("path", "s3://airbnb-data-lake/db/listing_calendar")\ | |
| .saveAsTable("airbnb_db.listing_calendar") |
실행 후 S3 데이터를 조회해보면 아래와 같이 dt=yyyyMMdd 패턴으로 각 디렉토리 (엄밀히는 S3 오브젝트 경로) 마다 repartition(1) 로 인해 1개의 Parquet 파일이 생김을 볼 수 있습니다.
| $ aws s3 ls --recursive s3://airbnb-data-lake/db/listing_calendar/ | |
| airbnb-data-lake/db/listing_calendar/dt=20211001/part-00000-e87bccfe-99f3-4243-9560-5042ee861e22.c000.snappy.parquet | |
| airbnb-data-lake/db/listing_calendar/dt=20211002/part-00000-e87bccfe-99f3-4243-9560-5042ee861e22.c000.snappy.parquet | |
| ... | |
| ... | |
| airbnb-data-lake/db/listing_calendar/dt=20211101/part-00000-e87bccfe-99f3-4243-9560-5042ee861e22.c000.snappy.parquet |
그리고 직접 Partition 을 추가하지 않았지만 Hive CLI 등에서 SHOW PARTITIONS 를 실행하면 파티션이 자동으로 추가됨을 알 수 있습니다.
- 만약 DataFrame 내 dt 값이 365 개였다면, 혹은 그 이상이라면 Hive Metastore 와 S3 에 가해지는 부담은 어떻게 될까요?
- Hive DDL 이 많이 실행되고 S3 (혹은 HDFS) 에 작은 파일이 많이 생겼을때 전체 시스템에 어떤 영향을 줄지 생각해봅시다.
- 시스템 부하 관점에서 볼 때 Dynamic Partitioning 에 비해 Static Partition 은 어떤 장점을 가지고 있을까요?
| $ SHOW PARTITIONS airbnb_db.listing_calendar; | |
| +--------------+ | |
| | partition | | |
| +--------------+ | |
| | dt=20211001 | | |
| | dt=20211002 | | |
| | dt=20211003 | | |
| | dt=20211004 | | |
| | dt=20211005 | | |
| | dt=20211006 | | |
| | dt=20211007 | | |
| | dt=20211008 | | |
| | dt=20211009 | | |
| | dt=20211010 | | |
| | dt=20211011 | | |
| | dt=20211012 | | |
| | dt=20211013 | | |
| | dt=20211014 | | |
| | dt=20211015 | | |
| | dt=20211016 | | |
| | dt=20211017 | | |
| | dt=20211018 | | |
| | dt=20211019 | | |
| | dt=20211020 | | |
| | dt=20211021 | | |
| | dt=20211022 | | |
| | dt=20211023 | | |
| | dt=20211024 | | |
| | dt=20211025 | | |
| | dt=20211026 | | |
| | dt=20211027 | | |
| | dt=20211028 | | |
| | dt=20211029 | | |
| | dt=20211030 | | |
| | dt=20211031 | | |
| | dt=20211101 | | |
| +--------------+ |
listing_calendar 테이블에서 이미 존재하는 date 컬럼이 아니라 dt 컬럼을 추가해서 사용한 것을 볼 수 있습니다. 일관적인 파티션 컬럼 이름과 값 형태를 사용하는 것은 매우 중요합니다.
테이블마다 다른 파티션 컬럼명과 (dt, part, yyyymmdd, year + month + day) 값 형태를 사용한다면 사내의 수 많은 데이터 사용자들이 테이블 쿼리때 마다 파티션 컬럼과 그 값 형태를 찾아봐야하는 불편함을 겪을 수 있기 때문입니다.
파티션 자동 생성 관련해서 추가로 알아야 할 부분이 있습니다. 바로spark.sql.sources.partitionOverwriteMode 옵션입니다.
위와 같이 20211001 – 20211101 까지 32개의 Partition 이 생성된 상태에서 아래와 같이 dt = 20211101 만 필터링해 saveAsTable 을 실행하면 dt=20211101 만 제외하고 전부 삭제됩니다.
| dfListingCalendarFiltered\ | |
| .where(col("dt") == lit("20211101"))\ | |
| .repartition(1)\ | |
| .write\ | |
| .mode("overwrite")\ | |
| .format("parquet")\ | |
| .partitionBy("dt")\ | |
| .option("path", "s3://airbnb-data-lake/db/listing_calendar")\ | |
| .saveAsTable("airbnb_db.listing_calendar") |
| $ SHOW PARTITIONS airbnb_db.listing_calendar; | |
| +--------------+ | |
| | partition | | |
| +--------------+ | |
| | dt=20211101 | | |
| +--------------+ |
기존 파티션이 삭제된 이유는 sql.sources.partitionOverwriteMode = static 기본값으로 잡혀 있기 때문입니다. (파티션 뿐만 아니라 S3 내 데이터도 삭제된 걸 확인할 수 있습니다.)
- 위에서 만들었던 listing_meta (INSERT OVERWRITE PARTITION (..)) 는 static 파티션이기 때문에 문제가 없었습니다. (Partition 없을 경우에만 생성됩니다)
- 그러나 partitionBy(“dt”) 사용시에는 데이터를 기준으로 파티션이 결정되는 dynamic 파티션처럼 동작합니다. 그리고 partitionOverwriteMode = static 이 Default 이기 때문에 데이터 적재시 전체 파티션이 삭제됩니다.
- Spark Internals – Dynamo Partition Inserts
spark.sql.sources.partitionOverwriteMode 옵션은 Spark 2.3 에 추가되었습니다.
When INSERT OVERWRITE a partitioned data source table, we currently support 2 modes: static and dynamic. In static mode, Spark deletes all the partitions that match the partition specification(e.g. PARTITION(a=1,b)) in the INSERT statement, before overwriting. In dynamic mode, Spark doesn’t delete partitions ahead, and only overwrite those partitions that have data written into it at runtime. By default we use static mode to keep the same behavior of Spark prior to 2.3. Note that this config doesn’t affect Hive serde tables, as they are always overwritten with dynamic mode. This can also be set as an output option for a data source using key partitionOverwriteMode (which takes precedence over this setting), e.g. dataframe.write.option(“partitionOverwriteMode”, “dynamic”).save(path).
https://spark.apache.org/docs/latest/configuration.html#spark-sql
spark.sql.sources.partitionOverwriteMode = dynamic 으로 전체 파티션이 삭제되는 것을 막을 수 있습니다. 있으나 만약 PathOutputCommitProtocol 를 사용한다면 Hadoop 3.1+ 을 쓰는 경우에는 spark.sql.sources.partitionOverwriteMode = dynamic 이 사용 불가능합니다.
AWS EMR 과 S3 를 사용하는 경우에 S3-Optimized Commiter 로 인해 PathOutputCommitProtocol 를 선택하는 경우가 많습니다. (Spark Cloud Integration Guide)그리고 AWS EMRFS S3-Optimized Commiter 를 이용할 경우에는 spark.sql.sources.partitionOverwriteMode = static 여야 합니다 (dynamic 사용 불가)EMRFS S3-Optimized Commiter 를 이용하지 않아도 문제가 없습니다. 다만 AWS EMR / S3 를 이용할 경우에는 S3-Optimized Commiter 로 높은 쓰기 성능을 얻을 수 있습니다.
- Improves application performance by avoiding list and rename operations done in Amazon S3 during job and task commit phases.
- Avoids issues that can occur with Amazon S3 eventual consistency during job and task commit phases, and helps improve job correctness under task failure conditions.
이런 이유로 인해 일부 환경에서 (Hadoop 3.1+, PathOutputCommitProtocol) DataFrame.partitionBy().saveAsTable() 사용이 전체 파티션 삭제를 유발하므로 위에서 사용했던 ListingMeta 를 INSERT OVERWRITE INTO 로 변경해보겠습니다.
ALTER TABLE ADD PARTITION DDL을 통해 파티션을 미리 생성합니다 (미리 만들지 않아도 INSERT INTO 실행시 자동 생성됩니다. 이 섹션에서는 실습을 위해 직접 만듭니다)INSERT OVERWRITE INTO로 넣을 경우 Static 파티션 을 이용하므로 dt 컬럼이 필요 없습니다. drop() 함수를 통해 제거합니다INSERT OVERWITE INTO를 위해 현재까지 가공한 DataFrame 을 createOrReplaceView() 함수를 사용해 View 로 만듭니다INSERT OVERWRITE INTO를 실행합니다- Pandas 라이브러리를 이용해 반복문을 위한 파티션 값 (dt) 를 생성합니다. (Pandas 를 이용하지 않아도 됩니다, 여기서는 예시를 위해 사용했습니다.)
- 반복문을 돌며 dt 에 맞는 Row 만 WHERE 에서 추출하고
- Select 에 Repartition HINT 를 이용해 repartition() 을 수행합니다
순서대로 진행해보겠습니다.
| # 테스트를 위해 2일치 (2021.10.01 ~ 2021.10.02) 만 세팅 | |
| import pandas as pd | |
| partitions = pd.date_range(start='20211002',end='20211002',freq='D').strftime('%Y%m%d') | |
| # dt 컬럼 제거 및 View 등록 | |
| dfListingCalendarRefined.drop("dt").createOrReplaceTempView("LISTING_CALENDAR_RAW") | |
| # 반복문 내에서 파티션 등록 및 INSERT INTO 실행 | |
| for p in partitions: | |
| spark.sql(f""" | |
| ALTER TABLE airbnb_db.listing_calendar ADD IF NOT EXISTS PARTITION ( | |
| dt = '{p}' | |
| ) | |
| LOCATION 's3://airbnb-data-lake/db/listing_calendar/dt={p}'; | |
| """) | |
| spark.sql(f""" | |
| INSERT OVERWRITE airbnb_db.listing_calendar | |
| PARTITION (dt = '{p}') | |
| SELECT /*+ REPARTITION(2) */ * | |
| FROM LISTING_CALENDAR_RAW | |
| WHERE date = to_date('{p}', 'yyyyMMdd') | |
| """) |
위 코드를 실행하면 파티션 생성과 2일치 파티션을 위한 데이터가 적재됩니다. 데이터를 추출 해보겠습니다.
| spark.sql(""" | |
| SELECT * | |
| FROM airbnb_db.listing_calendar | |
| WHERE listing_id = 35886541 | |
| """).show() |
| +----------+----------+---------+-----+--------------+--------------+--------------+--------+ | |
| |listing_id| date|available|price|adjusted_price|minimum_nights|maximum_nights| dt| | |
| +----------+----------+---------+-----+--------------+--------------+--------------+--------+ | |
| | 35886541|2021-10-02| f| 85.0| 85.0| 1| 1125|20211002| | |
| | 35886541|2021-10-01| f| 75.0| 75.0| 1| 1125|20211001| | |
| +----------+----------+---------+-----+--------------+--------------+--------------+--------+ |
S3 데이터를 살펴보면 REPARTITION 힌트가 잘 동작해 파티션당 파일이 2개임을 확인할 수 있습니다.
| $ aws s3 ls --recursive s3://airbnb-data-lake/db/listing_calendar/dt=20211001/ | |
| airbnb-data-lake/db/listing_calendar/dt=20211001/part-00000-1b3d55a5-00e1-4153-858f-16c7425b7dc4.c000.snappy.parquet | |
| airbnb-data-lake/db/listing_calendar/dt=20211001/part-00001-1b3d55a5-00e1-4153-858f-16c7425b7dc4.c000.snappy.parquet | |
| airbnb-data-lake/db/listing_calendar/dt=20211002/part-00000-c28bb9a9-1846-4d08-9149-2c8eb58dbd67.c000.snappy.parquet | |
| airbnb-data-lake/db/listing_calendar/dt=20211002/part-00001-c28bb9a9-1846-4d08-9149-2c8eb58dbd67.c000.snappy.parquet |
만약 수동으로 파티션을 제거하고 싶다면 DROP PARTITION DDL 을 사용하면 됩니다. 여러 파티션을 삭제하고 싶을때는 다음처럼 범위 연산자를 이용할 수 있습니다.
| ALTER TABLE airbnb_db.listing_calendar DROP PARTITION (dt > '20211001'), PARTITION (yyyymmdd < '20211101'); |
DataFrame 의 partitionBy() 함수로 적재시 파티션이 자동생성된 것도 볼 수 있습니다. 파티션은 어떻게 관리하면 좋을지 이야기 해봅시다. 만약 사용자가 실수로 파티션이 없는 테이블에 대해 수많은 파티션을 자동으로 생성하게 되면 Hive Meastore 에 부하가 가 단순 읽기 작업을 하는 Spark 작업도 밀릴 수 있습니다.
- 따라서 대량 Partition 추가는 Spark 작업과는 별개로 관리하고, 필요하다면 미리 해 놓는 편이 좋습니다.
- 단건 (= 1건) Partition 추가는 Spark 작업내에서 spark.sql(“ADD PARTITION IF NOT EXISTS”) 로 관리한다면 편리하게 운영할 수 있습니다.
- 혹은 spark.sql.sources.partitionOverwriteMode = ‘dynamic’ 를 이용할 수 있으나, partitionBy() 에 파티션 생성을 맡기는 것은 데이터의 유무로 인해 불확정적이므로 Spark Job 시작 부분에서 실행되는 ADD PARTITION IF NOT EXISTS 가 나을 수 있습니다.
Practice
실습 과제입니다.
Hive Metastore 실습
Hive Metastore 는 대부분의 데이터 시스템에서 근간으로 사용되는 서비스입니다.
- AWS 의 경우에는 EMR GCP 에서는 Data Proc Metastore 을 통해 제공됩니다.
- 최근에 자주 사용되는 실시간 조회를 지원하는 Delta Lake 용 스토리지인 Hudi, Iceberg 로 가더라도 Hive Metastore 는 여전히 필수적인 요소입니다.

이 챕터에서는 Hive Metatore 에 대한 실습을 두 가지로 진행합니다.
- Spark 내장 Hive Metastore 및 Embedded Java RDB 인 Derby 를 사용해 로컬 모드에서 외부 Hive Metastore 없이 Spark 를 사용해 봅니다.
- Spark 내 conf/hive-site.xml 을 세팅해 로컬 모드에서 외부 Hive Metastore 에 연결해 Spark 를 사용해 봅니다.
Github: 1ambda/practical-data-pipeline-code 나온 Docker Compose 를 바탕으로 Embedded, Local Metastore 모드를 실습해보고 hive-site.xml 에 따라 아래의 디렉토리가 생성되는지, 그리고 어떤 내용을 담고 있는지 살펴봅시다.
- spark-warehouse
- metastore_db
- https://jaceklaskowski.gitbooks.io/mastering-spark-sql/content/spark-sql-hive-metastore.html
Summary
이번 챕터에서는 Spark SQL 에 대해 알아보았습니다. Spark SQL 은 Hive 의 SQL 문법을 포함해 많은 기능을 지원하나, 일부 기능은 지원되지 않는 경우도 있습니다.
Spark SQL 의 다른 기능들도 많으니 살펴보시기 바랍니다.
